
안녕하세요, 이번 시간에는 이분탐색을 배워보도록 하겠습니다. 사실 이분탐색의 개념 자체는 그렇게 어렵지는 않습니다. 초등학생 정도만 되어도 업다운게임같은걸 아주 재밌게 즐길 수 있고, 왜 1에서 50 사이의 수 중에서 맨 처음에 25를 불러야 하는지 대충 느낌적으로는 이해를 하고 있습니다. 그리고 가장 기본적인 형태의 이분탐색, 즉 정렬되어 있는 데이터에서 특정한 원소를 찾는 문제는 강의 중간에 소개를 하겠지만 이미 STL에 함수가 있기 때문에 직접 구현을 할 필요조차 없습니다.
그런데 이분탐색 유형은 어디서 문제가 생기는지 생각해볼 때, 아주 조금만 꼬아서 내도 문제의 난이도가 거의 저세상으로 갑니다. 그래서 응용을 하지 않은 이분탐색 문제가 나온다면 STL을 써서 쉽게 통과할 수 있는 반면 응용이 되었으면 아마 정답률 1-2%대 정도의 문제가 되어버립니다. 가장 이상적인건 꼬아서 낸 이분탐색 문제를 마주하더라도 제 강의를 통해 사실상 킬러 문제인 그런 문제들을 손쉽게 해치워서 코딩테스트를 뚜까패는거겠지만 보통 코딩테스트에서 올솔브를 요구하는건 아니어서 그런 킬러 문제들은 못푼다고 해서 당락이 바뀔 가능성이 크지는 않긴 합니다. 그렇기 때문에 이전 강의의 내용들을 잘 따라왔으면 연습 문제들을 꼼꼼하게 풀어보면서 이분탐색을 깊게 공부해보시고, 그렇지 않다면 마음을 조금 비우고 개념이랑 STL 사용법 정도만 적당히 익힌채로 넘어가도 괜찮습니다.

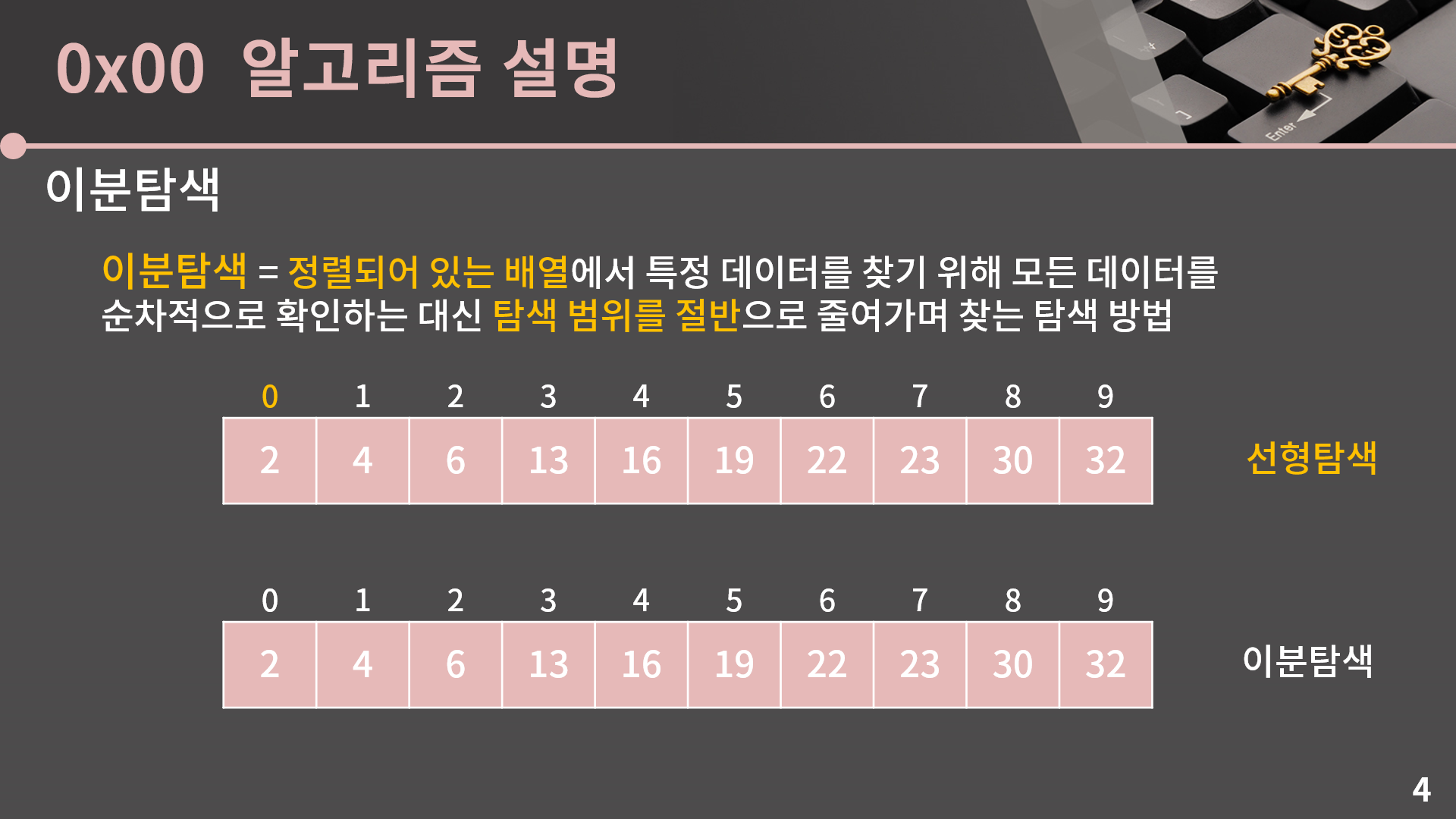
이분탐색은 정렬되어 있는 배열에서 특정 데이터를 찾기 위해 모든 데이터를 순차적으로 확인하는 대신 탐색 범위를 절반으로 줄여가며 찾는 탐색 방법을 말합니다. 그림으로 예시를 보면 지금 주어진 이 10칸짜리 배열에서 22가 있는지를 찾고 싶다고 할 때
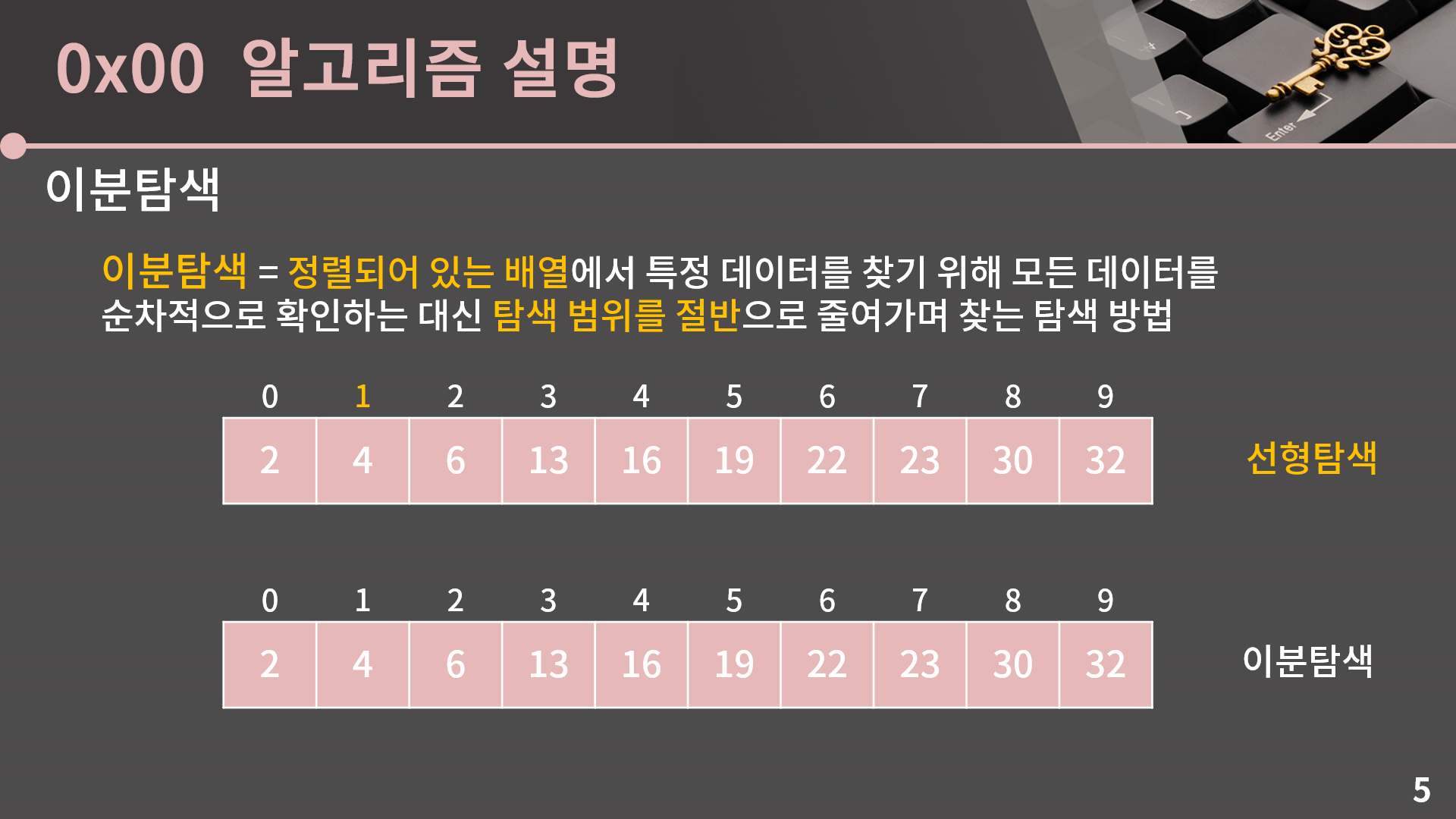
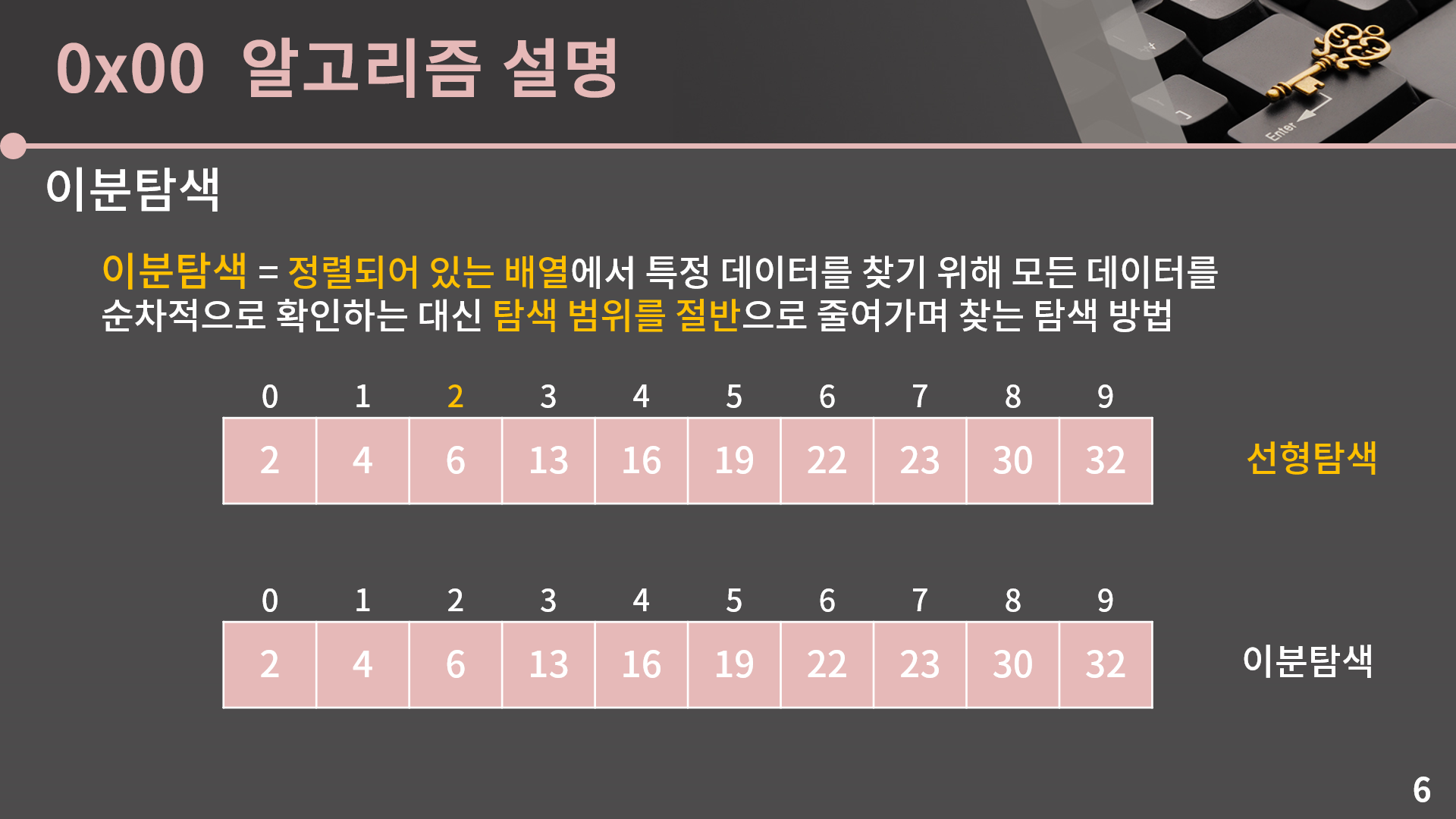
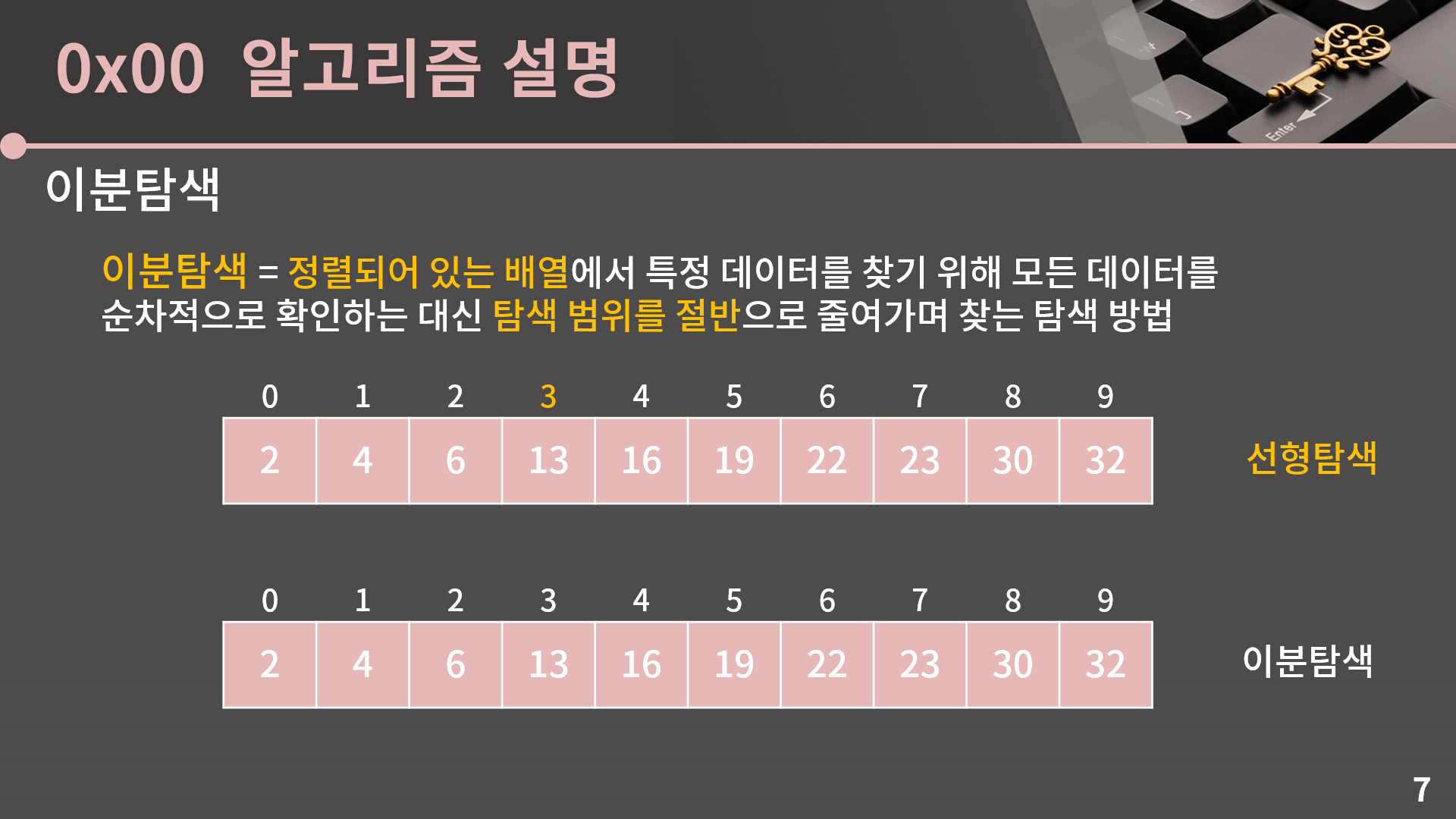
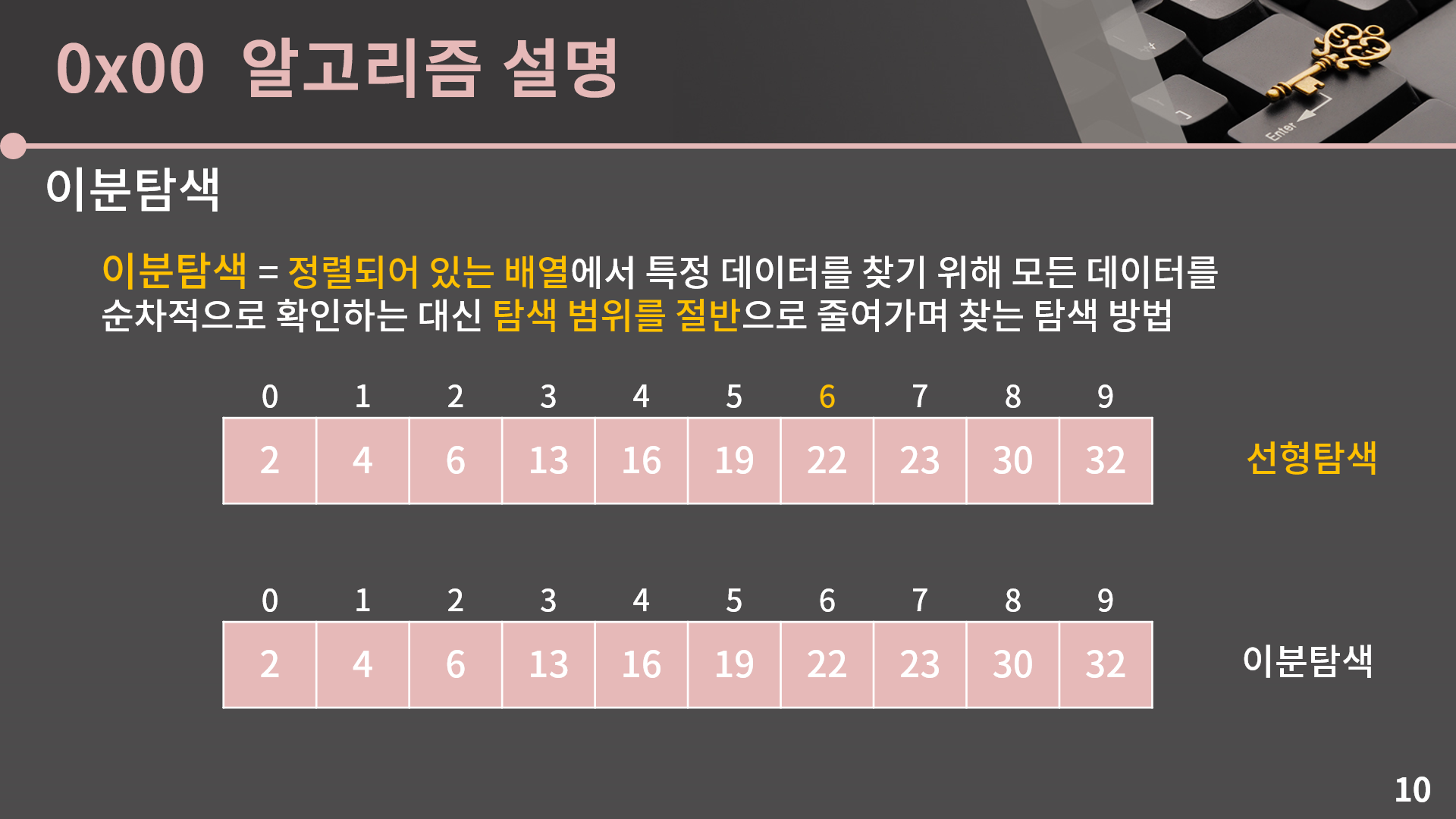
제일 앞의 원소 2부터 하나씩 차례대로 확인을 하는건 선형탐색의 탐색법이고
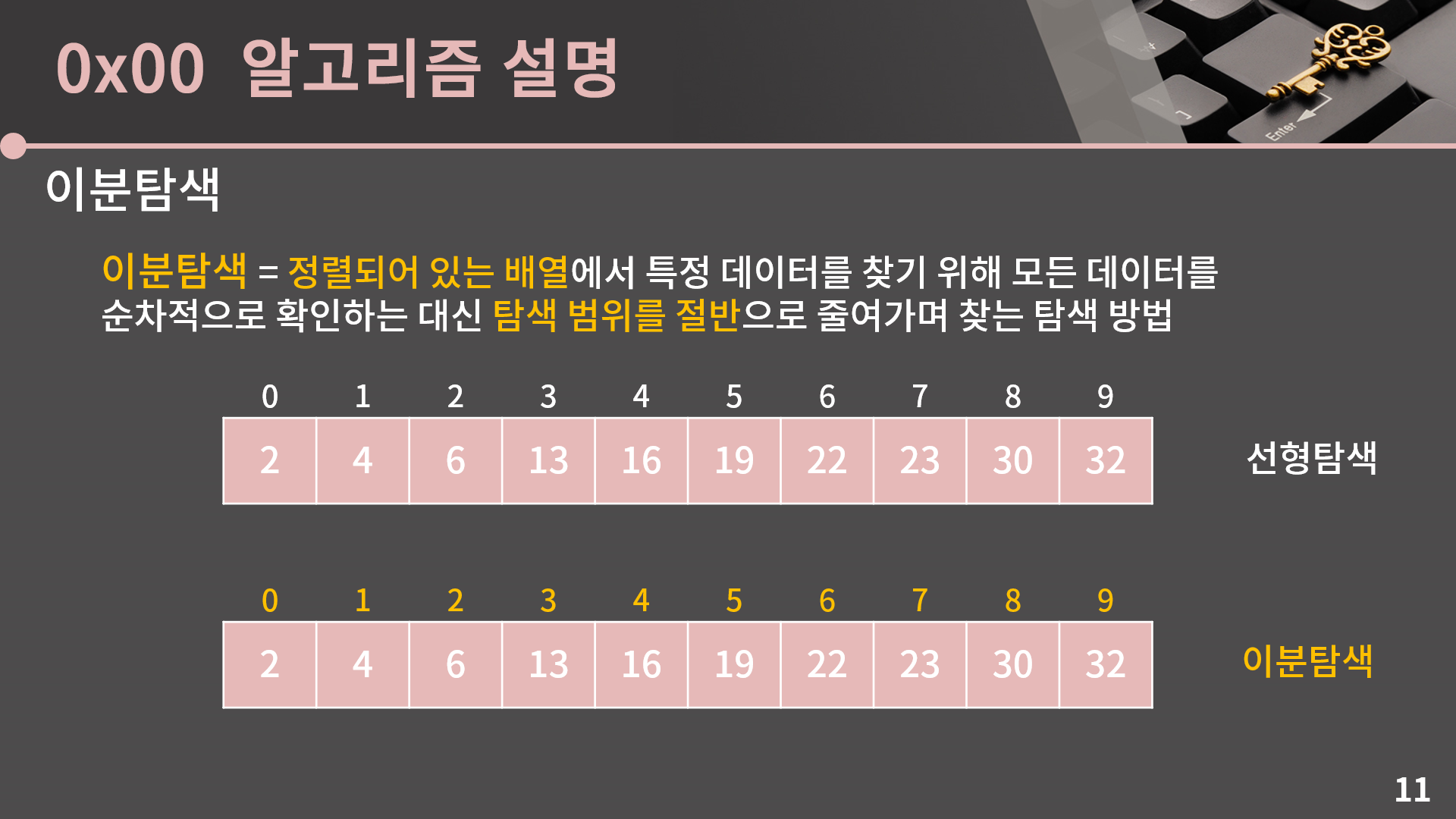
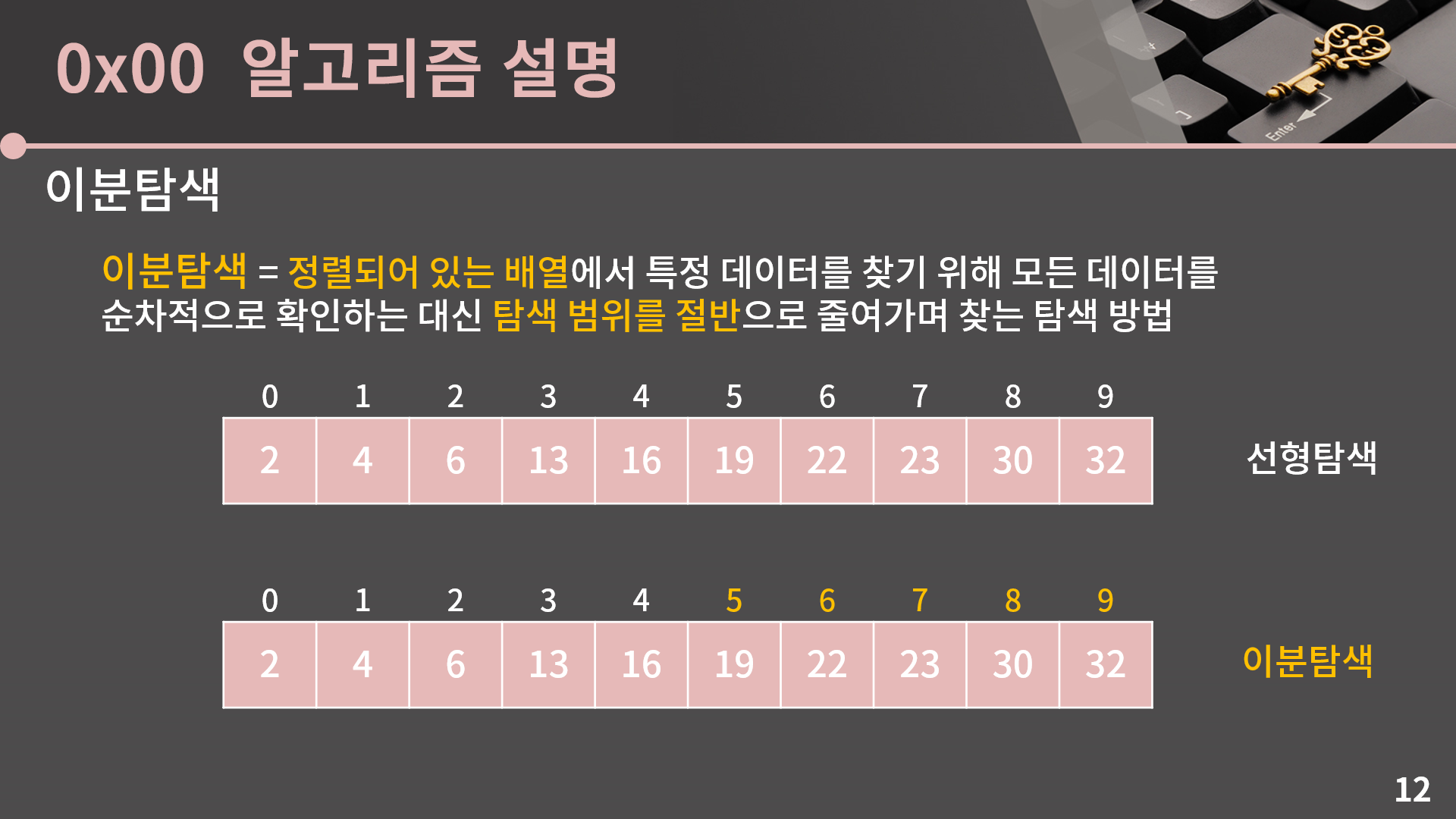

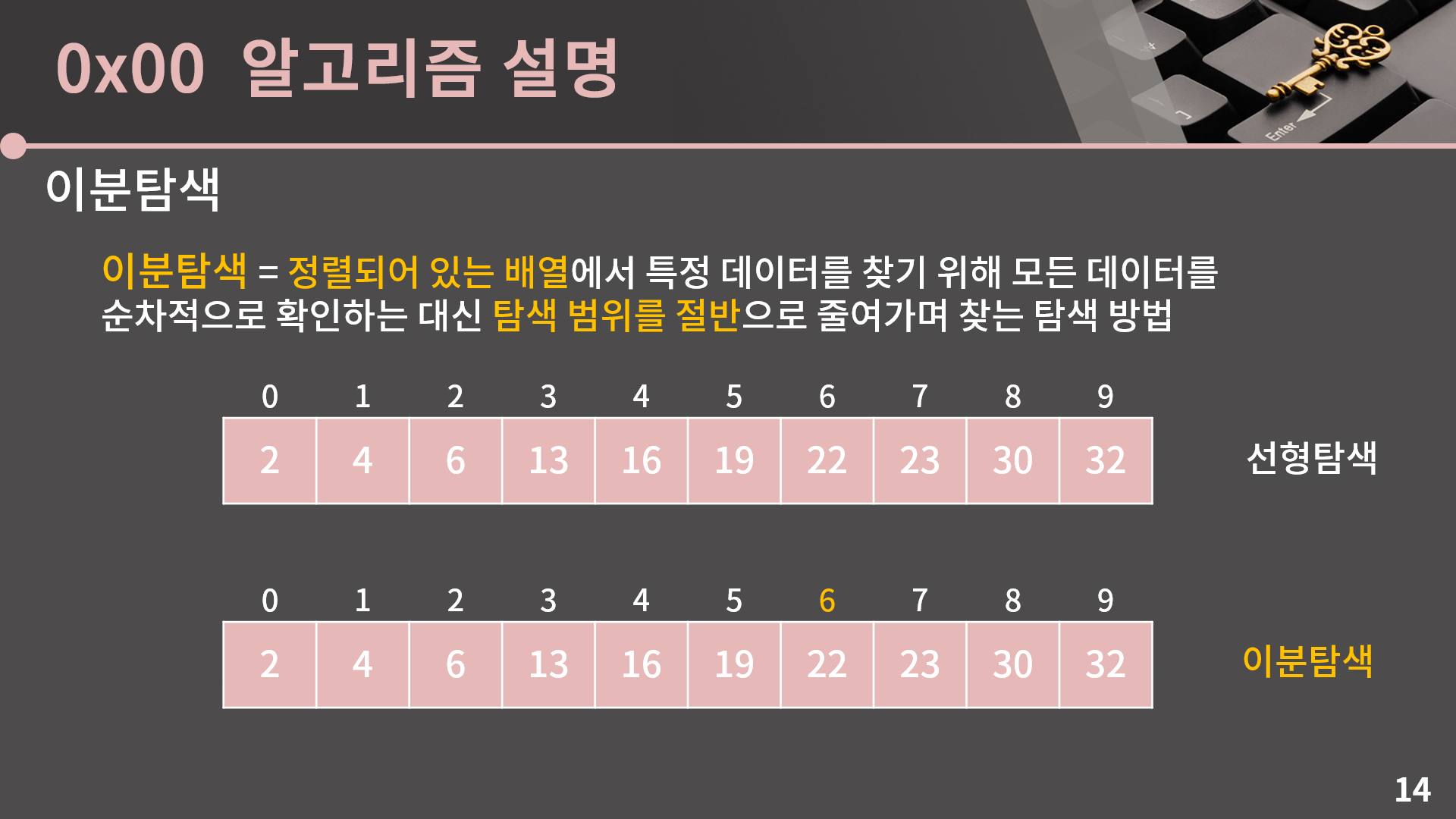
범위를 절반으로 줄여나가는건 이분탐색의 탐색법입니다. 선형탐색은 O(N)에 동작하고 이분탐색은 O(lg N)에 동작하기 때문에 N이 커지면 커질수록 둘은 아주 큰 속도의 차이가 발생합니다. 사실 굳이 이 설명이 없더라도 이분탐색이 뭔지는 거의 다 알고 계셨을 것 같은데 이걸 어떻게 구현하는지가 문제입니다. 그래서 바로 구현 방법을 소개하겠습니다.
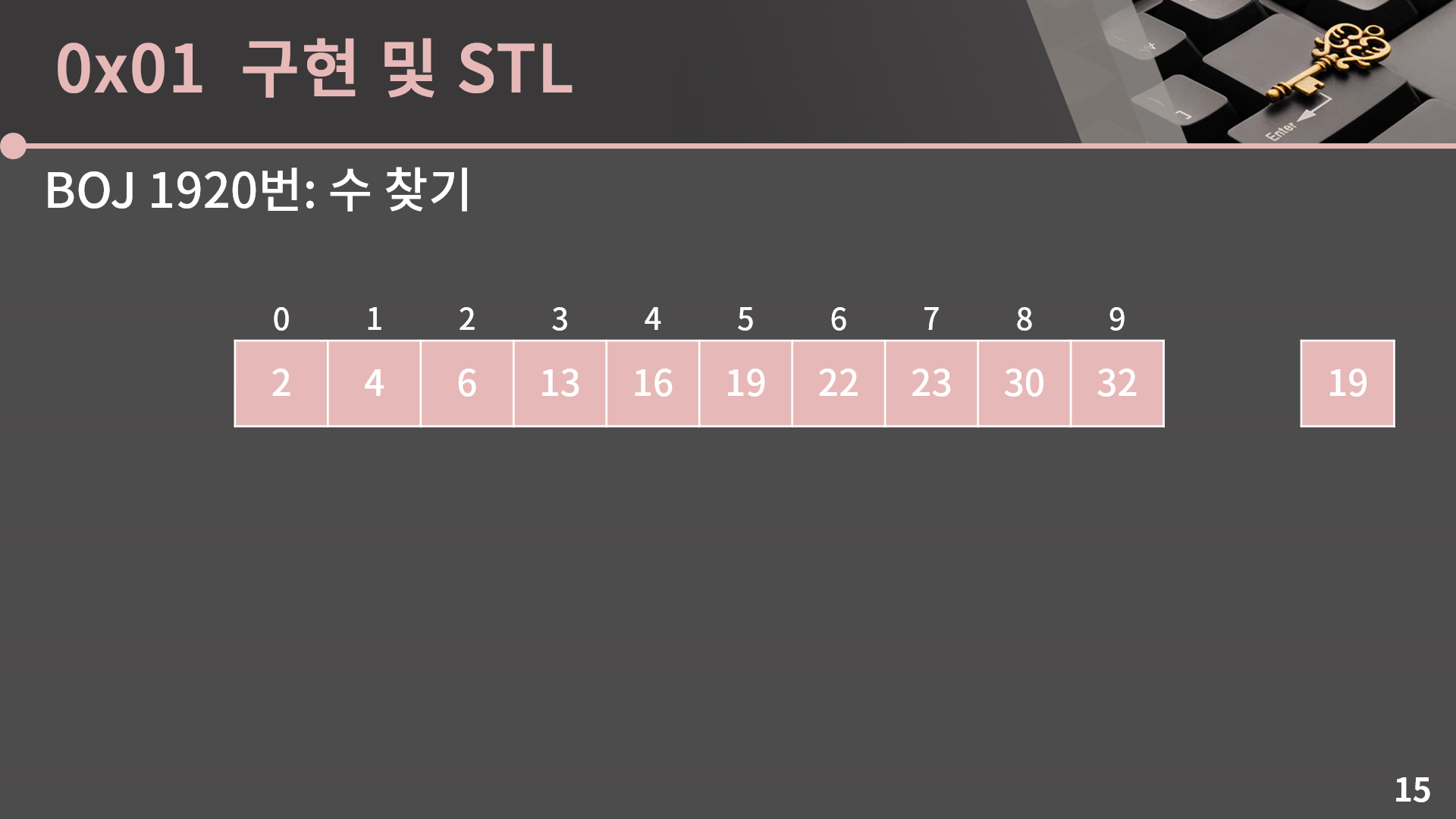
BOJ 1920번: 수 찾기 문제를 보면 굉장히 정직하게 이분탐색을 할 것을 요구하고 있습니다. 만약 각 M개의 수에 대해 선형탐색을 한다면 답은 잘 나올테지만 시간복잡도가 O(NM)이어서 시간 초과가 발생합니다. 반면에 미리 배열 A를 정렬해둔 다음 이분탐색을 수행하면 O(NlgN+MlgN)에 풀이가 가능합니다. NlgN은 정렬에 필요한 시간복잡도, MlgN은 이분탐색에 필요한 시간복잡도입니다. 그런데 구현이 조금 막막할겁니다. 구현을 어떻게 하면 되는지 같이 살펴보겠습니다.
예시로 쓸 배열은 앞에서 나온 배열을 재활용하겠습니다. 여기서 19가 있는지를 판단해보겠습니다. 문제에서 배열 A는 정렬되어있지 않지만 입력을 받은 후에 STL sort 함수를 이용해 정렬시킬 수 있습니다. 그렇기 때문에 배열은 이미 정렬이 되어있다고 가정을 하고 이분탐색을 시작해보겠습니다.

이분탐색을 할 때에는 st와 en 두 변수가 필요합니다. st와 en은 내가 찾으려고 하는 19가 있을 수 있는 범위를 나타냅니다. 맨 처음에는 일단 st = 0, en = 9로 둬서 st에서 en 사이가 전체 범위를 나타내도록 합니다. 당연한 얘기지만 이 범위 안에 우리가 찾고싶어하는 그 값이 없을수도 있습니다.
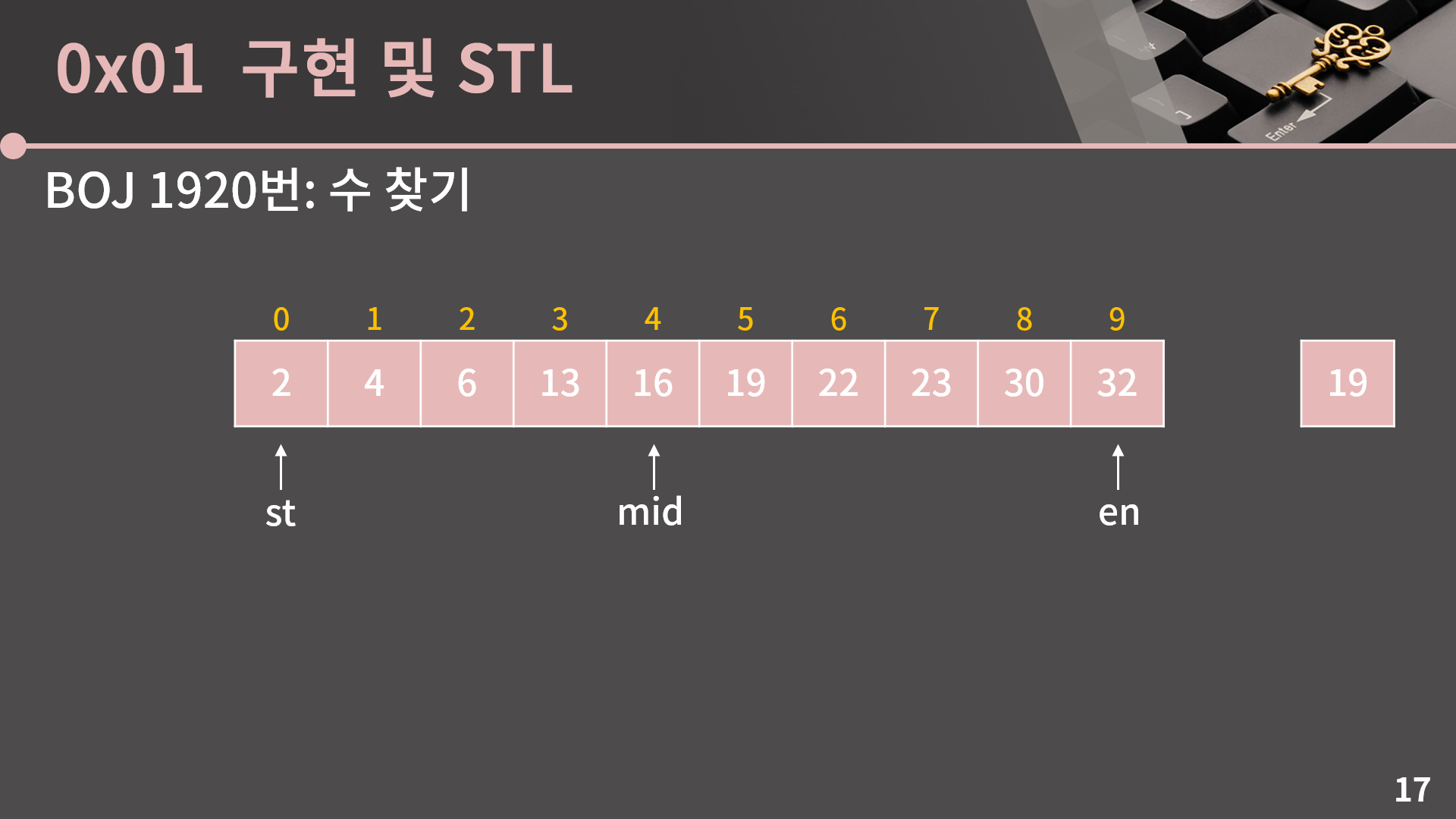
여기서 범위를 절반으로 줄이기 위해서 mid = (st+en)/2 지점을 생각합니다. C++언어의 특성상 만약 (st+en)이 홀수라면 나머지는 버립니다. 지금 st = 0, en = 9인 상황에서 mid = 4입니다. 우리는 A[mid]와 19의 값을 비교해 범위를, 즉 st 혹은 en의 값을 적절하게 바꿀 예정입니다.
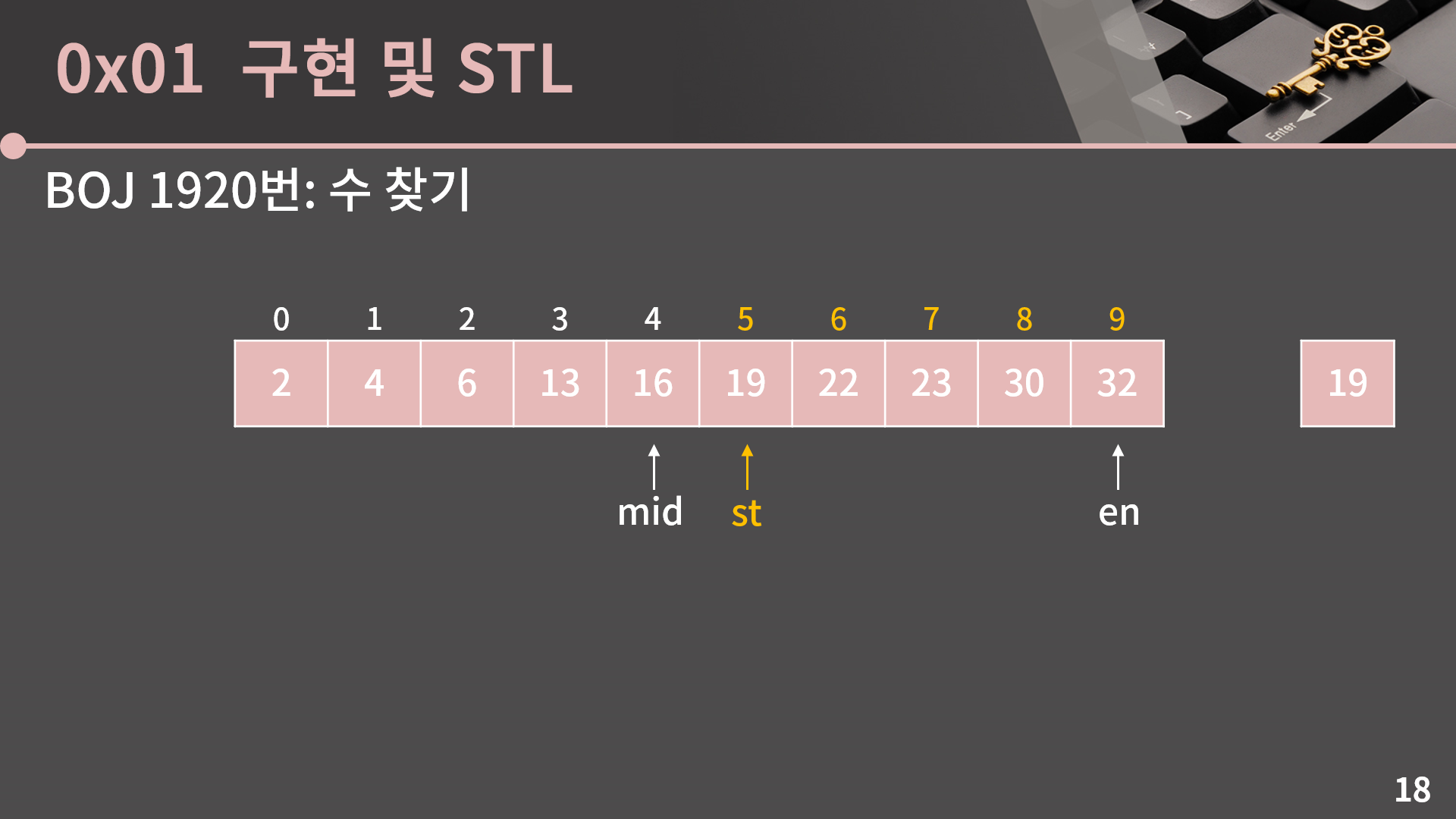
비교해보면 A[mid] = 16인데 찾고 싶은 값은 19입니다. 그러면 적어도 mid 이하의 인덱스에는 19가 없다는 사실을 알 수 있고, 이를 이용해서 st = mid+1로 변경해 범위를 절반으로 줄일 수 있습니다.
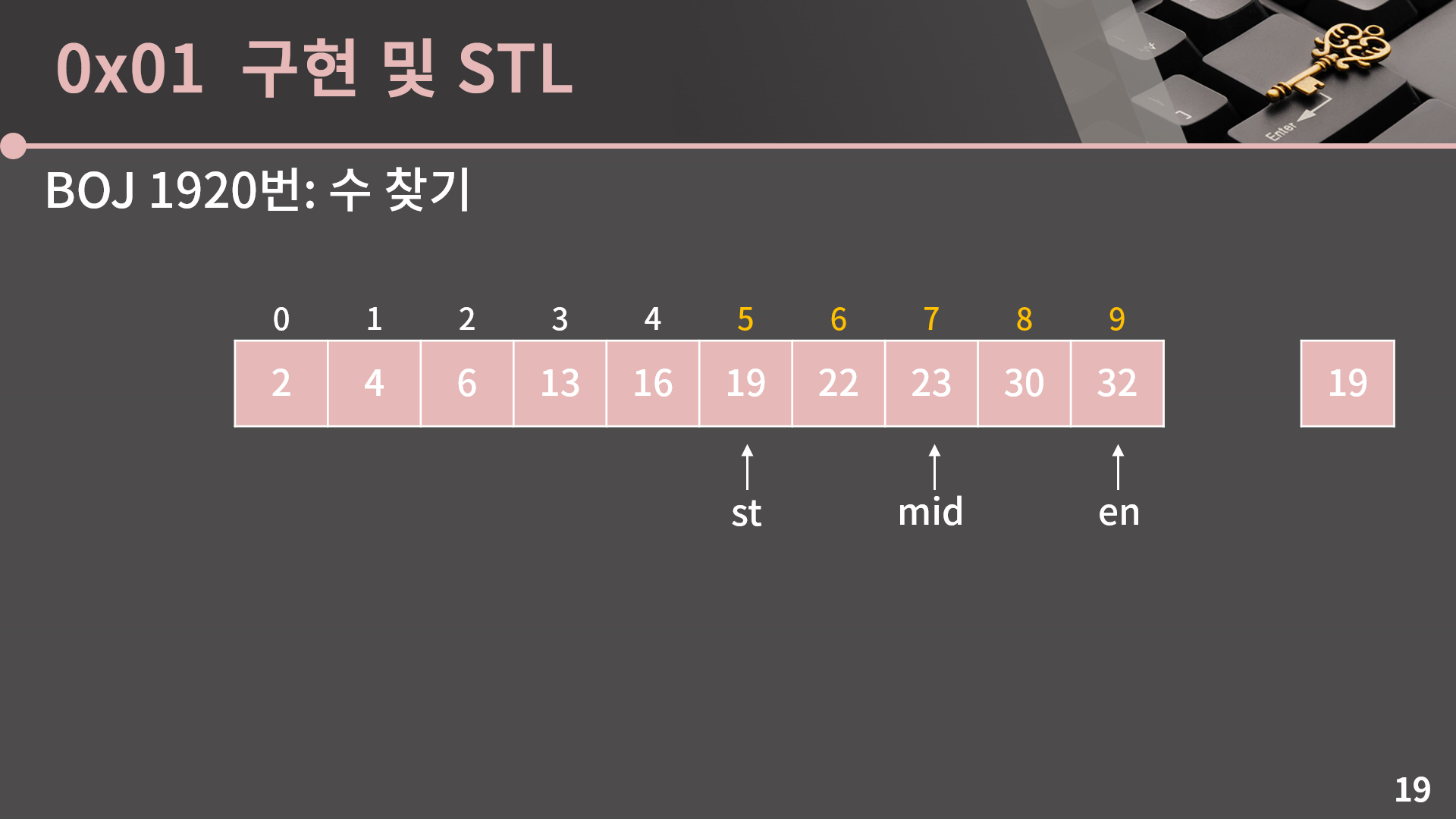
다음으로 절반으로 줄어든 범위에서 또다시 mid = (st+en)/2로 계산합니다.
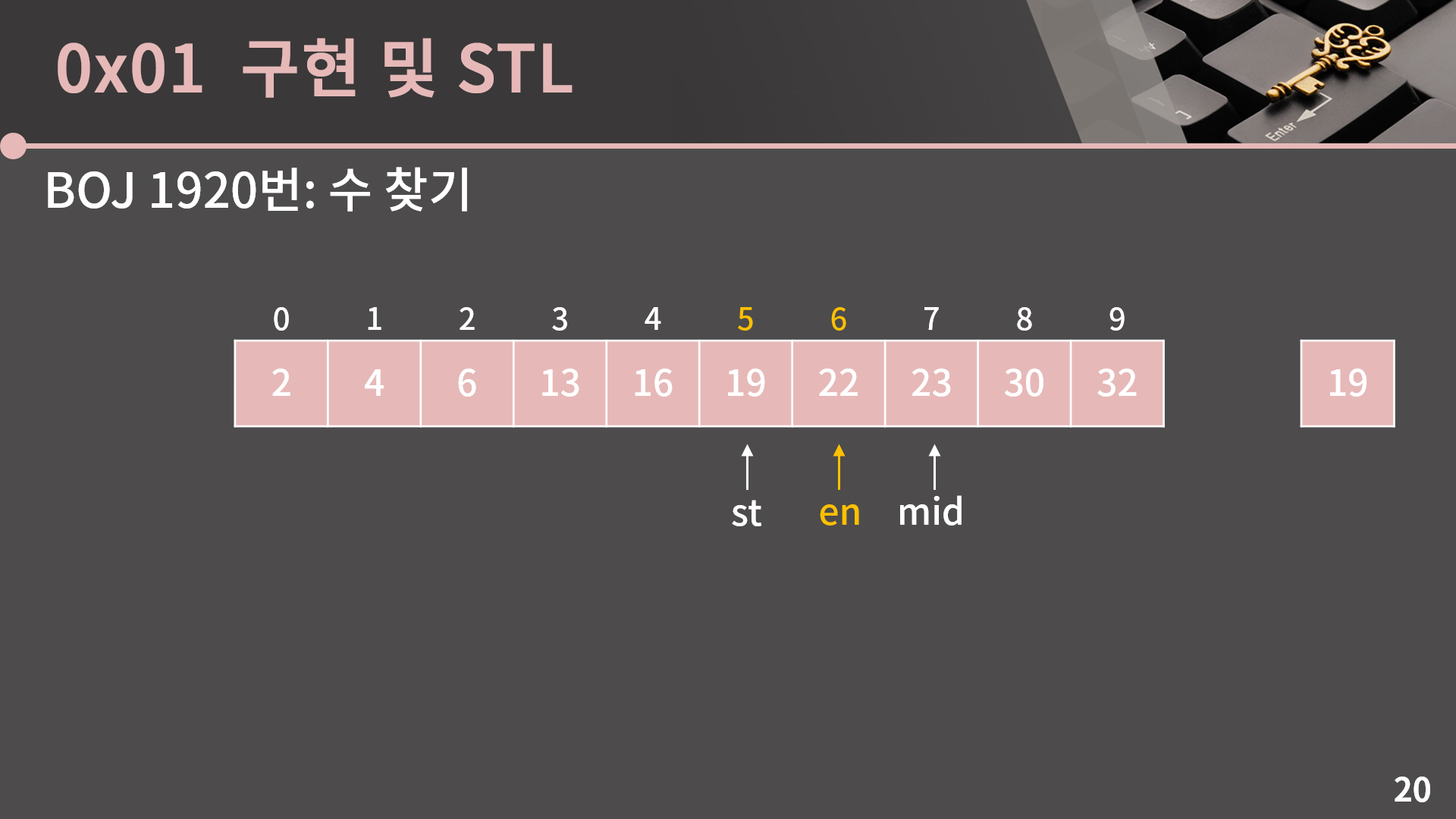
마찬가지로 A[mid]와 target을 비교해보면 A[mid] = 23은 19보다 크기 때문에 mid 이상의 인덱스에는 19가 없고 이를 이용해 en = mid-1로 변경할 수 있습니다.
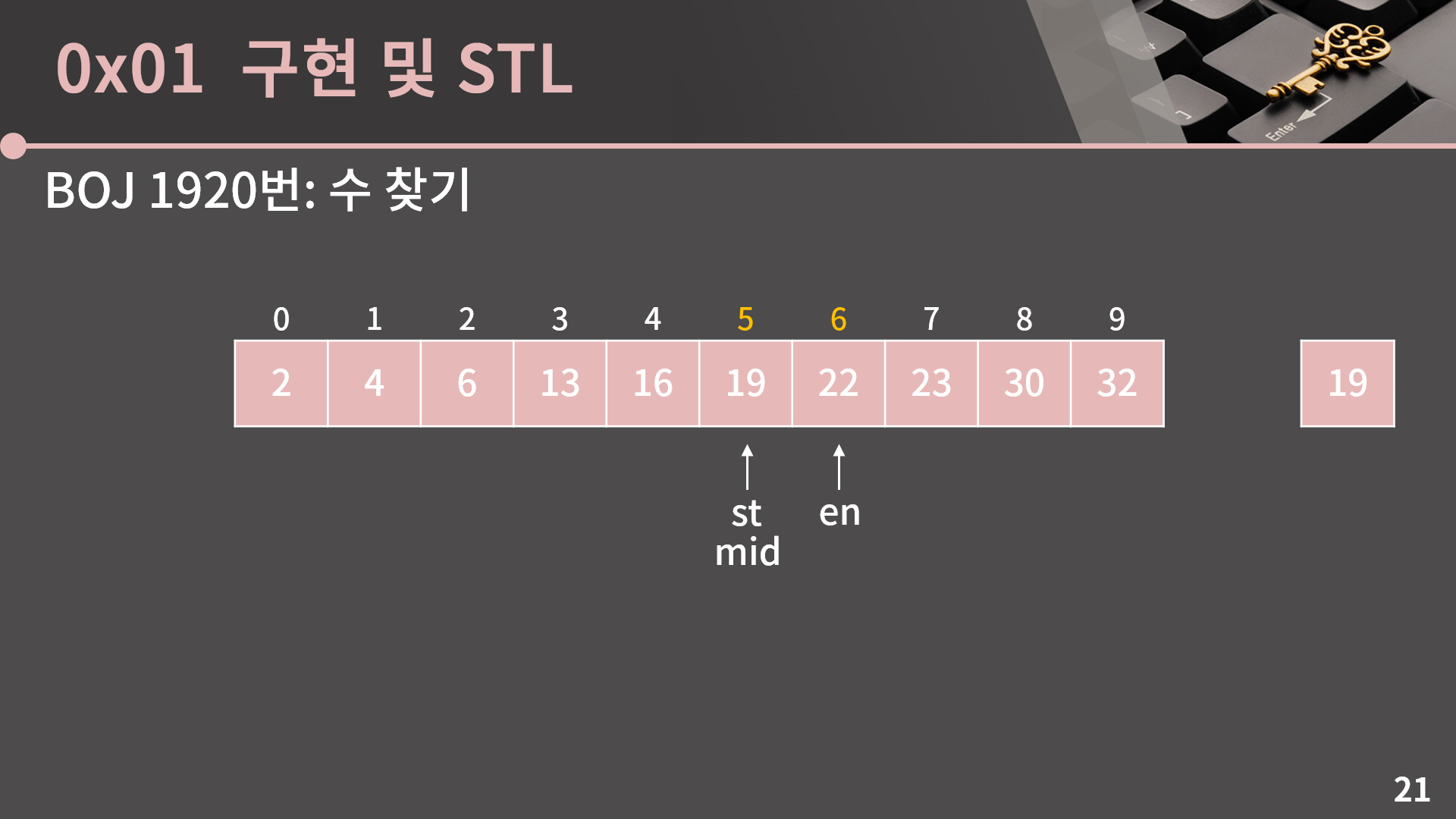
또 다시 mid = (st+en)/2로 두면 mid = 5입니다.
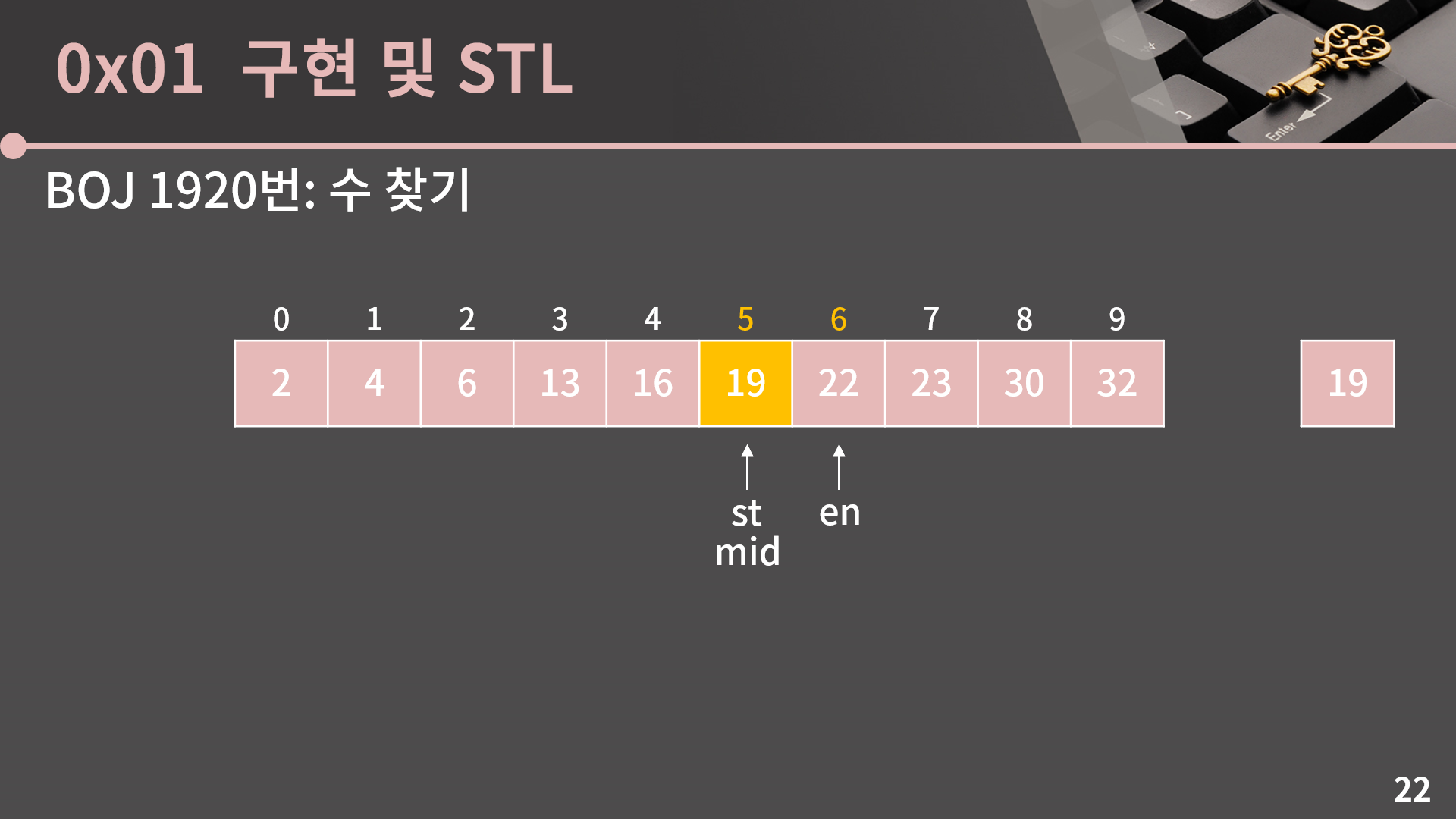
A[mid]와 target을 비교해보면 A[mid] = 19는 우리가 찾고 싶어하는 바로 그 값입니다. 그렇기 때문에 19가 있다는걸 확인할 수 있습니다.
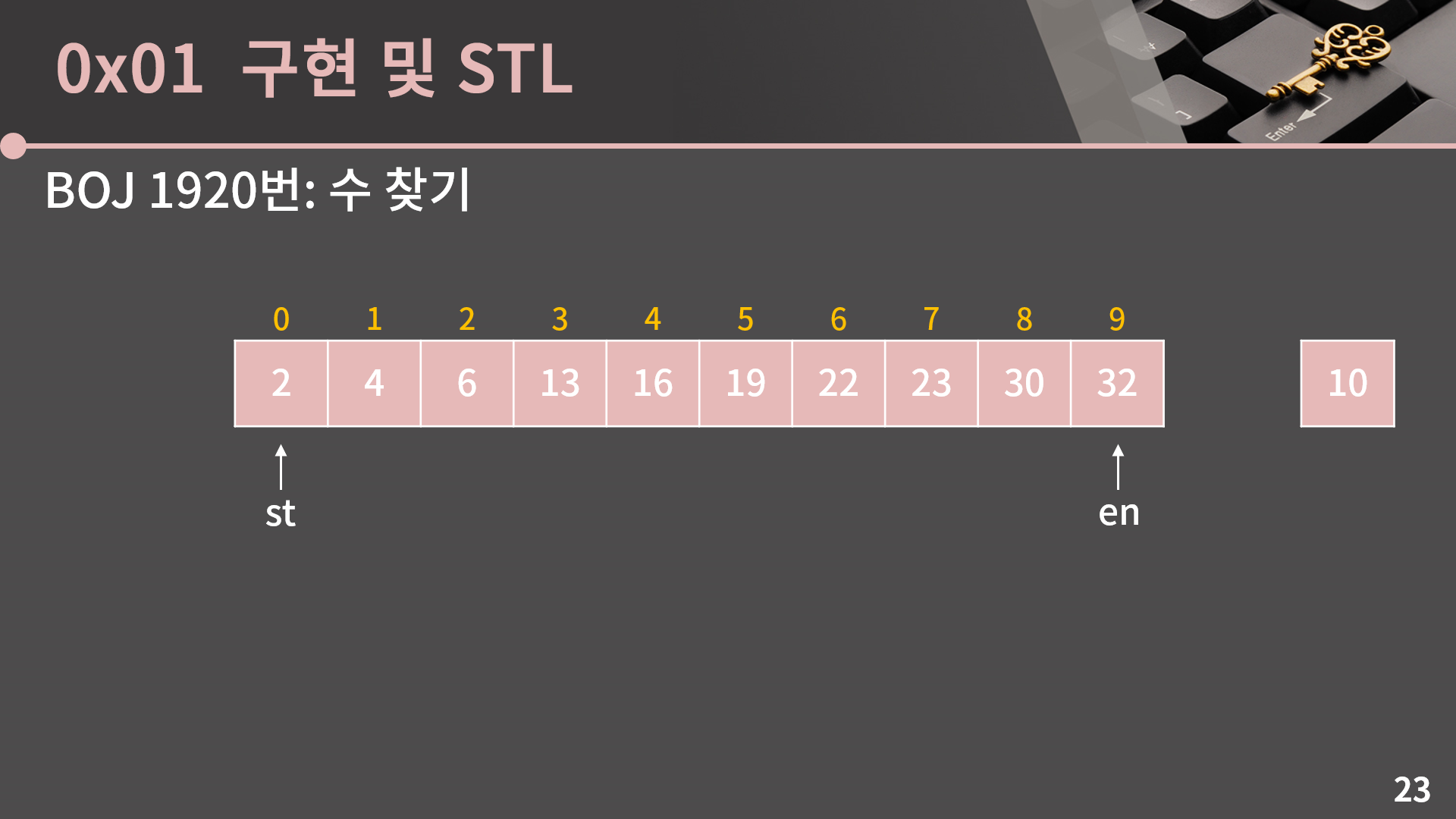
이 과정을 구현해보기 전에 만약 배열 안에 내가 찾고 싶어하는 수가 없다면 어떤 상황이 펼쳐지는지도 같이 보겠습니다. 배열에서 10을 찾아보겠습니다. st와 en의 초기값은 0과 9입니다.

mid = (st+en)/2로 계산 가능하고 A[mid]와 10을 비교해 st 혹은 en을 바꾸겠습니다.

A[mid] = 16은 10보다 크기 때문에 mid 이상의 인덱스에는 10이 없고, 이를 이용해 en = mid-1로 변경할 수 있습니다.
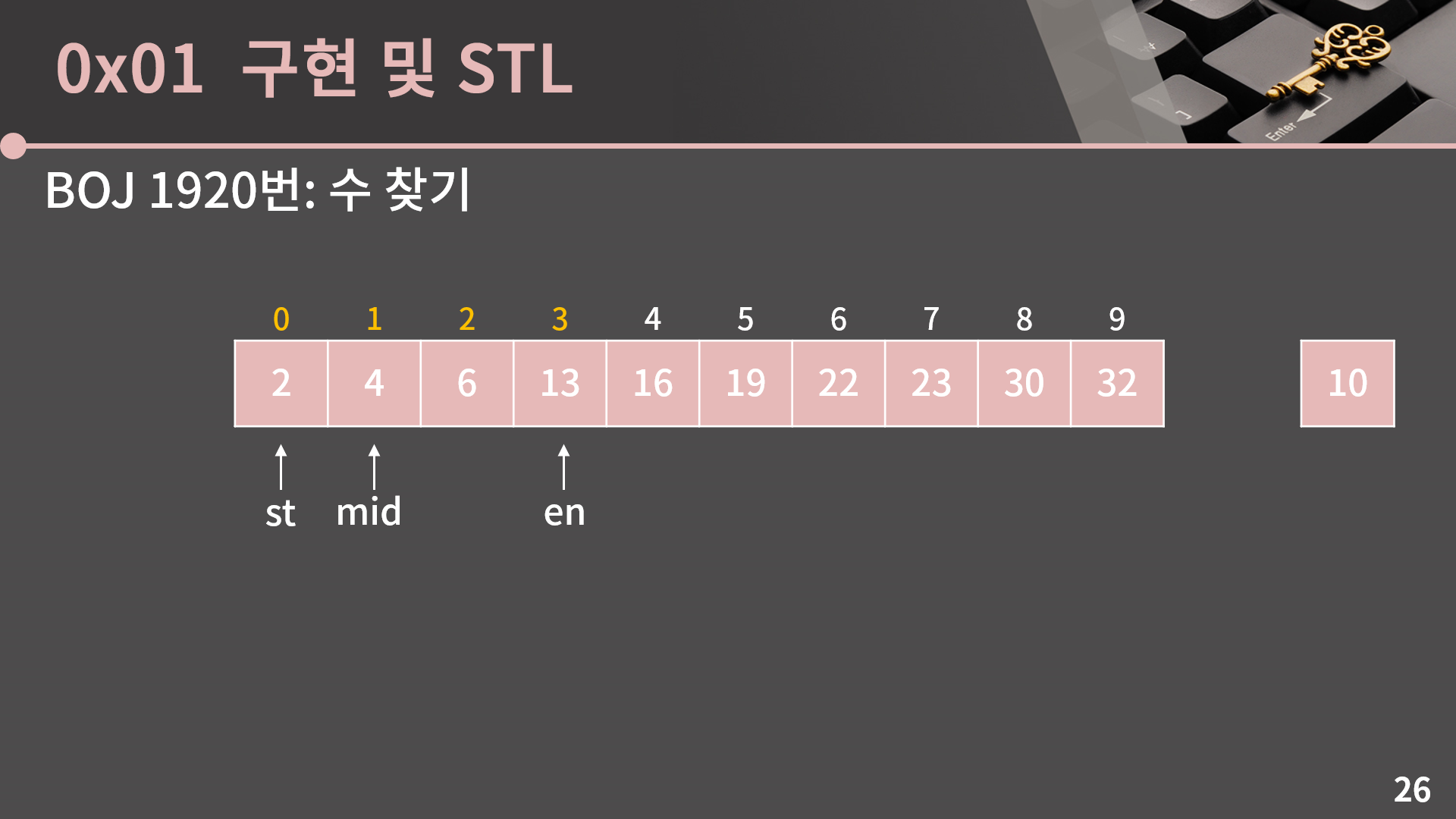
다시 mid = (st+en)/2으로 계산합니다.
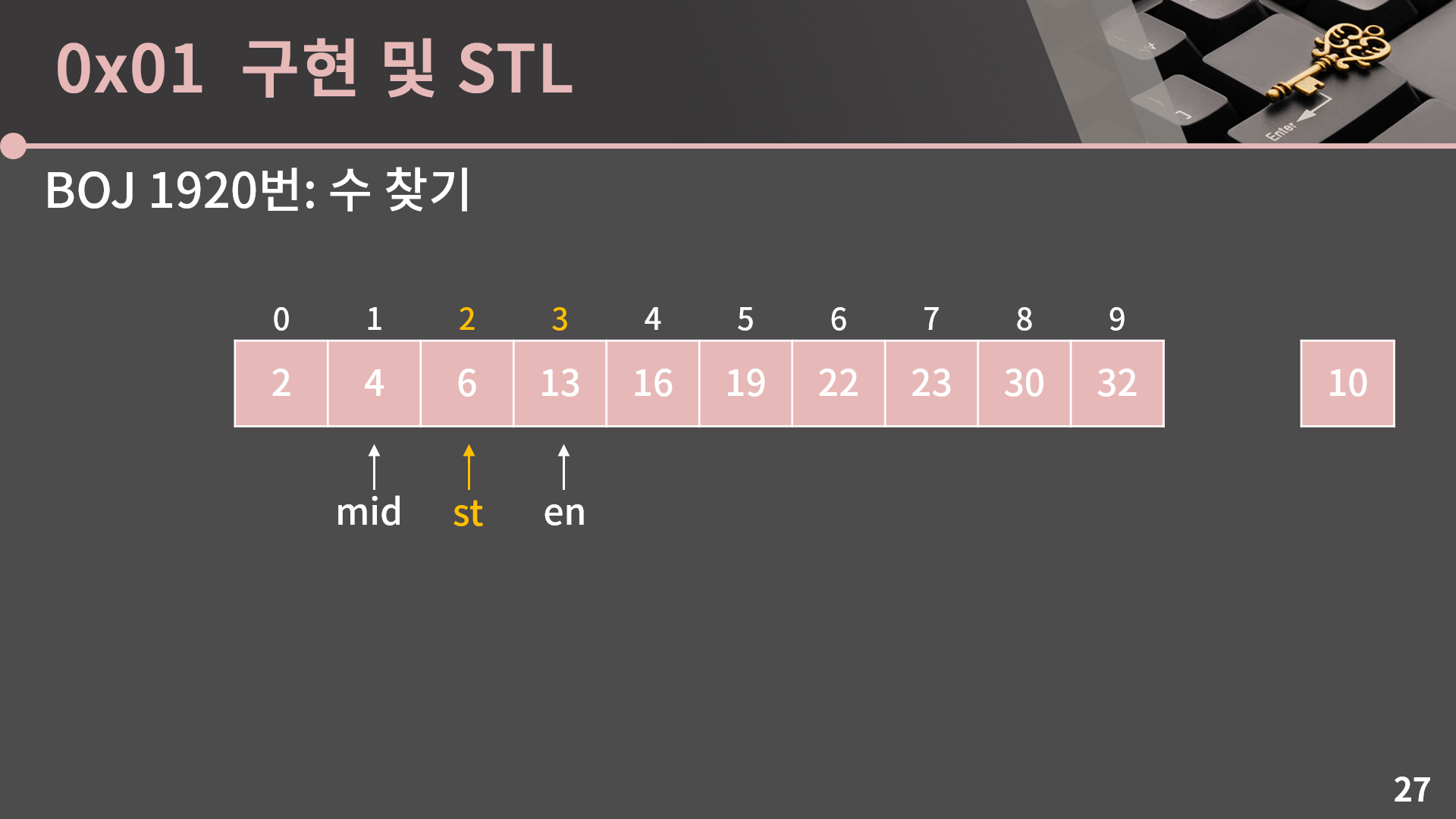
A[mid] = 4는 10보다 작기 때문에 mid 이하의 인덱스에는 10이 없고, 이를 이용해 st = mid+1로 변경할 수 있습니다.
다시 mid = (st+en)/2로 계산합니다.

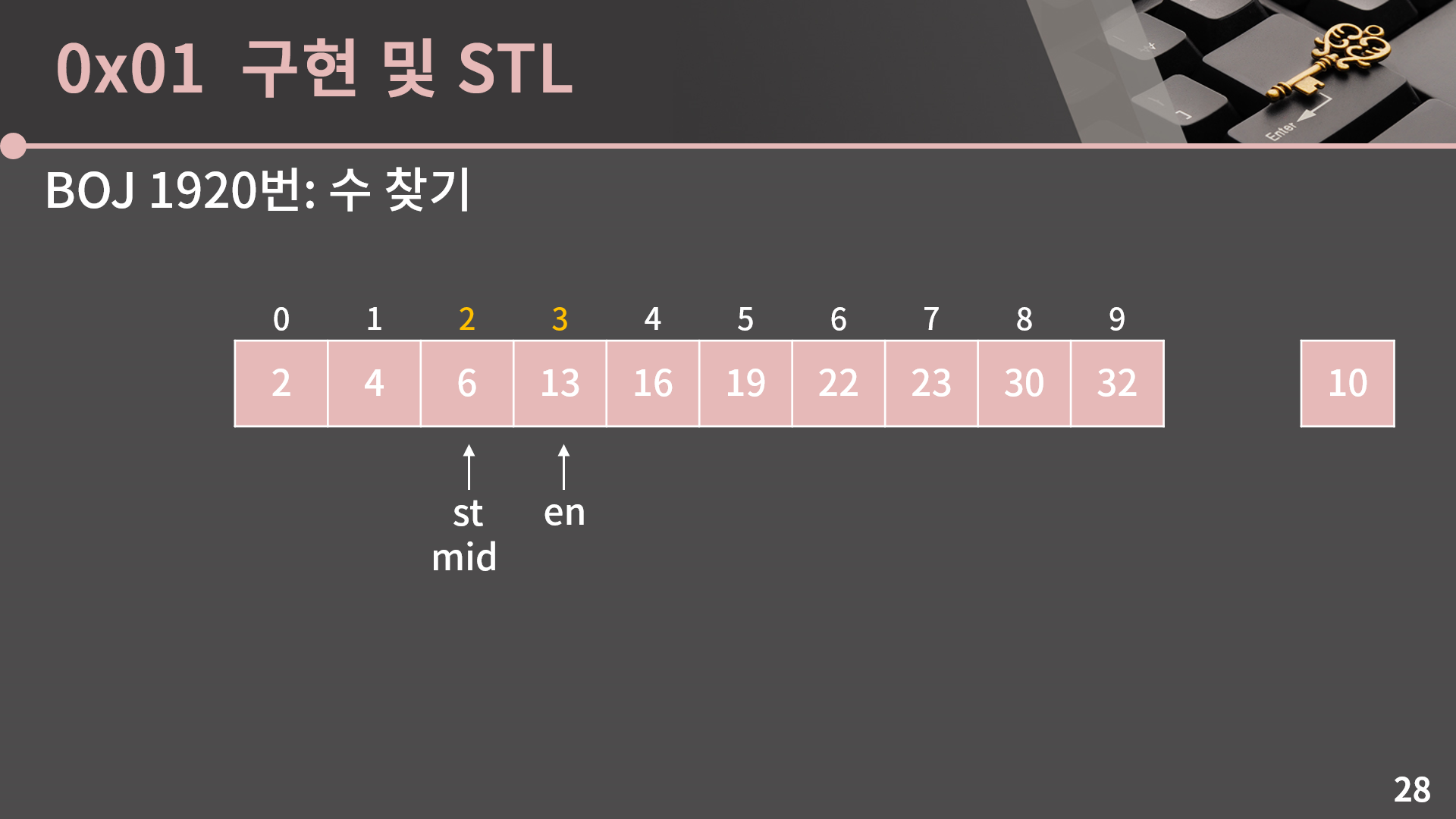
A[mid] = 6은 10보다 작기 때문에 mid 이하의 인덱스에는 10이 없고, 이를 이용해 st = mid+1로 변경할 수 있습니다.
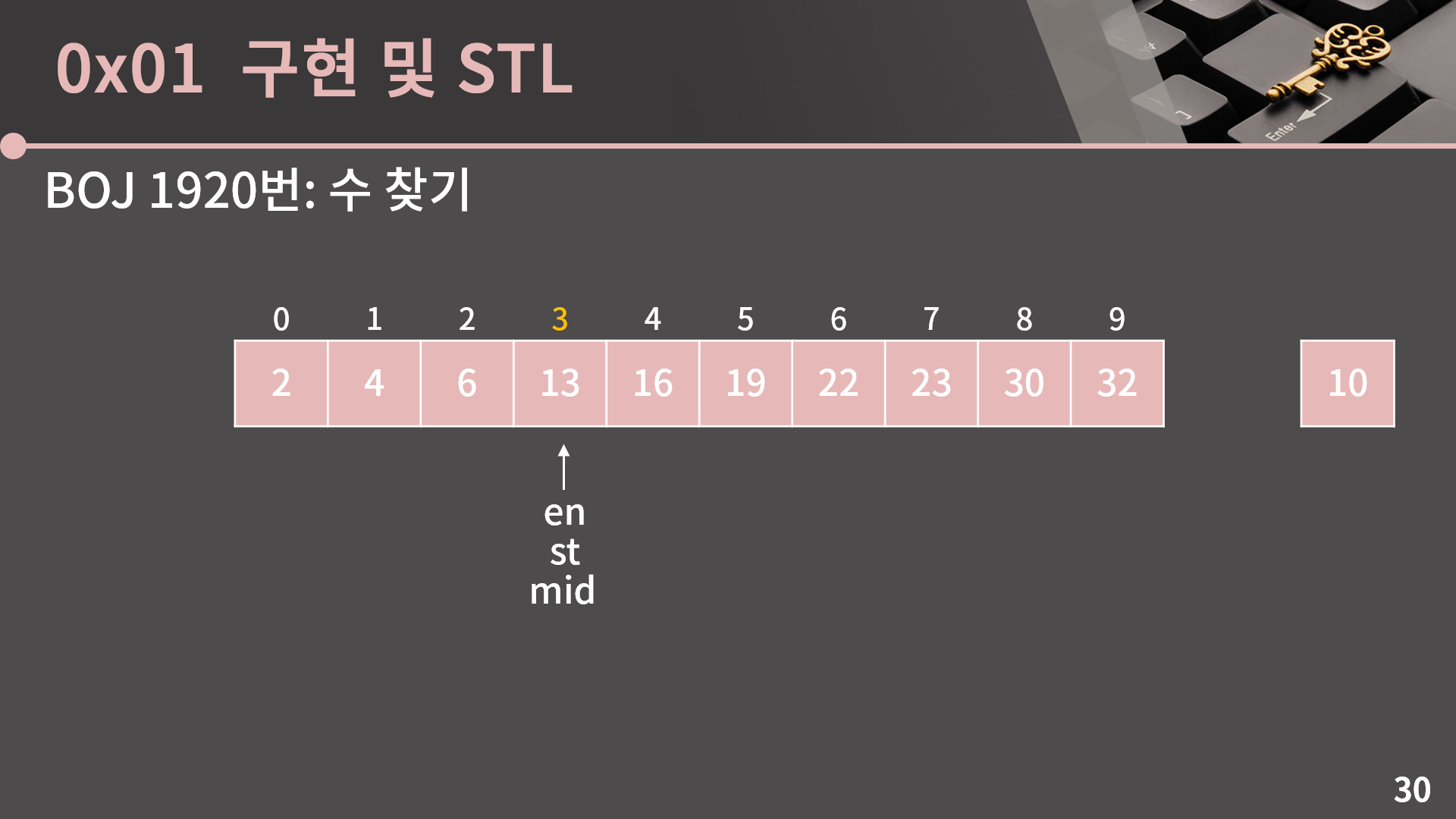
다시 mid = (st+en)/2로 계산합니다. st와 en과 mid가 다 한 곳으로 모였습니다.
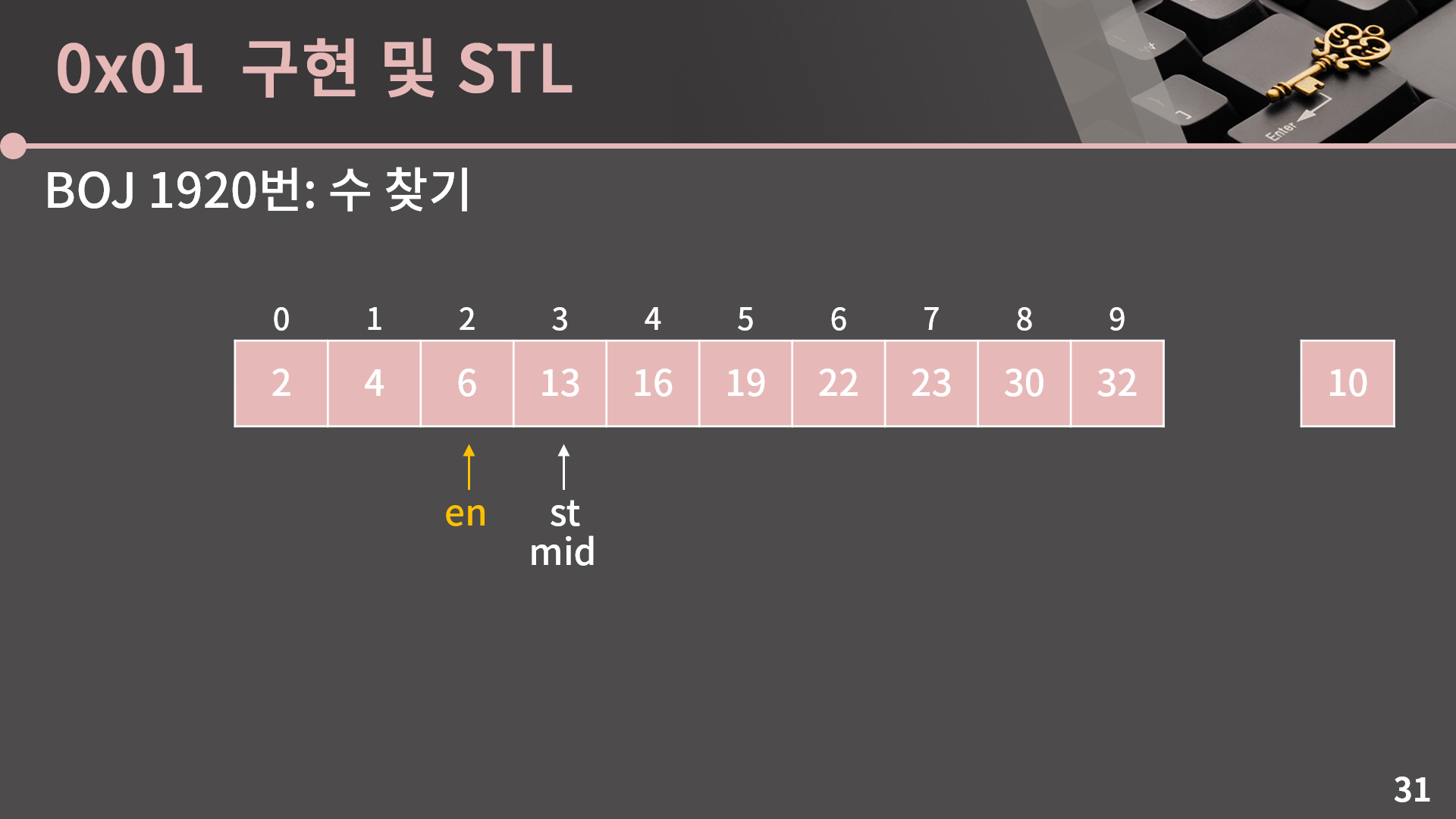
A[mid] = 13은 10보다 크기 때문에 mid 이상의 인덱스에는 13이 없고, 이를 이용해 en = mid-1로 변경할 수 있습니다. 보면 st와 en이 역전됐습니다. 그와 함께 10이 있을 수 있는 범위를 의미하는 st에서 en 사이의 값 또한 사라졌습니다. 그렇기 때문에 배열 안에 10이 없음을 알 수 있습니다.
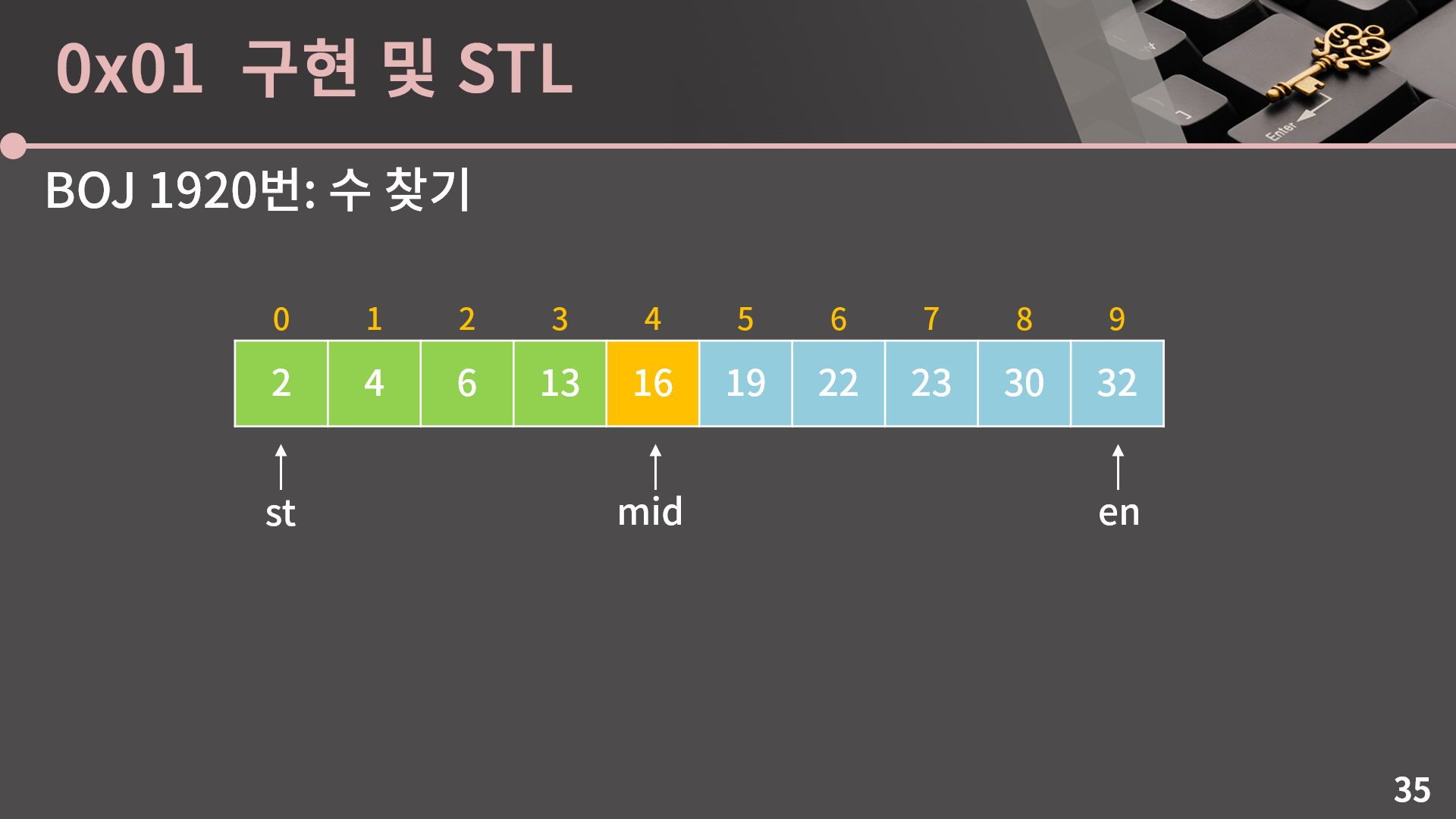
A[mid]와 목표로 하는 값의 대소비교 결과에 따라 구간이 어떻게 줄어드는지 보면, 목표로 하는 값을 target이라고 표현할 때 먼저 A[mid] > target일 경우에는 초록색 구간에 대응되어서 en = mid - 1로 변경하면 됩니다. A[mid] = target일 경우에는 주황색 구간에 대응되어서 st = en = mid가 되는데 사실 굳이 st와 en을 바꿀 필요가 없이 바로 target이 있다는 결과를 반환해도 됩니다. 마지막으로 A[mid] < target일 경우에는 하늘색 구간에 대응되어서 st = mid + 1로 변경하면 됩니다. 이렇게 진행을 하다가 만약 st와 en이 역전된다면 target이 존재하지 않는다는걸 의미합니다. 문제를 푸는 코드를 작성해보겠습니다.

다들 직접 짜보셨겠죠? 설명한 것 그대로 binarysearch 함수를 구현하면 됩니다. 처음 짜보면 조금 헷갈릴 수 있지만 구현이 그렇게 어렵지는 않습니다. (코드 링크)

그리고 사실 STL에는 binary_search 함수가 있어서 범위를 주면 주어진 범위 내에 원소가 들어있는지 여부를 O(lg N)에 true 혹은 false로 알려줍니다. 단 범위는 반드시 오름차순으로 정렬되어 있어야 합니다. 그렇지 않다면 실제로는 값이 들어있는데 들어있지 않다고 판단하는 일이 발생할 수 있습니다.
binary_search 함수를 이용하면 이 문제를 더 쉽게 해결할 수 있습니다. 첫 번째와 두 번째 인자로 범위의 시작과 끝을 넘겨줘야 하고, 만약 a가 배열 대신 vector였다면 두 인자를 각각 a.begin(), a.end()로 넣어주면 됩니다. 이분탐색을 실제로 구현해보는건 아주 좋은 연습이지만 STL을 쓰기에 적합한 상황이라면 가능하면 직접 구현하는 대신 STL을 써서 푸는게 실수를 줄일 수 있어서 좋습니다. (코드 링크)
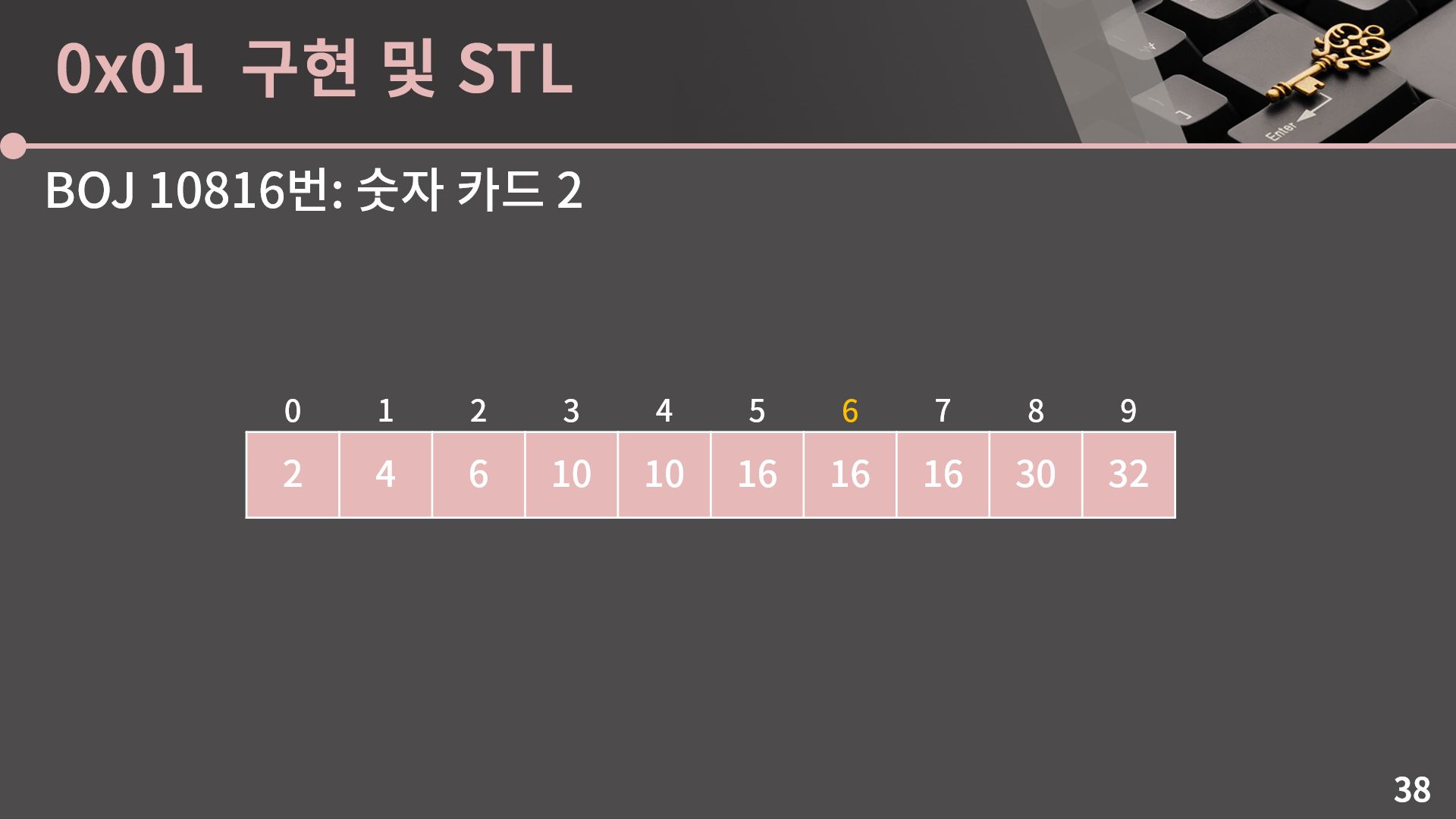
이렇게 첫 번째 문제를 그럭저럭 무난하게 넘겼고 두 번째 문제인 BOJ 10816번: 숫자 카드 2 문제를 보겠습니다. 이 문제에서는 앞 문제와 다르게 단순히 배열에 수가 있는지만을 판단하면 되는게 아니고 몇 번 등장했는지도 구해야 합니다. 일단 STL binary_search 함수는 단순히 등장했는지 아닌지만 알려주기 때문에 애초에 써먹을 수가 없습니다. 우리가 직접 구현했던 함수를 살짝 수정해서 어떻게 할 수 없을까 하는 생각을 해보면, 일단 우리의 함수가 1 혹은 0을 반환하는 대신 target이 있는 인덱스를 반환하도록 고쳤다고 해보겠습니다. 그러면 배열에 target이 여러 번 들어있을 때 그 인덱스들 중에서 아무 인덱스나 반환하게 됩니다. 예시를 보면 5, 6, 7중에서 아무거나 반환하게 됩니다.

그러면 그 중에서 6을 받았다고 치면 시도해볼 수 있는 방법은 6에서 시작해 값이 계속 target일 때 까지 왼쪽으로 이동하고,

또 그 인덱스에서 시작해 값이 계속 target일 때 까지 오른쪽으로 이동하면 개수를 파악할 수 있겠지만 이런 방법은 target의 개수에 비례하는 시간이 걸리기 때문에 최악의 경우 배열에 있는 모든 수의 값이 같다면 그냥 O(N)이 걸려서 비효율적입니다.
그러면 뭔가 왼쪽 끝과 오른쪽 끝을 어떻게 잘 확인할 수 있다면 해결이 될 것 같은데 일단 이정도로만 생각해서 머리에 넣어두고 잠깐 다른 얘기를 해보겠습니다.
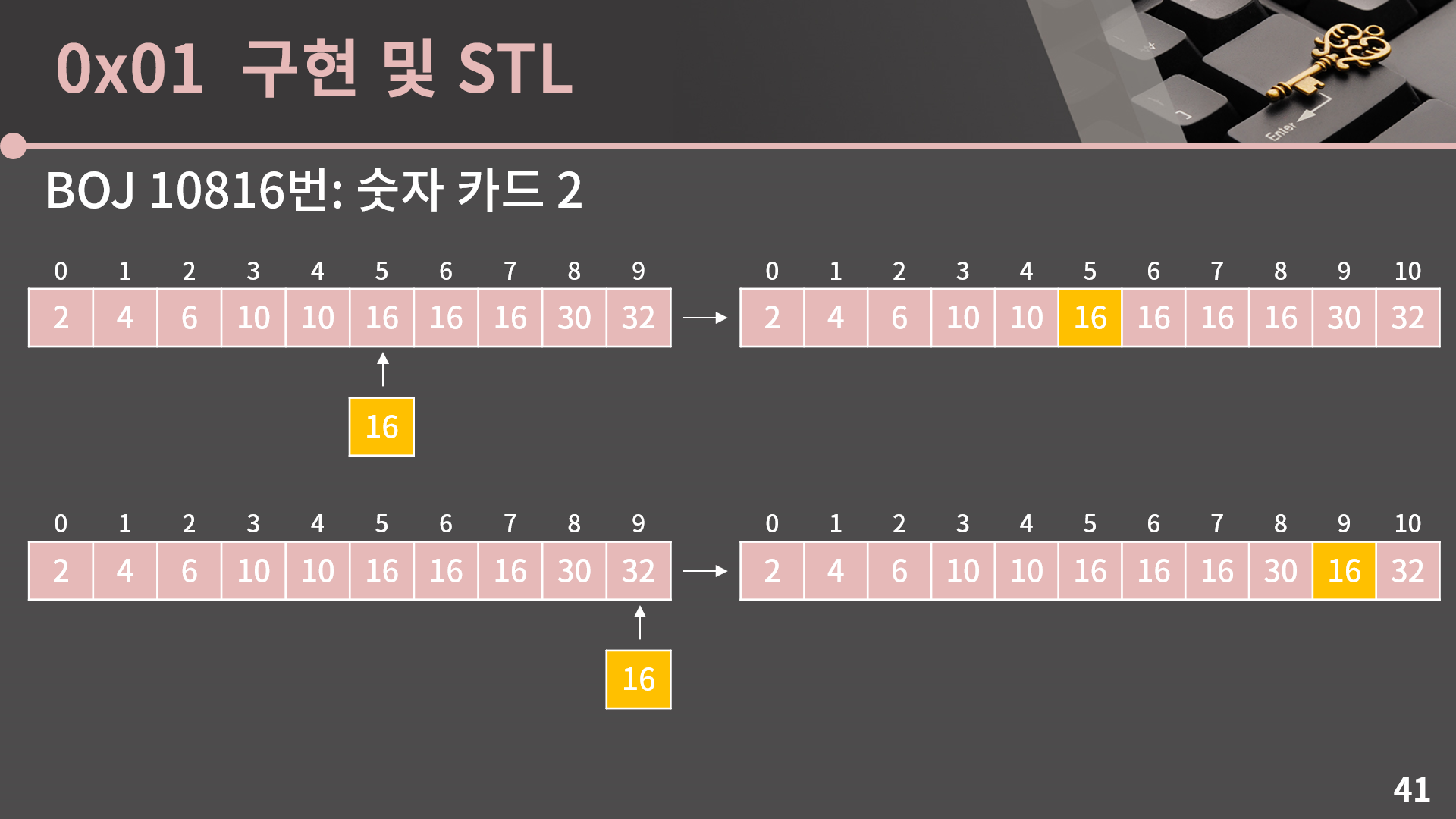
일단 우리는 배열의 특정 인덱스에 원소를 삽입할 수 있습니다. 특정 인덱스에 원소를 삽입한다는게 무슨 소리냐면 지금 이 그림과 같은건데, 16을 5번 인덱스에 삽입을 하면 원래 5번 인덱스에 있던 원소와 그 뒤의 원소들이 전부 한 칸씩 뒤로 이동하고 16이 5번 인덱스로 들어갑니다. 그리고 배열을 보면 삽입 이후에도 오름차순 순서가 잘 유지됩니다. 하지만 만약 16을 9번 인덱스에 삽입하면 오름차순 순서가 더 이상 유지되지가 않습니다.
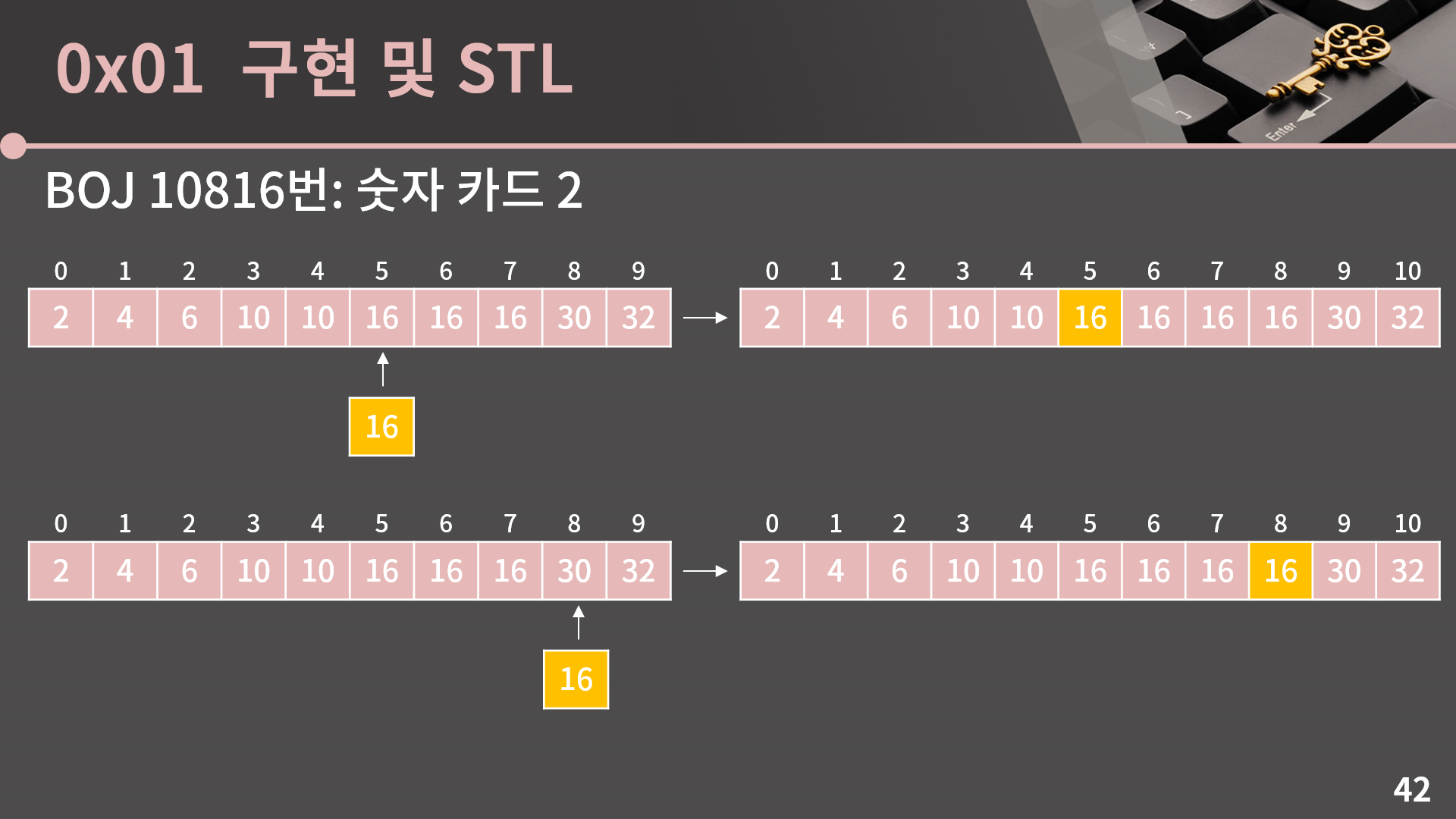
지금 배열에서 16이 삽입되어도 오름차순 순서가 유지되게끔 하려면 16과 크기가 같은 인덱스에 들어가거나, 최초로 16보다 큰 수가 등장하는 자리에 들어가야 합니다. 그림을 보면 16이 들어갈 수 있는 가장 왼쪽 위치는 5이고 가장 오른쪽 위치는 8이란걸 알 수 있습니다. 우리는 삽입할 수가 주어질 때 오름차순 순서가 유지되는 가장 왼쪽 위치와 오른쪽 위치를 이분탐색으로 구할 예정입니다.
그리고 눈썰미가 좋으신 분이라면 눈치챘겠지만 오름차순 순서가 유지되는 제일 왼쪽과 오른쪽 인덱스의 차이가 바로 해당 배열에서 그 수의 등장 횟수입니다. 16을 보면 배열에서 16은 5, 6, 7번 인덱스에서 나오니 총 3번 등장하는데 오름차순 순서가 유지되는 오른쪽 위치는 8이고 가장 왼쪽 위치는 5이니까 8-5 = 3으로 잘 성립하는걸 볼 수 있습니다. 또 만약 배열에 그 수가 등장하지 않더라도 논리는 마찬가지로 잘 성립합니다. 20을 예로 들면, 20은 최초로 20보다 큰 수가 등장하는 8번 인덱스에 삽입할 때에만 오름차순 순서가 유지됩니다. 그러면 가장 왼쪽 위치도 8, 가장 오른쪽 위치도 8이니 등장 횟수는 8-8 = 0이라고 얘기할 수 있습니다.

이전과 다르게 삽입할 수 있는 위치는 0에서 9까지가 아니라 0에서 10까지라는 점에 주의해야 합니다. 10이 들어갈 수 있는 가장 왼쪽 위치를 구하는 과정을 살펴보겠습니다.
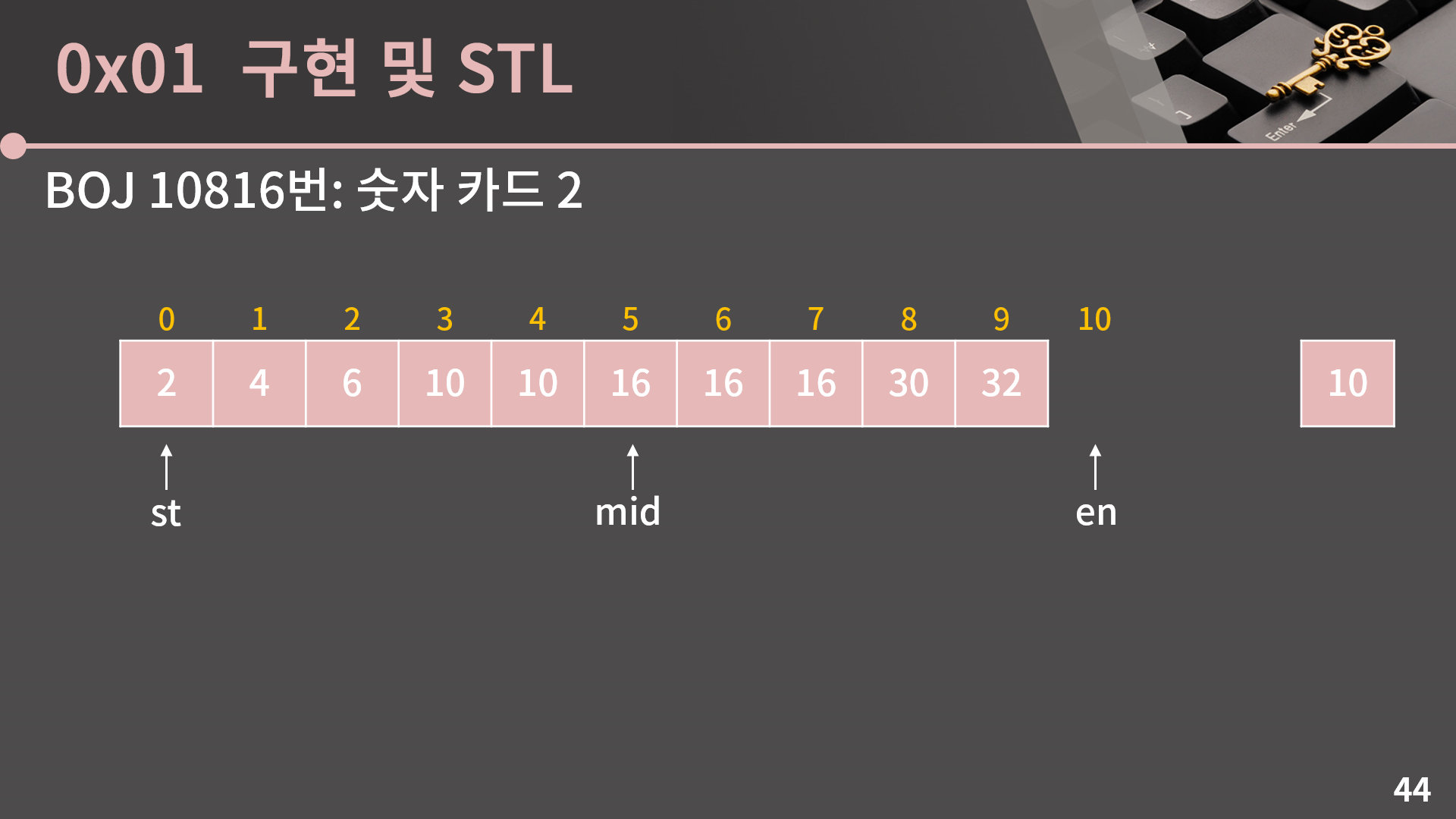
앞에서 한대로 mid = (st+en)/2를 계산합니다. A[mid]와 10을 비교해 st 혹은 en을 바꿀 예정입니다.
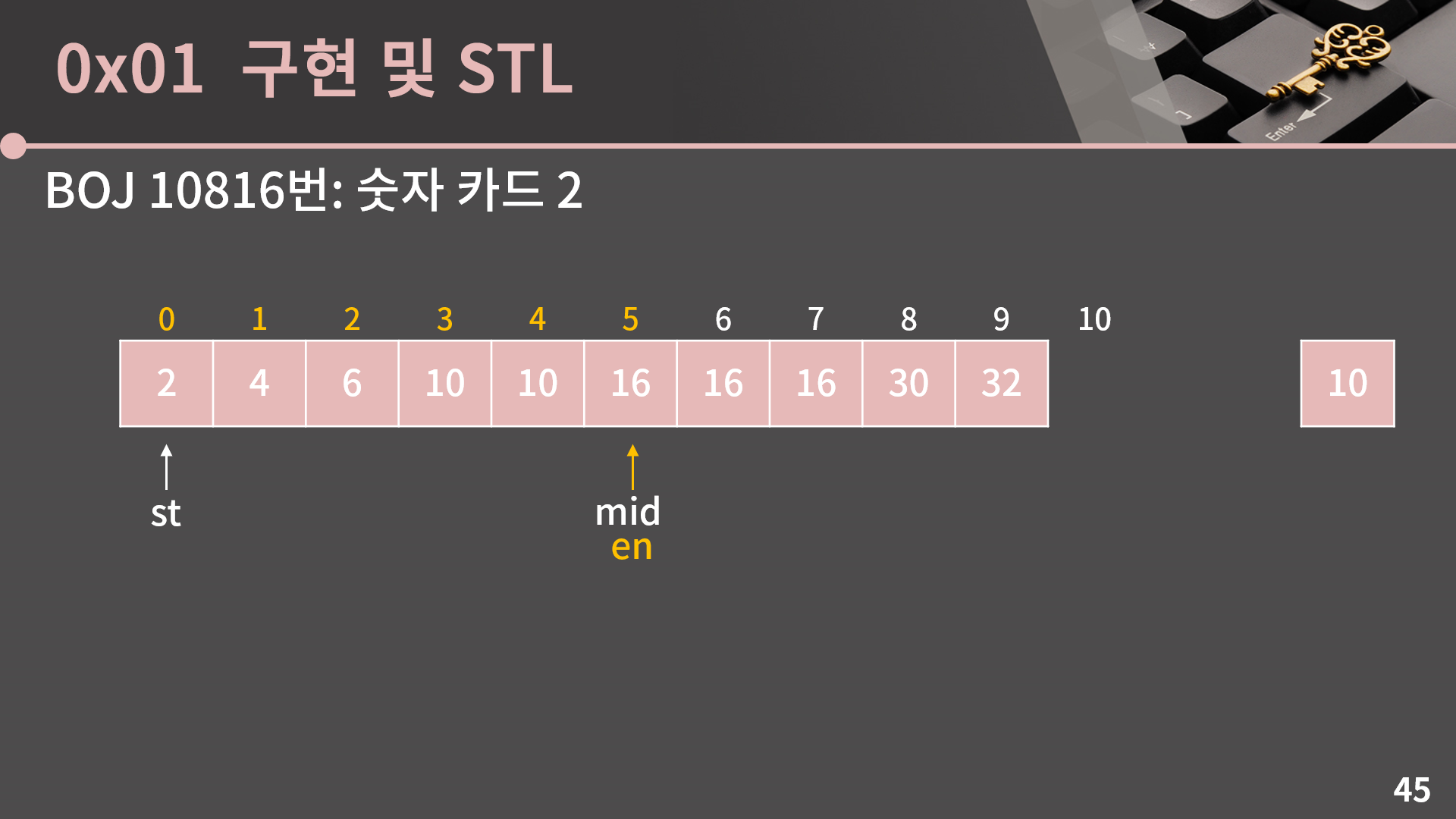
A[mid]는 10보다 큽니다. 한편 10이 들어갈 수 있는 가장 왼쪽 위치는 지금처럼 배열 안에 10이 있다면 10이 최초로 등장하는 위치고, 10이 없다면 10보다 큰 수가 최초로 등장하는 위치입니다. 그러면 A[mid]가 10보다 크다는 성질로부터 어떤 걸 알 수 있냐면, 10이 들어갈 수 있는 가장 왼쪽 위치는 mid 이하라는걸 알 수 있습니다. 이게 오히려 수가 써져있어서 더 혼동을 유발할수도 있는데, A[mid]가 10보다 크다는 정보만 가지고 있으면 mid가 10이 들어갈 수 있는 가장 왼쪽 위치일 수도 있다는걸 생각해야 합니다. 만약 예를 들어 A[3] = 6, A[4] = 6이라고 친다면 말한대로 10이 들어갈 수 있는 가장 왼쪽 위치가 mid, 즉 5번째가 됩니다. 그렇기 때문에 A[mid] > 10일 때에는 en = mid로 변경합니다.
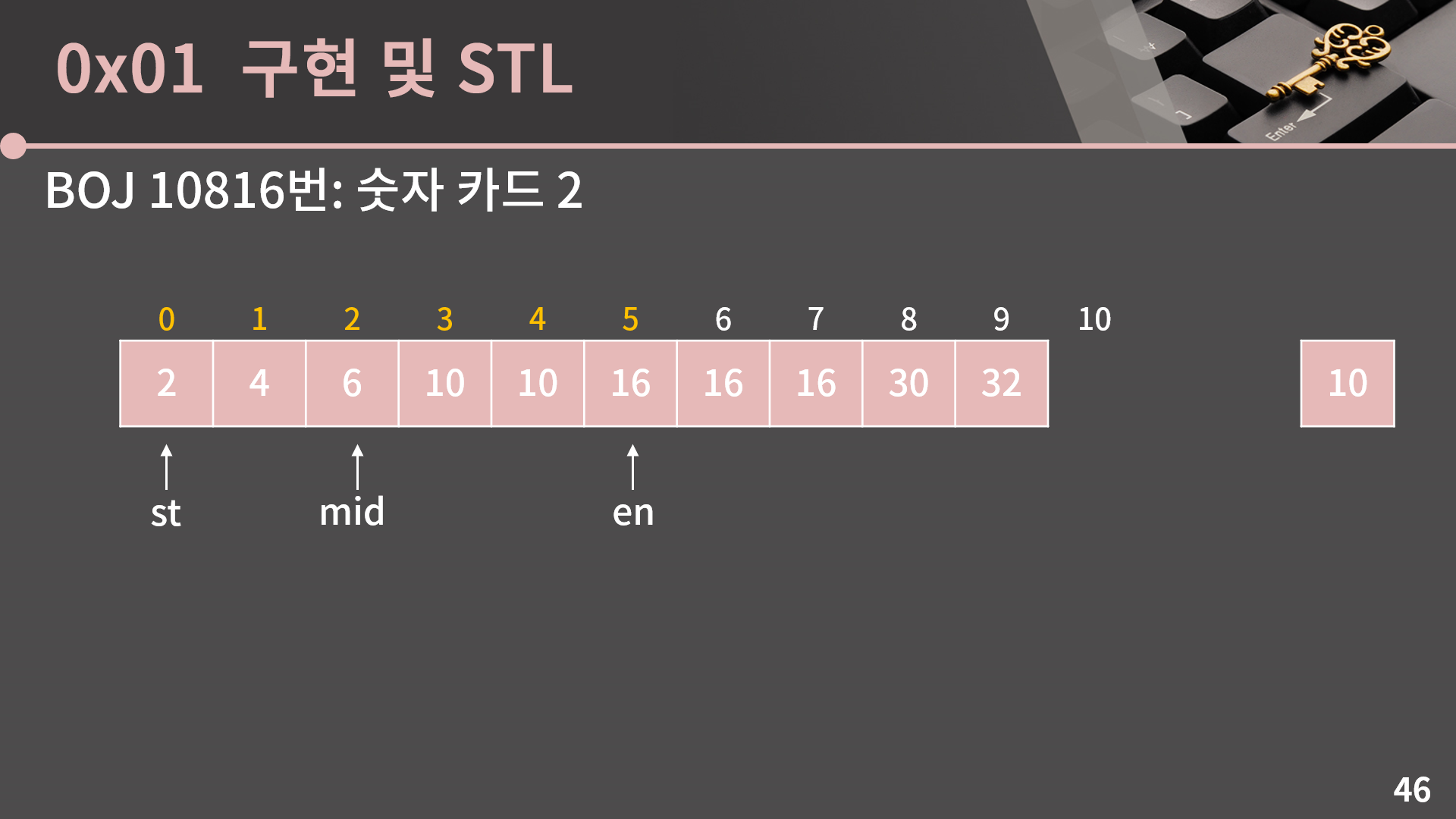
다시 mid = (st+en)/2로 계산합니다. 이번에는 st 혹은 en을 어떻게 옮겨야 할지 고민해봅시다.
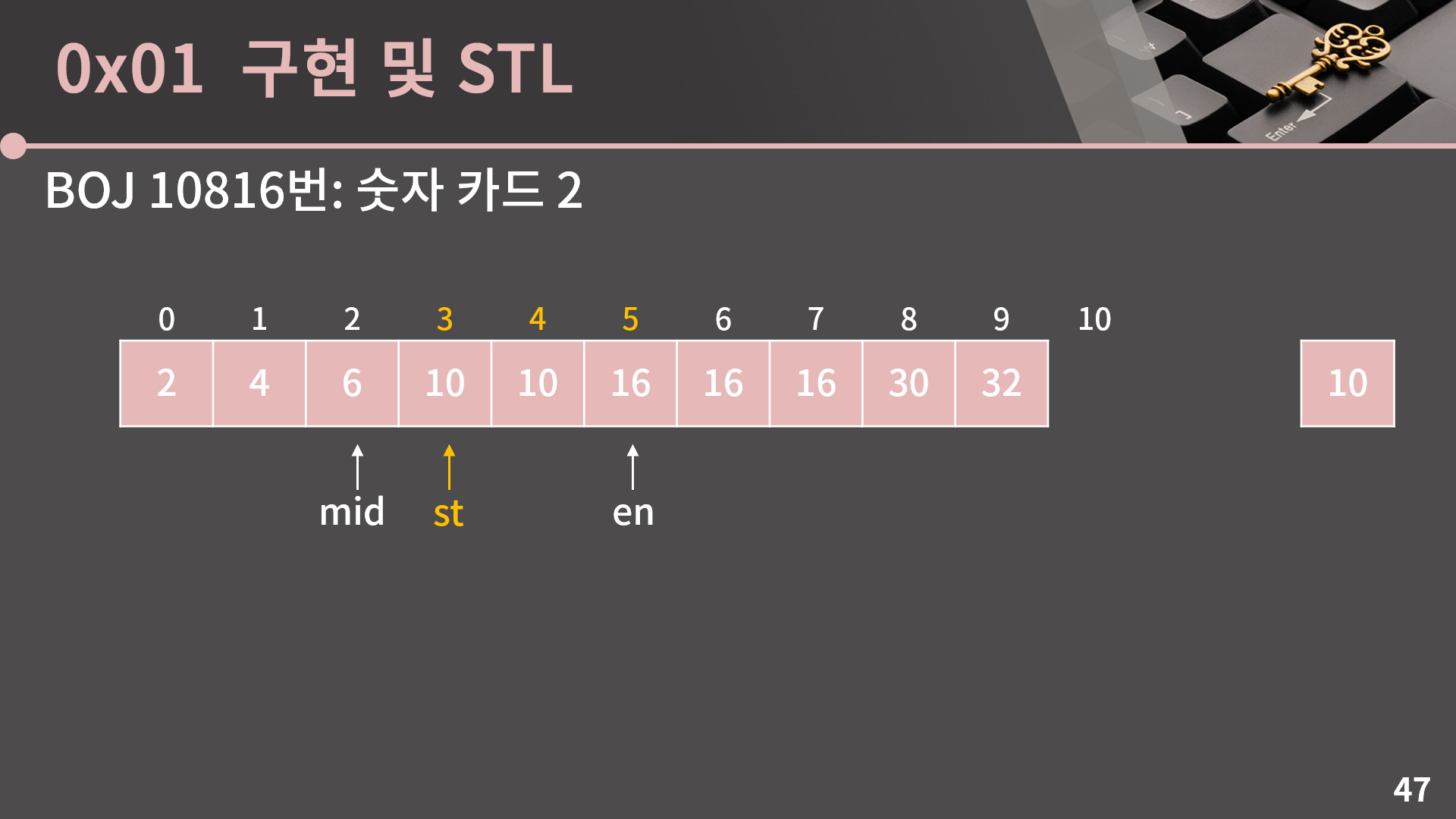
이번엔 A[mid] < 10입니다. 그러면 10이 들어갈 수 있는 가장 왼쪽 위치는 mid가 될 수 없고 mid보다 더 큰 인덱스들중 하나일거라 st = mid + 1로 변경합니다.
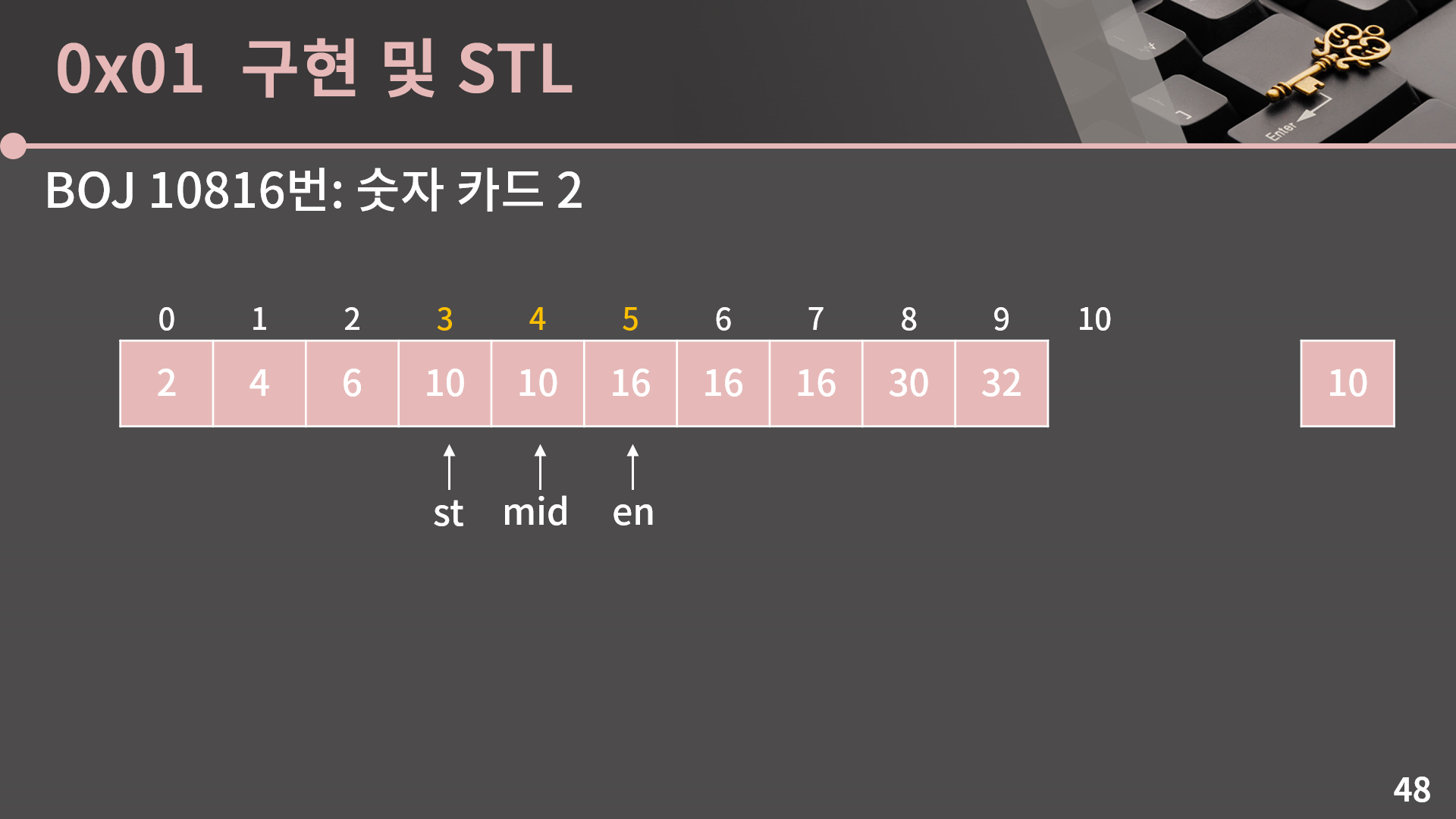
다시 mid = (st+en)/2로 계산합니다. 이번에는 A[mid] = 10입니다. 이렇게 A[mid]가 10보다 작은 경우, 같은 경우, 큰 경우를 다 보여드릴 수 있게끔 예시를 구성했습니다.
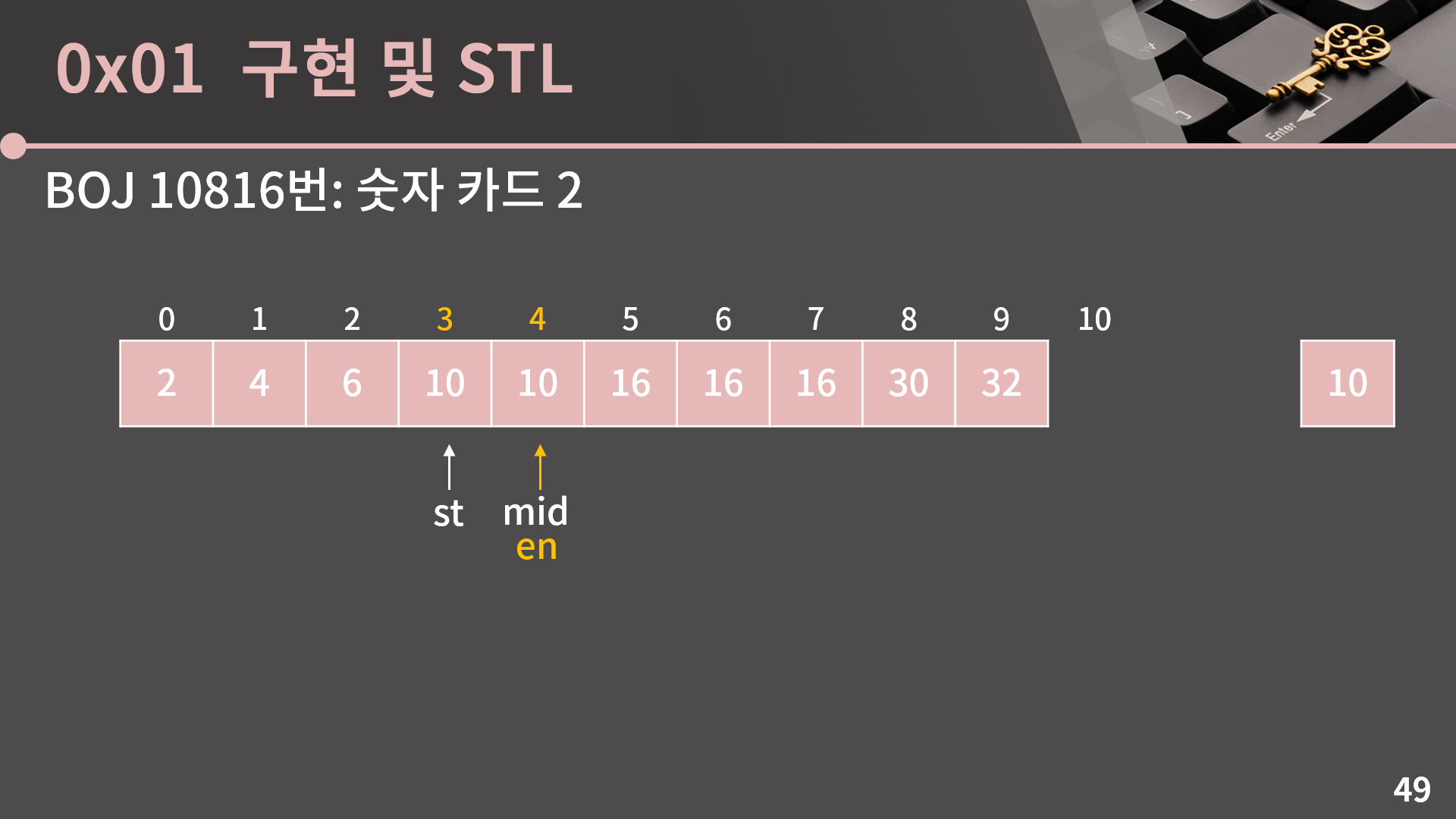
A[mid] = 10일 때에는 A[mid] > 10인 경우랑 똑같이 mid가 10이 들어갈 수 있는 가장 왼쪽 위치일 수도 있고, mid 이하일 수도 있습니다. 그래서 en = mid로 변경합니다.
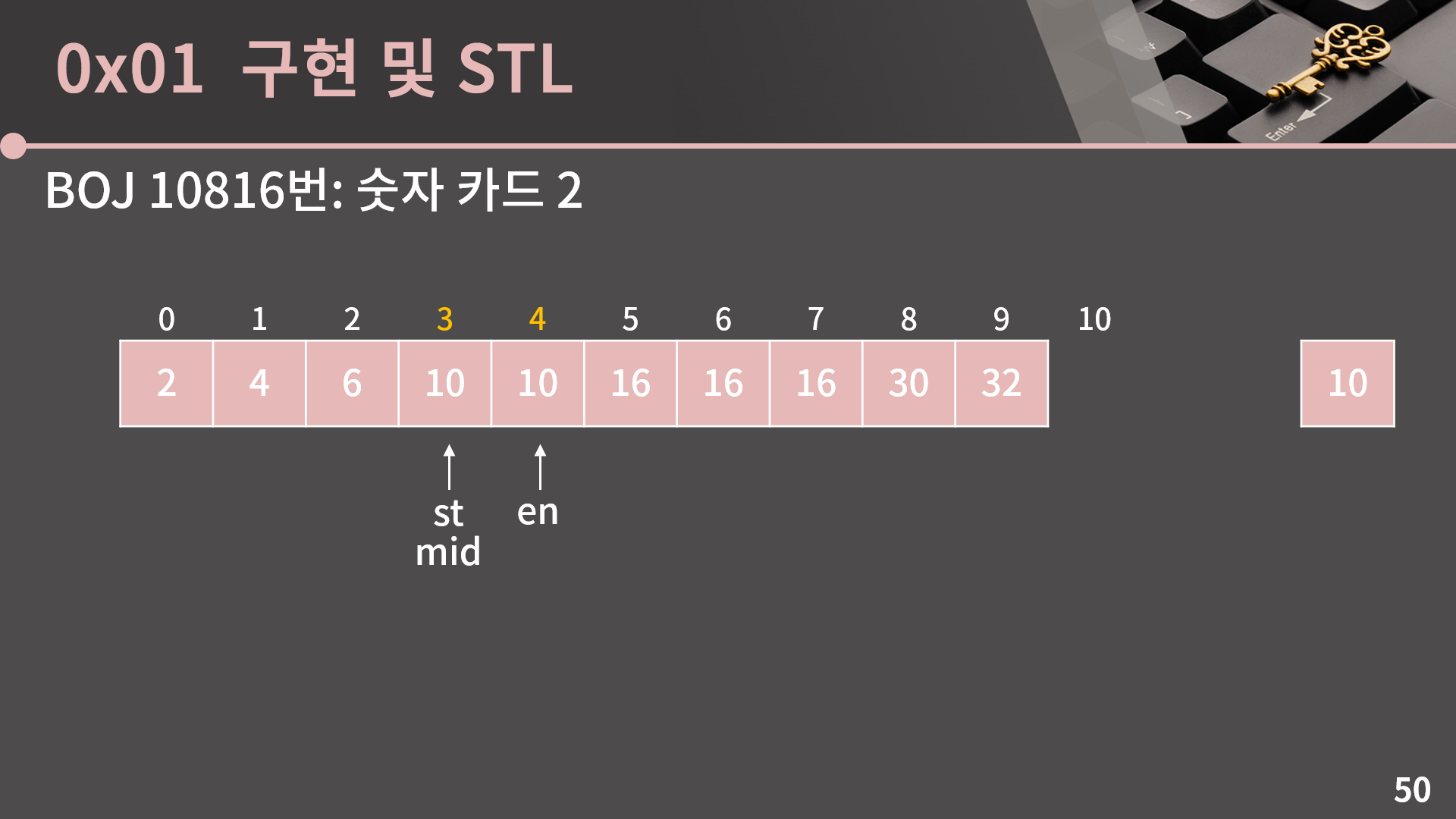
다시 mid = (st+en)/2로 계산합니다.
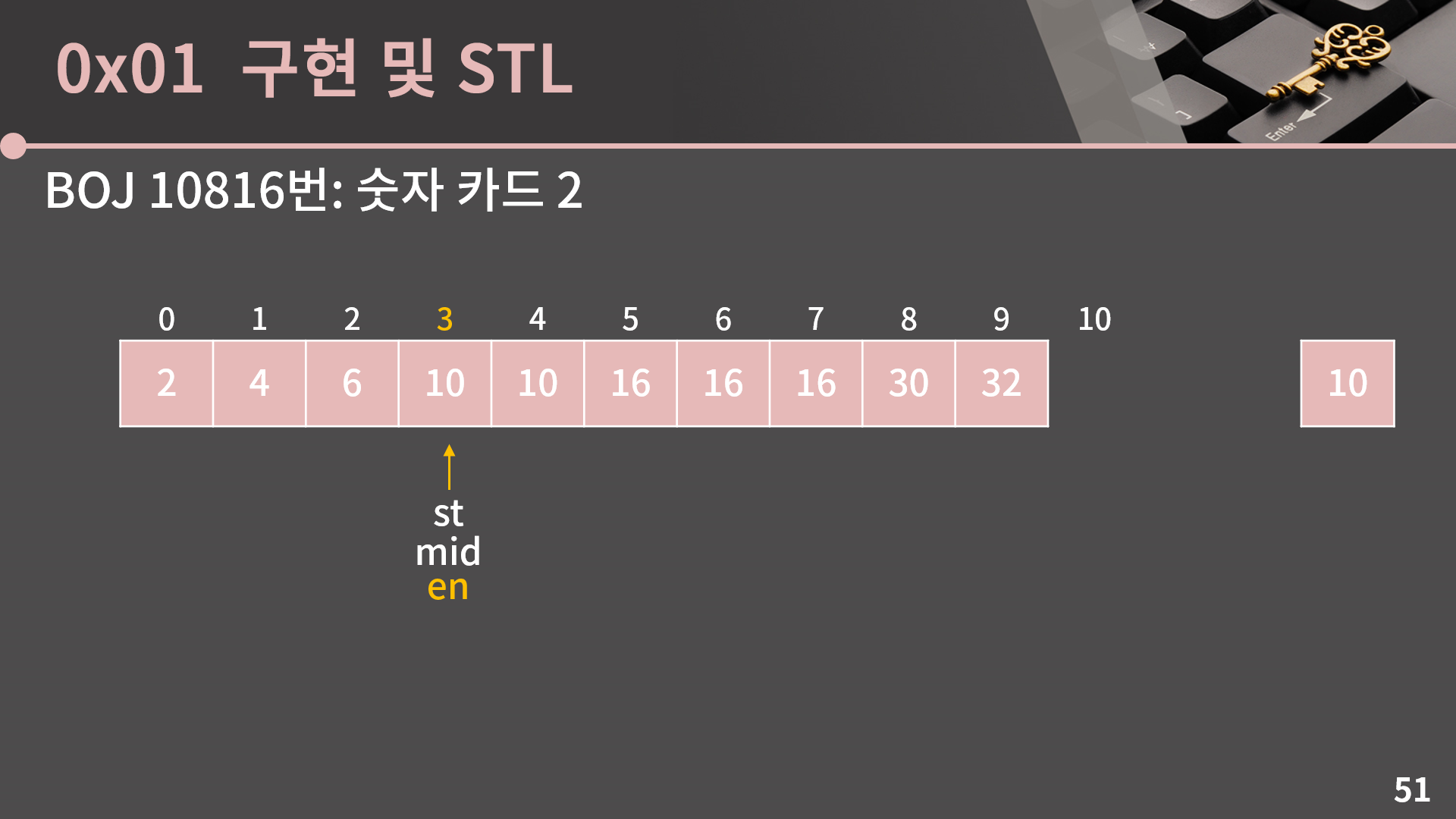
마찬가지로 A[mid] = 10이니까 en = mid로 변경합니다. 이렇게 st = en이 되어서 가능한 후보가 1개가 된 순간 우리는 답을 찾은거고 10이 들어갈 수 있는 가장 왼쪽 위치가 3번째란걸 알 수 있습니다.
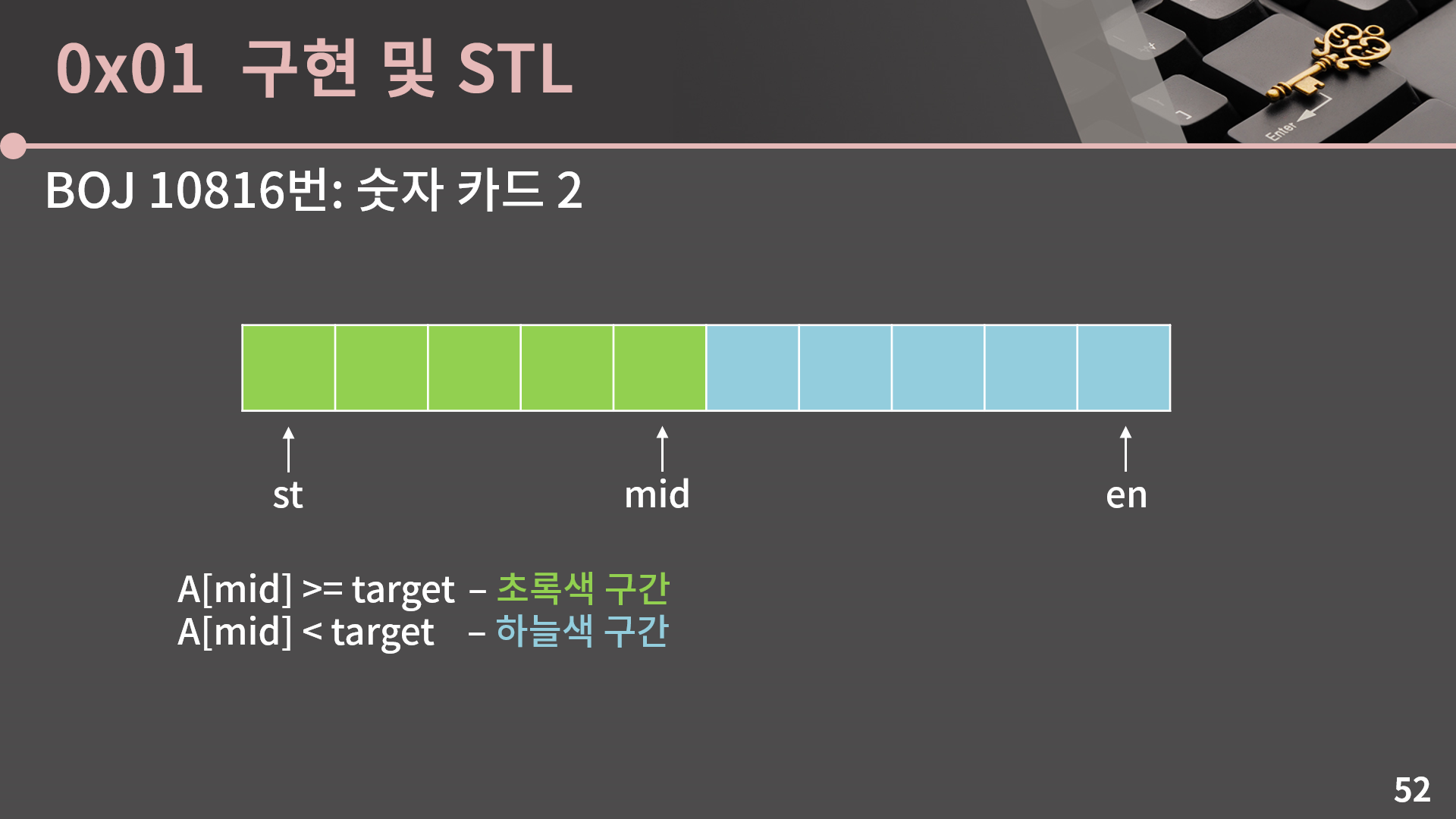
정리를 해보면, A[mid] >= target일 때에는 초록색 구간으로, en = mid가 됩니다. 반면 A[mid] < target일 때에는 하늘색 구간으로, st = mid + 1이 됩니다.

구현은 진짜 어려운게 없습니다. st와 en이 일치하지 않을 때 까지 while문으로 돌리면 되고 en의 시작점이 len이란건 주의를 할 필요가 있습니다.
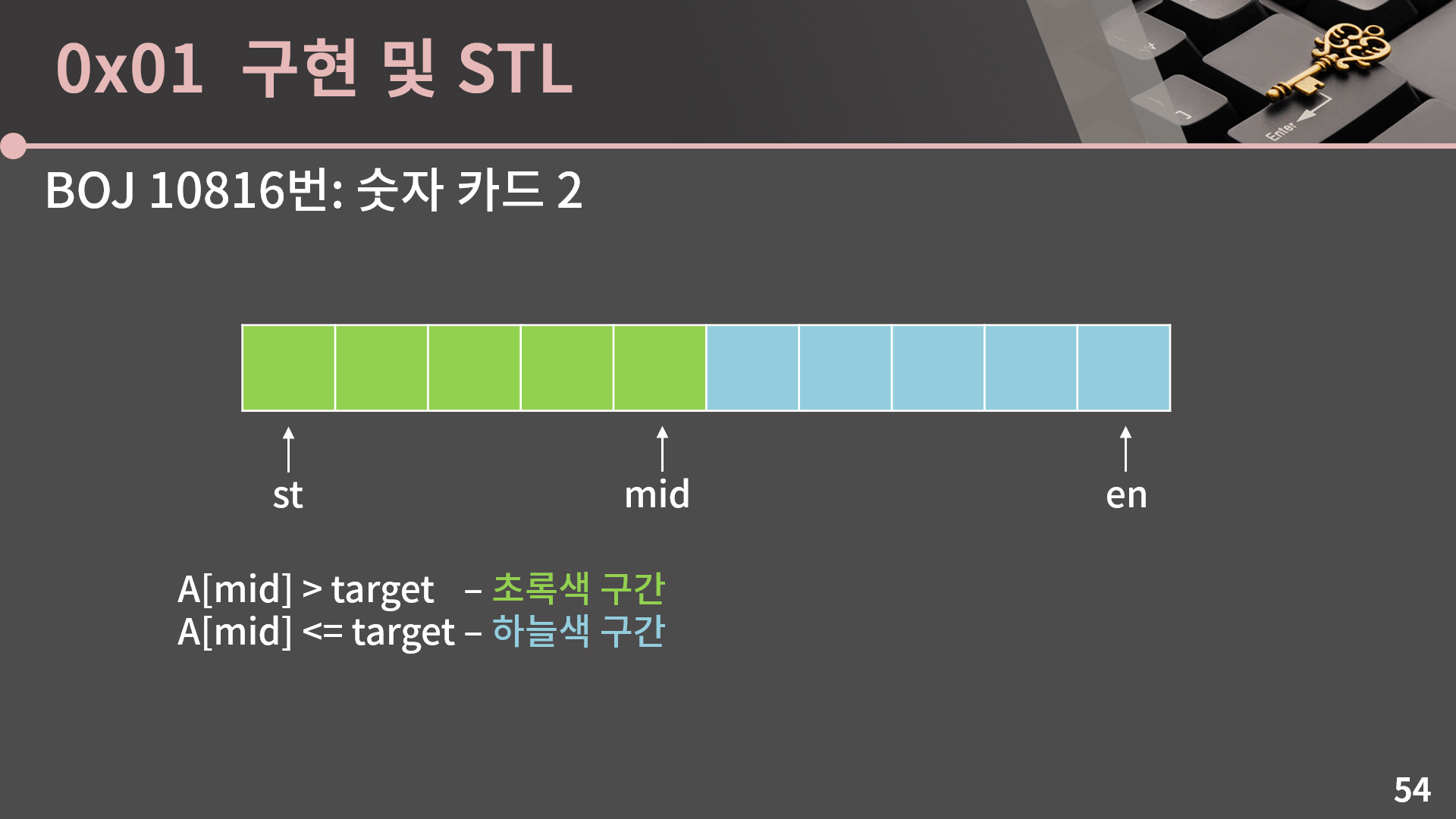
10이 들어갈 수 있는 가장 오른쪽 위치를 구하는 것도 비슷한 전개로 가능한데 과정을 다 풀어서 설명은 하지 않고 A[mid]와 target의 값에 따른 범위의 변화만 살펴보겠습니다. 가장 왼쪽의 위치를 구할때랑 형태는 비슷한데 A[mid] = target일 때에만 달라집니다. 가장 오른쪽 위치를 구할 때에는 A[mid] = target일 때 하늘색 구간이 됩니다. 왜냐하면 가장 오른쪽 위치는 target보다 큰 수가 최초로 나온 위치여서 그렇습니다.

여기서도 구현은 거의 똑같습니다. 설명은 생략하겠습니다. 이렇게 가장 왼쪽의 위치와 오른쪽의 위치를 구했으면 드디어 이 문제를 풀 수가 있습니다. 두 위치의 차이를 구하면 됩니다. 코드를 다 드렸으니 이 lower_idx, upper_idx를 그대로 가져와서 풀거나, 아니면 그냥 제 코드를 보지 않은 상태로 직접 lower_idx와 upper_idx를 짜서 한번 문제 풀이에 도전해보도록 합시다.

저는 lower_idx와 upper_idx를 제가 짠거니까 그대로 쓰겠습니다. lower_idx와 upper_idx를 그대로 가져오고 배열 a를 정렬한 후에 m번에 걸쳐 t를 입력받으면서 upper_idx와 lower_idx의 차이를 바로바로 출력하면 끝입니다. lower_idx와 upper_idx를 잘 이해만 했다면 풀만한 문제였습니다. 이제 좀 이분탐색에 대한 이해가 깊어진 것 같나요? (코드 링크)

그리고 STL에는 사실 lower_bound와 upper_bound라는 이름의, 거의 동일한 역할을 하는 함수가 있습니다. 두 함수가 반환하는 값은 lower_idx, upper_idx 함수에서 설명한거랑 완전 똑같이 target이 들어갈 수 있는 가장 왼쪽 위치와 오른쪽 위치를 말합니다. 그래서 STL을 써서 훨씬 쉽게 풀 수 있고, 사용법은 binary_search와 똑같이 첫 번째와 두 번째 인자로 범위를 주면 됩니다. 지금같은 경우에는 a, a+n이고 a가 만약 vector였다면 a.begin(), a.end()를 보내면 됩니다.
lower_bound, upper_bound의 반환 자료형은 a가 배열이라면 포인터, vector라면 iterator입니다. 그리고 equal_range라고 해서 lower_bound, upper_bound의 결과를 pair로 반환해주는 함수도 있습니다. (코드 링크)

이분탐색에서 주의할 점이 몇 개 있는데, 첫 번째로 이분탐색을 하고자 한다면 주어진 배열은 정렬되어 있어야 합니다. 만약 정렬되어 있지 않은 배열에서 binary_search, lower_bound, upper_bound 등을 사용하면 결과가 이상하게 나옵니다. 예를 들어 수가 있는데 없다고 나온다거나 할 수 있습니다. 저 함수들은 정렬이 되어있다고 가정을 하고 계산을 수행하기 때문에 당연한 일입니다. 그래서 배열이 정렬되어있지 않다면 sort 함수로 정렬한 후에 저런 함수들을 실행시켜야 합니다.
두 번째로 주의할거는 무한 루프에 관한건데 일단 그 전에 다른 얘기를 잠깐 해보겠습니다. 사실 정렬을 예로 들면 우리가 정렬 단원에서 비록 머지 소트와 퀵 소트 등의 코드를 살펴보긴 했었지만 제가 분명 코딩테스트로만 한정을 짓는다면 머지 소트니 퀵 소트니 하는걸 알 필요가 없다, 그냥 STL sort 함수를 가져다 쓰면 땡이다는 얘기를 했었습니다. 반면 이분탐색은 그렇지가 않습니다. 비록 binary_search, lower_bound, upper_bound라는 훌륭한 함수들이 있어서 주어진 정렬된 배열에서 특정 원소를 찾거나, 삽입할 위치를 찾거나 하는 문제에서는 직접 구현을 하지 말고 그냥 STL을 가져다 쓰는게 편하지만 대표적으로 Parametric search 처럼 STL가 도움이 안되고 직접 이분탐색을 수행해야 하는 경우가 있습니다. 그럴 때 논리적으로 엄청 큰 실수를 한건 아닌데 막상 돌리면 무한 루프에 빠지는 경우가 종종 있습니다. 이런게 어떤 상황인건지 한번 보여드리겠습니다.
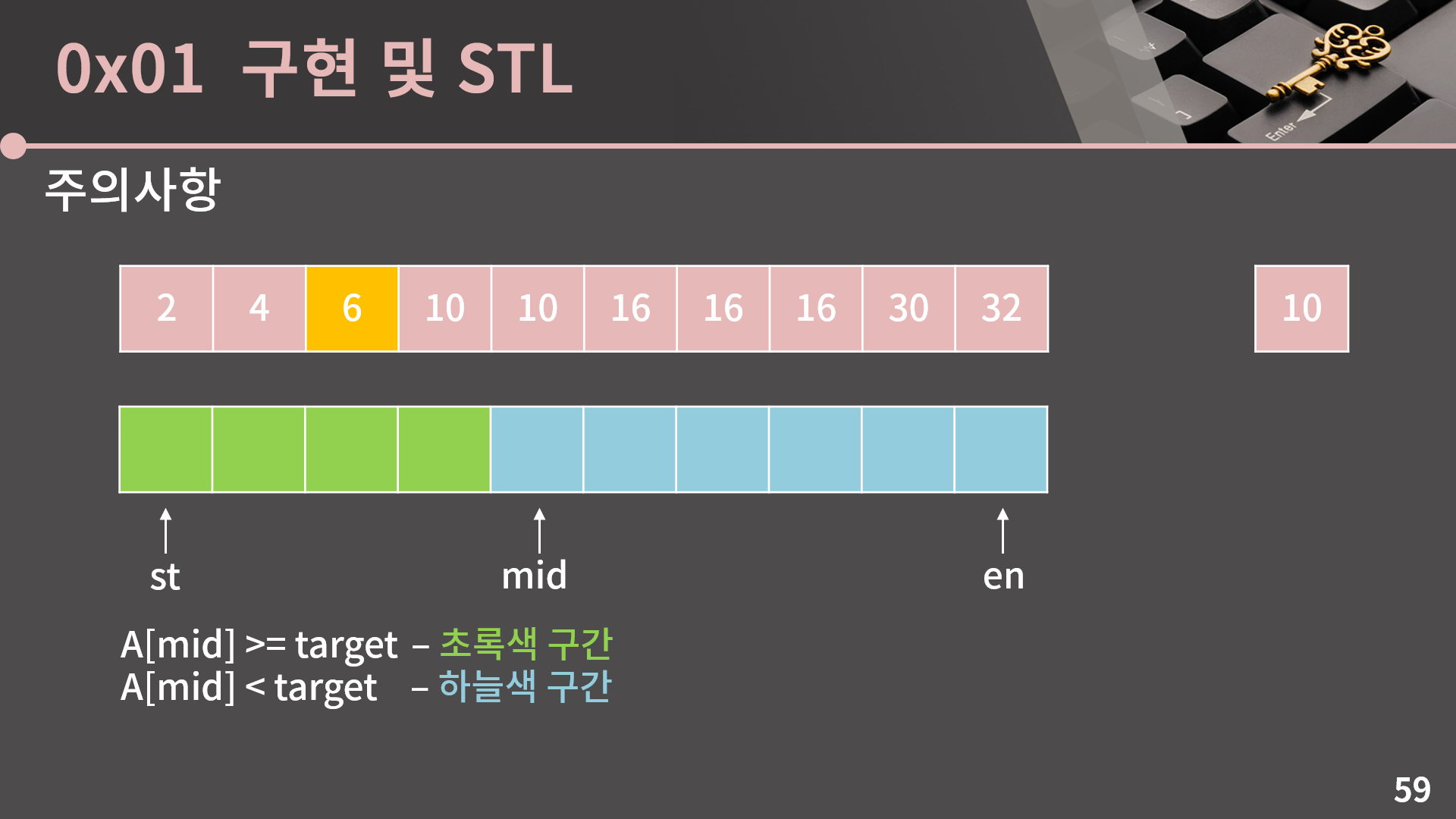
주어진 정렬된 배열에서 target보다 값이 작은 원소 중에서 가장 오른쪽에 있는 원소를 찾는 상황을 생각해봅시다. 지금 예시에는 6이 됩니다. 이 위치는 사실은 lower_bound 함수의 반환값에서 한 칸 왼쪽으로 가면 되긴 하지만, 직접 이분탐색으로 구현을 한다치면 늘 그랬듯이 st, mid, en을 잡고 A[mid]와 target의 비교 결과에 따라서 st와 en을 갱신해나갑니다. 그럼 구간은 아래의 그림과 같이 나누어집니다. 눈썰미가 좋으신 분이라면 이걸 보고 뭔가 조금 이전과는 그림이 다르다, 이거 뭔가 문제가 될 수도 있겠다라는 생각을 할 수 있을 것 같은데, 아무튼 바로 구현을 해보겠습니다.

뭐 이렇게 구현을 빠르게 호다닥 해보면 거의 비슷한 형태의 코드를 만들 수 있습니다. target이 a[0] 이하이면 -1을 반환해야 할테니 st의 시작이 -1이란건 충분히 납득가능합니다. 그리고 a[mid] < target일 때에는 st = mid로, a[mid] >= target 일 때에는 en = mid - 1로 두는 것도 이해가 가능합니다. 그런데 배열을 {2,7,11,11,16,19,22,22,22,32}로 놓고 func(16, 10)을 호출해서 16에 대한 이분탐색을 해보면 아주 놀랍게도 프로그램이 무한 루프에 빠집니다. 왜 무한 루프인가 생각을 해보면 아까 구간을 다시 가져올 필요가 있는데 보면 구간이 균등하지가 않습니다. 구간이 5개/5개로 나눠진게 아니라 4개/6개로 나눠졌습니다. 이건 적절한 mid 값을 택하지 못해서 발생하는 문제인거고, 단지 정확히 절반으로 나누지 않기 때문에 다소 비효율적이라는 것에서 끝나는게 아니라 아예 일부 값에 대해서 아예 무한 루프에 빠질 수 있습니다.
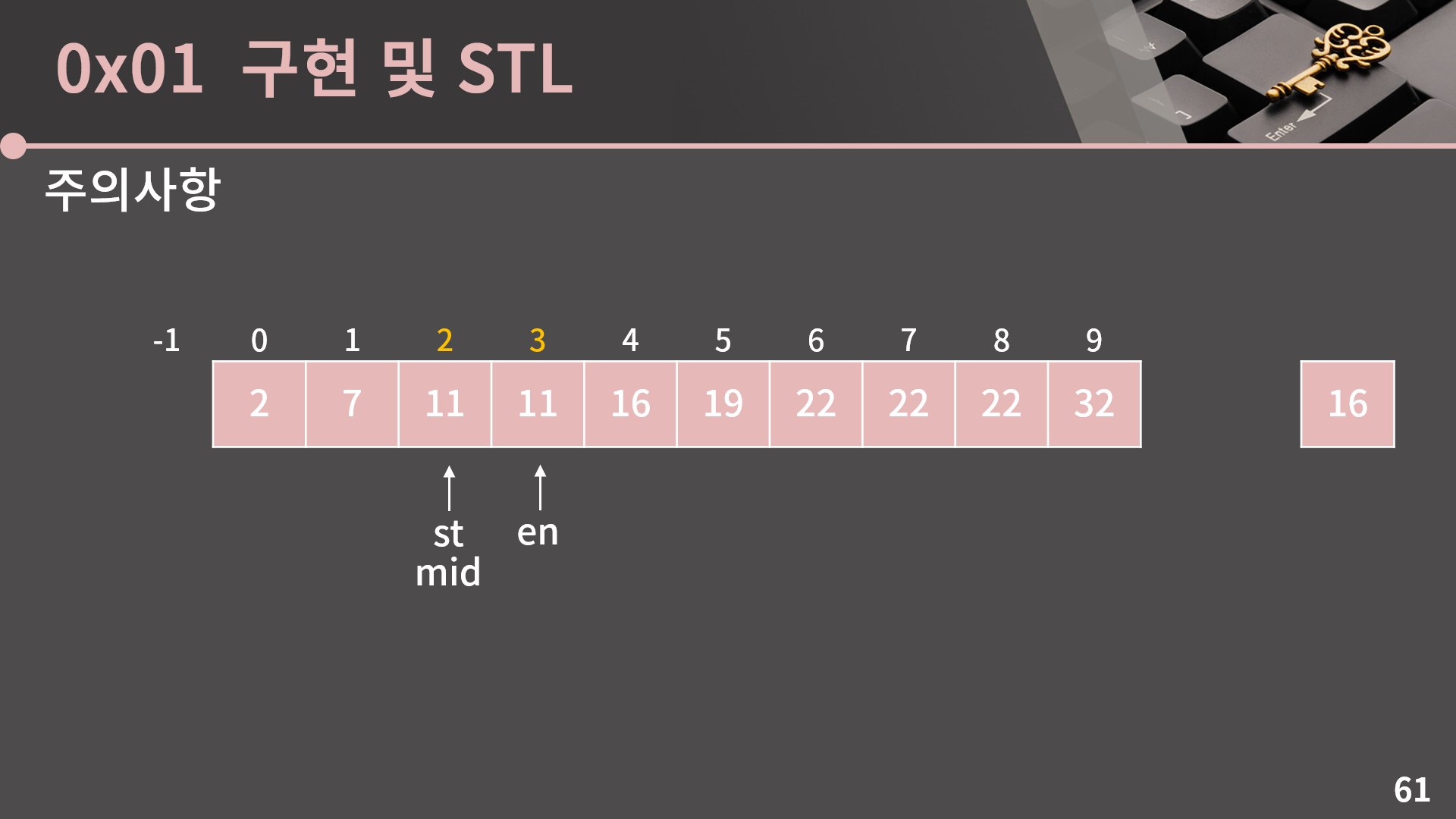
실제로 func(16, 10)을 호출했을 때 과정 중에 어떤 상황이 나오냐면 이렇게 st = 2이고 en = 3인 순간이 있습니다. 이 때 mid = (st+en)/2 = 2로 계산이 되고 a[mid] < target이니 st = mid가 됩니다. 그런데 mid = 2니까 여전히 st = 2입니다. 즉 st = 2, en = 3인 상황에서 무한 루프에 빠집니다.
이런 일을 막으려면 mid가 구간을 절반으로 잘 쪼갤 수 있도록 mid = (st+en+1)/2로 두면 됩니다. 그러면 st = 2, en = 3일 때 mid = 3을 택합니다. 이런 식으로 무한 루프에 빠지는걸 조심을 해야하고, 직접 이분탐색을 짰을 때 무한 루프에 빠지는게 걱정되면 st와 en이 1 차이날 때를 주의 깊게 확인해보면 됩니다.

이분탐색을 가지고 좀 써먹을 수 있는걸 하나 알려드리겠습니다. 바로 좌표 압축인데, 이 문제는 아마 혼자 풀기는 조금 벅찰 수 있습니다. 저희가 지금까지 푼 문제중에서는 당연히 제가 좌표 압축이 필요한 문제를 빼고 드렸으니 몰라도 됐었지만 나중에 문제를 풀다보면 입력값의 범위는 1에서 109 정도로 굉장히 큰데 그거를 배열 인덱스처럼 쓰고 싶을 수 있습니다. 그러면 뭔가 크기 순으로 번호를 0번부터 매기고 싶다는 생각이 들텐데 이런 일을 하는게 좌표압축입니다. 일단 BOJ 18870번: 좌표 압축 문제를 보고오겠습니다.
문제에서 수학적으로 써놓은게 조금 헷갈릴 수 있는데, 쉽게 말하면 중복을 제외하고 나보다 작은 수가 몇 개 있는지를물어보고 있습니다. 첫 번째 예시인 2, 4, -10, 4, -9를 보면 2에 대해서는 2보다 작은 수가 -10, -9 두 개가 있으니 2를 출력하고, 4를 보면 4보다 작은 수가 2, -10, -9 3개가 있으니 3을 출력하는 방식입니다. 코딩까지는 바라지 않고 그냥 풀이만 한번 떠올려봅시다. 이분탐색 단원임을 고려해서 보시면 좋을 것 같습니다.

일단 풀이를 한 번 말해보면 주어진 리스트를 먼저 정렬합니다. 그 다음에 중복 제거를 합니다. 여기서 중복 제거를 어떻게 하냐는 의문이 들 수 있습니다. 근데 여러분들은 이미 그 방법을 배웠습니다. 정렬 II 단원에서 연습 문제로 풀었던 BOJ 11652번: 카드 문제를 떠올려봅시다. 저 문제를 풀 때와 마찬가지로 정렬을 하고 나면 같은 수들끼리 모이는 성질질을 활용해 각 원소들에 대해서 자신의 앞에 있는 원소와 자신의 값이 다른 원소만 살리면 됩니다. 이걸 배열에서 제거 연산을 하는 식으로 구현하면 제거가 O(N)이고 제거가 최대 N-1번 발생할 수 있으니 O(N2)이 되니까 큰일납니다. 대신 새로운 배열을 하나 만든 후에 살아남은 원소만 뒤에 삽입하는 방법으로 구현을 해야 합니다. 제 강의를 충실하게 따라왔다면 이 중복 제거는 분명 할 수 있습니다. 지금 제 설명을 듣고도 중복 제거를 어떻게 한다는건지 이해가 안간다면 복습 차원에서 정렬 II 단원에 있는 정렬의 응용 파트를 한 번 다시 보고 오는게 좋겠습니다. 그러면 이렇게 정렬이 되어있고 중복이 제거된 배열을 얻은 후에는 그냥 이분탐색을 하면 끝입니다. 직접 구현을 해보시면 구현력을 늘리는데 있어서 되게 도움이 될거라 꼭 직접 구현을 해보시면 좋겠고 일단 제 코드를 소개하겠습니다.

tmp는 x를 정렬한 결과를 저장할 배열이고 uni는 unique라는 의미로, tmp에서 중복 제거가 된 결과를 저장할 배열입니다.17-20번째 줄이 중복 제거를 처리하는 부분인데, 제일 앞의 원소거나 자기 앞의 원소와 자신이 다르다면 uni에 넣습니다. 이러면 여러번 등장하는 원소 중에 가장 앞의 것만 uni에 들어갑니다. 마지막으로 lower_bound를 이용해서 iterator를 찾아서 uni.begin()을 빼주면 그게 바로 x[i]가 등장하는 인덱스입니다. iterator에 익숙하지 않다면 조금 어색할 수 있지만 그냥 iterator가 uni[4]를 가리키고 있다면 저 코드가 4를 출력한다고 생각하면 됩니다. (코드 링크)

그런데 놀랍게도 STL에 중복 제거를 수행해주는 함수가 있습니다 그래서 그걸 가져다쓰면 훨씬 편해지는데, 바로 unique라는 함수입니다. unique는 정렬된 배열에서 실행을 시켜야하고, 이렇게 말그대로 중복이 제거된 원소들을 앞으로 모아줍니다 그리고 뒤쪽에는 쓰레기 값들이 들어갑니다. 그런 다음 쓰레기 값이 시작되는 구간을 return합니다. 그러면 우리는 vector의 erase를 이용해서 뒤쪽을 날리면 됩니다. 그래서 조금 있다가 코드를 보시면 알겠지만 erase랑 unique를 섞어서 한 줄에 바로 중복 제거를 할 수 있습니다. 이번에는 STL을 이용한 코드를 보겠습니다.

코드에서 17번째 줄이 앞 슬라이드에서 설명한 그 내용이고 저렇게 중복 제거를 쉽게 할 수 있습니다. 앞으로 좌표 압축이나 중복 제거가 필요할 때 지금 배운 내용을 떠올리시면 좋겠습니다. (코드 링크)

이제 여러분은 배열에서 특정한 수를 찾는 문제나, 특정한 수가 몇 개 있는지를 물어보는 문제나, 좌표 압축 중복 제거 이런거는 STL을 써서 쉽게 풀 수 있기 때문에 그런 문제가 코딩테스트에서 나온다면 감사하게 점수를 챙겨가야 합니다. 그런데 이분탐색이 그렇게 호락호락하지는 않습니다. 과연 이분탐색이 어떤 식으로 응용이 될 수 있는지 문제를 보면서 알아보겠습니다. BOJ 2295번: 세 수의 합 문제를 확인해봅시다.
와 이거 문제를 보면 상당합니다. 굉장히 어렵게 느껴질 것 같습니다. 쉽지 않지만 한걸음씩 가봅시다. 일단 문제의 내용을 정리해보면 a[i] + a[j] + a[k] = a[l]을 만족하는 a[l] 중에서 최댓값을 구하라고 하고 있습니다. 가장 간단하게 떠올릴 수 있는 풀이는 O(N4) 풀이일텐데 O(N4) 풀이 정도는 충분히 떠올릴 수 있을거라 믿습니다.

O(N4) 풀이는 i, j, k, l에 대한 4중 for문을 돌면 해결이 가능하고 굳이 코딩은 안하겠습니다. 여기서 일단 O(N3lgN)까지 떨궈보는걸 목표로 해봅시다. O(N3lgN)까지도 그럭저럭 떠올려볼만 할 것 같은데, 어떻게 해결할 수 있을까요?

O(N3lgN)으로 풀려면 i, j, k에 대한 3중 for문을 돌리고, 배열 a 안에 a[i]+a[j]+a[k]가 있는지 이분탐색으로 찾아나서면 됩니다. 이런 테크닉을 처음 본 분이라면 이런 접근이 가능하구나 하고 굉장히 신기해할 것 같습니다. O(N4)에서 O(N3lgN)으로 간게 꽤 대단한 진전이긴 한데 안타깝게도 N = 1000이기 때문에 여전히 시간 내로 통과하기에는 부족합니다. N = 1000이면 O(N2)이나 O(N2lgN) 정도의 시간복잡도가 통과하겠다는 짐작을 할 수 있는데, 결론적으로 말하면 이 문제에는 O(N2lgN)의 풀이가 존재합니다. 그 풀이를 알아내기 위해서는 조금 식을 변형할 필요가 있는데, 미리 a에서 두 원소의 합을 다 묶어놓은 배열 two를 만들어놨다고 해보겠습니다. 예를 들어서 a가 {1, 4, 6}이라고 하면 two는 {1+1,1+4,1+6,4+4,4+6,6+6} = {2,5,7,8,10,12}입니다.

그러면 식이 two[m] + a[k] = a[l]로 변경될 수 있습니다. 이 two 배열은 O(N2)에 만들 수 있습니다. 그러면 이 식으로부터 저희가 고대하던 O(N2lgN) 풀이를 만들어낼 수 있습니다.

대망의 그 풀이는 바로 k, l에 대한 2중 for문을 돌리고 a[l]-a[k]가 배열 two 안에 있는지 확인하는 방법입니다. two의 길이는 N2인데 lg(N2)은 2lgN이어서 O(N2lg(N2)) = O(N2 * 2lgN) = O(N2lgN)입니다. 방법을 다 알려드렸으니 구현을 해보도록 합시다. 가능하면 STL을 써서 구현합시다.
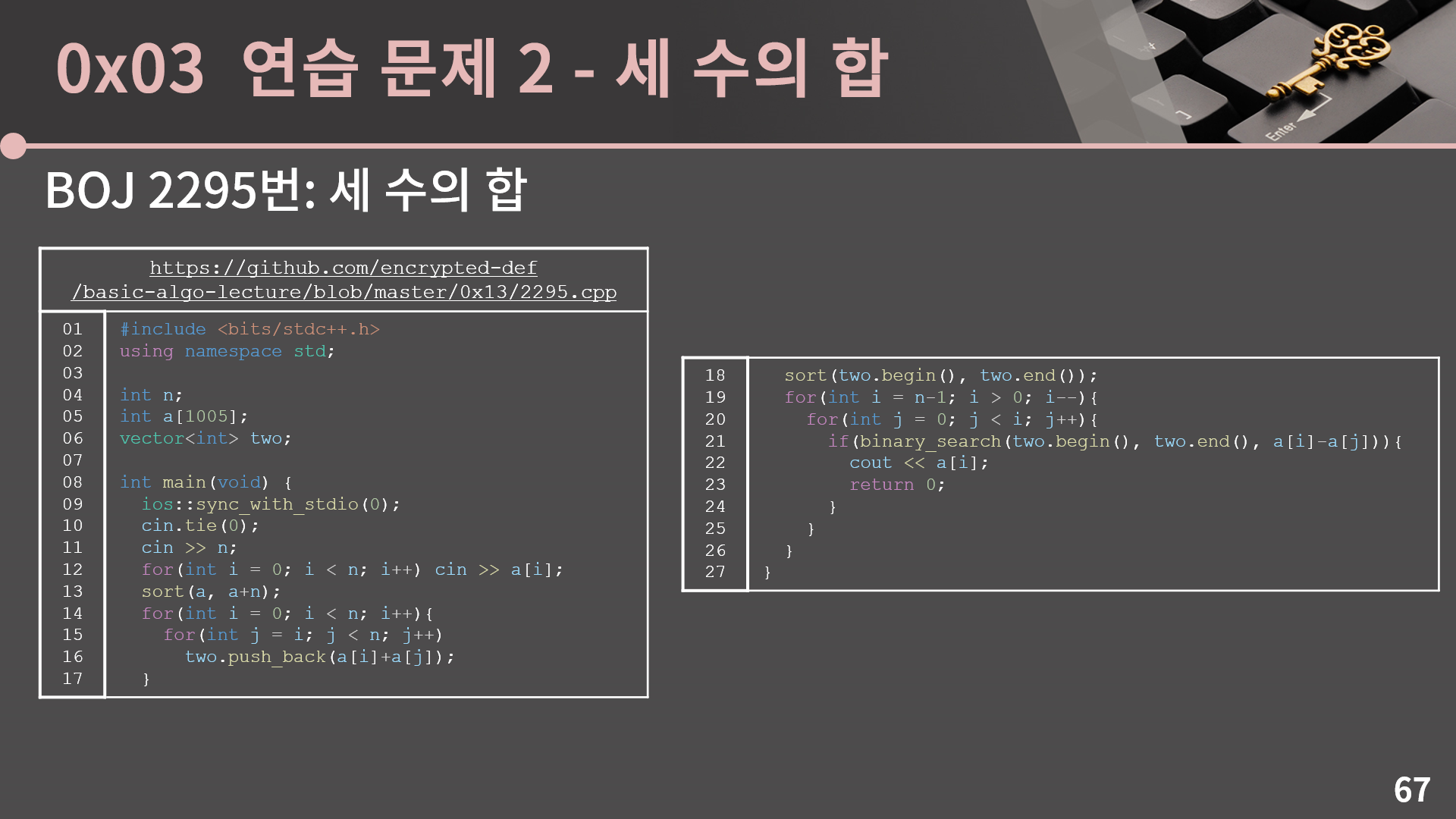
풀이의 약간의 어려움에 비해 코드는 별로 길지 않습니다. 14-17번째 줄처럼 two 배열을 잘 채우고, 18번째 줄에서 정렬을 하고, a[i] - a[j] 값이 two에 있는지를 확인하면 됩니다. a도 정렬을 해뒀고 값이 큰 a[i]부터 확인을 하기 때문에 발견을 하면 바로 출력하고 종료하면 되고, 답이 무조건 있다고 했으니 이렇게 짜면 끝입니다. 배열 a는 사실 정렬을 안해도 답을 낼 수 있지만 정렬을 하면 이렇게 a[i]를 발견하자마자 끝낼 수 있다는 장점이 있긴 합니다.
이렇게 뭔가 2개의 값을 묶은 후 어느 한쪽의 값을 이분탐색으로 찾아서 시간복잡도를 낮추는 아이디어는 이분탐색 관련 응용문제에서 핵심적으로 많이 나오는거라 다른 연습 문제들을 풀면서 계속 익혀보면 됩니다. 이 문제는 사실 수를 중복으로 쓸 수 있다는 점 때문에 구현이 좀 편했는데 중복이 허용되지 않으면 상당히 구현이 복잡해집니다. 이건 다른 문제를 풀면서 직접 경험해보면 되겠습니다. (코드 링크)

드디어 끝이 보입니다. 마지막 주제는 Parametric Search입니다. 한글로는 매개 변수 탐색이라고 부르기도 하는데, 이상하게 매개 변수 탐색이라는 이름보다 parametric search가 더 익숙해서 그냥 parametric search라고 쓰겠습니다. 이 알고리즘 이름이 이전에 나온 적이 있는데, 그리디 단원에서 잘못된 그리디 얘기를 하면서 제시한 어떤 문제가 parametric search로 풀린다는 얘기를 했었습니다.
parametric search는 사실 꽤 어렵습니다. 무엇보다도 애초에 문제가 parametric search 라는걸 눈치채는 것 자체가 어렵고, DP나 그리디나 뭐 이런 것들이랑 결합을 해서 나오는 경우도 빈번합니다. 그래서 개념을 설명하고 방법도 알려드리긴 하지만 시간을 엄청 들여서 parametric search를 공부하는게 아닌 이상에야 내가 본 적이 없는 형태의 parametric search 문제가 나왔을 때 솔직히 말해서 한 99%의 확률로 아마 풀이를 못 잡아낸다고 보시면 됩니다. 그렇기 때문에 어떻게 보면 과감하게 배제를 하는 것도 전 괜찮다고 생각을 합니다. 그거는 현재 지금 강의를 보고 계신 여러분의 시간적 상황과 느끼는 난이도 등을 생각해서 각자 결정을 하시면 됩니다.
뭐 이렇게 겁을 잔뜩 드렸는데 아니 그래서 parametric search가 뭐냐하면 조건을 만족하는 최소/최댓값을 구하는 문제, 즉 최적화 문제를 결정 문제로 변환해 이분탐색을 수행하는 방법입니다. 아마 무슨 소리인가 싶을겁니다. 이해가 안가는게 정상이고, 그냥 예시를 하나 보는게 제일 쉬운 이해법입니다.

parametric search의 스테디셀러급 문제인 BOJ 1654번: 랜선 자르기 문제를 보겠습니다. 일단 풀어보려고 시도를 하면 아마 전혀 감이 안올 것 같습니다. 어거지로 랜선 길이 다 합한 다음에 K로 나눈 값을 구해서 그걸 랜선 길이로 둔 다음에 자투리가 남으면 랜선 길이를 1씩 줄여본다거나 아니면 다른 종류의 그리디 알고리즘을 생각해볼 수 있겠지만 다 안됩니다. 그럼 도대체 어떻게 해야하는가 생각해볼 때 아까 parametric search에서 최적화 문제와 결정 문제라는 표현을 썼었습니다. 그게 이 문제에서 어떻게 적용되는지를 보겠습니다. 이 문제의 상황은 N개를 만들 수 있는 랜선의 최대 길이를 구하는 최적화 문제입니다. 이걸 결정 문제로 바꾸면 반대로 우리가 구해야 하는 답이 인자로 들어가고, 조건의 참/거짓 여부를 판단하는 문제로 만들 수 있습니다.

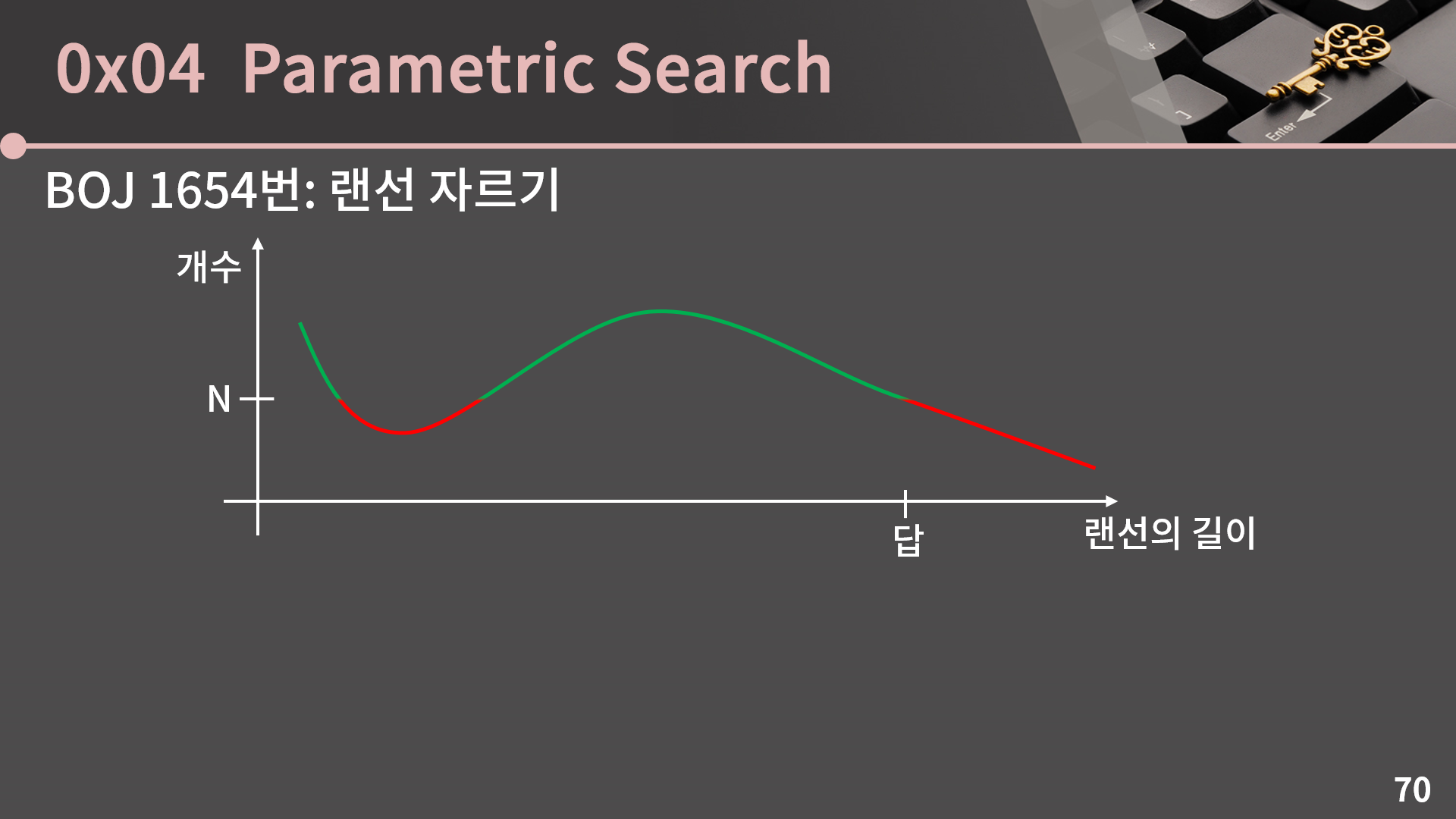
랜선의 길이가 줄어들수록 개수가 많아지는건 당연한 사실이니까 간단하게 그래프를 그려보면 랜선의 길이가 x축에 놓이고 개수가 y축에 놓입니다. 그리고 그래프는 x가 커질수록 y가 감소하는 형태입니다. 그래프에서 답은 표시한 지점으로, 개수가 N개 이상인 지점들 중에서 가장 길이가 긴 곳입니다. 이 답을 기점으로 왼쪽은 개수가 N 이상이고 오른쪽은 N 미만입니다. 랜선의 길이는 최소 1, 최대 231-1인데, 우리는 여기서 이분탐색으로 답을 빠르게 찾아낼 수 있습니다.

이렇게 st, mid, en을 놓고 범위를 줄여가며 답을 찾아봅시다. 랜선의 길이가 mid일 때 랜선이 N개 미만입니다. 그러면 mid 이상은 절대 답이 될 수 없으니 en = mid - 1로 바꿉니다. 만약 랜선의 길이가 mid일 때 랜선이 N개 이상이었다면 st = mid로 바꿔주면 됩니다. 이렇게 최대 길이를 구해야하는 문제에서 랜선의 길이가 X일 때 조건을 만족하는지 확인하는 문제로 변환해서 풀이를 해낼 수 있습니다. 이 문제의 경우, 랜선의 길이를 X로 두고나면 조각의 개수를 구하는건 O(K)이고 랜선의 길이로 가능한 범위는 231이어서 시간복잡도는 O(log(231)K) = O(31K)입니다.
여기서 주의해야하는건, 지금처럼 이분탐색을 수행할 변수를 가지고 함수를 세웠을 때 그 함수가 감소함수거나 증가함수여야 합니다. 만약 이 그래프처럼 함수가 감소 혹은 증가함수 형태가 아니라 뒤죽박죽이면 이분탐색 자체가 불가능합니다. 그래서 parametric search를 할 때에는 최적화 문제를 결정 문제로 바꿀 수 있는지 생각하고 그 결정 문제로 얻어낸 함수가 감소 혹은 증가함수인지를 따져봐야 합니다. 문제에서 최소 혹은 최대 얘기가 있고 범위가 무지막지하게 크거나, 뭔가 시간복잡도에서 값 하나를 로그로 어떻게 잘 떨구면 될 것 같을 때 parametric search 풀이가 가능하지는 않을까 고민을 해볼 필요가 있습니다. 이제 구현을 해보겠습니다.

solve 함수는 길이가 x일 때 랜선이 n개 이상일 수 있는지를 계산하는 함수입니다. solve 함수에서 cur가 long long이어야 하는건 굳이 설명을 안해도 눈치챌 수 있어야 합니다.
이분탐색을 할 때 st = 1, en = 231-1에서 시작하고 저 0x7fffffff가 231-1을 16진수로 나타낸 값입니다. 둘의 자료형이 왜 long long이냐면, 사실 st와 en 모두 int 범위 안에 있긴 합니다. 그런데 mid를 (st+en+1)/2로 계산할 때 st+en이 int 범위를 넘어갈 수 있습니다. 그래서 그냥 마음 편하게 st, en, mid 모두 long long으로 뒀습니다.
그리고 이번에도 재밌는게, mid = (st+en+1)/2로 둬야 무한 루프에 빠지지 않습니다. mid = (st+en)/2로 두면 전에 본 것 처럼 st와 en이 1 차이날 때 st가 계속 값이 똑같아버릴 수 있습니다.
저는 이런식으로 결정 문제를 계산하는 코드를 바깥에 solve라는 이름으로 빼두고 구현하는걸 선호합니다. 그러면 코드의 구조가 이렇게 좀 예쁘게 나오는 것 같습니다. 이건 각자 스타일이니까 알아서 편한대로 하시면 됩니다. (코드 링크)

이분탐색도 이렇게 끝이 났습니다. 업다운 게임을 할 때 까지만 해도 이렇게 이분탐색이 복잡한건지 몰랐겠지만 아무튼 좀 심오한 무언가를 담고 있습니다. 응용이 빡세게 들어가거나 parametric search 개념이 들어간 문제는 상황에 따라 과감하게 포기를 해도 되지만, 그냥 단순하게 배열에서 원소 찾기, 개수 찾기를 수행하는 문제는 STL을 써서 쉽게 해결할 수 있도록 연습을 해두시면 의외로 남들이 어려워하거나, STL을 안쓰고 직접 구현하느라 실수를 계속 저지를동안 빠르게 통과할 수 있어서 좋습니다. 그럼 다음 시간에 보겠습니다.
'강좌 > 실전 알고리즘' 카테고리의 다른 글
| [실전 알고리즘] 0x16강 - 이진 검색 트리 (33) | 2021.11.06 |
|---|---|
| [실전 알고리즘] 0x15강 - 해시 (30) | 2021.09.27 |
| [실전 알고리즘] 0x14강 - 투 포인터 (32) | 2021.08.20 |
| [실전 알고리즘] 0x12강 - 수학 (41) | 2021.06.30 |
| [실전 알고리즘] 0x11강 - 그리디 (39) | 2021.02.17 |
| [실전 알고리즘] 0x10강 - 다이나믹 프로그래밍 (70) | 2021.01.28 |