
안녕하세요, 이번에는 플로이드 알고리즘을 다루겠습니다. 이제 최단경로 알고리즘인 플로이드, 다익스트라 알고리즘만 다루고 나면 나름 길었던 그래프 파트가 끝납니다.

목차는 눈으로 한 번 보고 가겠습니다. 구현과 경로 복원 방법 모두 BOJ에 있는 문제를 가지고 직접 풀어볼거라 별도로 연습 문제 챕터는 두지 않았습니다.
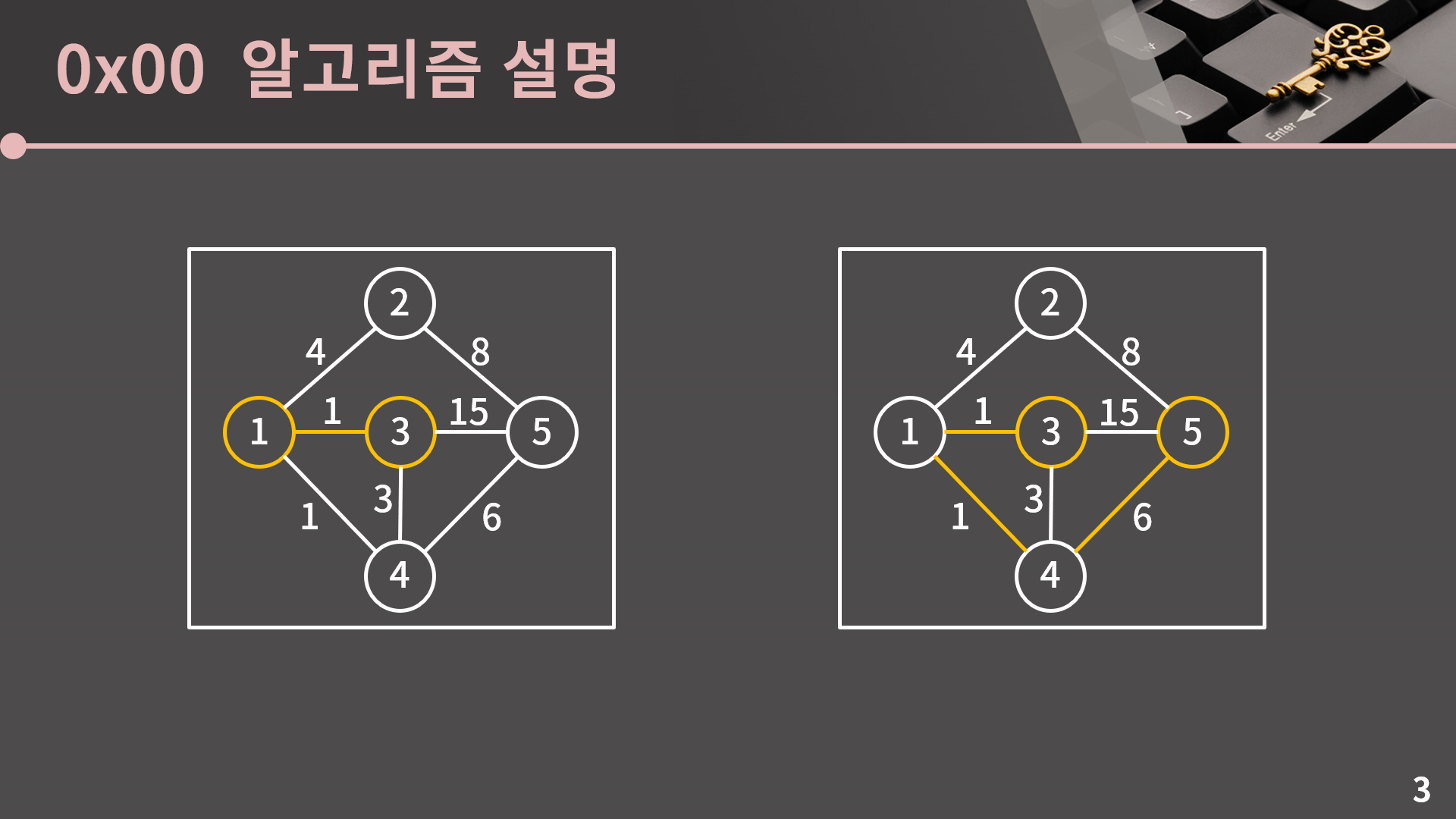
우리는 이미 직관적으로 그래프에서의 최단 거리라는 개념을 알고 있지만 그래도 한 번 짚고 넘어가겠습니다. 전 단원에서 그래프를 예쁘게 잘 만들어놓은 것 같아 다시 재활용했습니다. 주어진 그래프에서 간선 옆에 적힌 값들은 간선의 거리를 의미합니다. 혹은 비용이라고 부르기도 하는데 같은 의미입니다. 아무튼 이런 상황에서 1에서 3으로 가는 최단 거리는 1입니다. 3에서 5로 가는 최단 거리는 8입니다. 비용이 15인 간선을 이용하면 한 번에 갈 수 있지만 15인 간선을 활용하는 것 보다 3에서 1로, 1에서 4로, 4에서 5로 돌아가는 것이 이득이기 때문입니다.

그리고 플로이드 알고리즘은 오른쪽 테이블과 같이 주어진 그래프에서 모든 정점 쌍 사이의 최단 거리를 구해주는 알고리즘입니다. 주어진 그래프는 무방향 그래프이지만 그래프가 방향 그래프이건, 무방향 그래프이건 상관이 없습니다. 또 간선의 값이 음수여도 잘 동작하지만 음수인 사이클이 있으면 문제가 생깁니다. 다만 애초에 간선의 값이 음수인 상황이 딱히 일반적이지 않기 때문에 음수와 관련된 설명은 생략하겠습니다.
이전에 관련 내용을 다룬 적이 없다면 도대체 어떻게 주어진 그래프에서 임의의 시작점으로부터 임의의 도착점까지의 최단 거리를 모두 구할 수 있는지 전혀 감이 오지 않는 것이 정상입니다. 관련 내용을 배운 적이 없음에도 불구하고 방법이 쉽게 떠오른다면 지금 강의를 들을 때가 아니라 대학원에 진학하셔서 우리나라를 빛내주세요ㅎㅎ..
다만 다행히 플로이드 알고리즘은 구현이 아주 쉬운 편에 속합니다. 그렇기에 이전 강에서 높은 구현 난이도에 고통받았다면 이번에는 조금이나마 더 편한 마음으로 강의를 들을 수 있지 않을까 싶습니다.
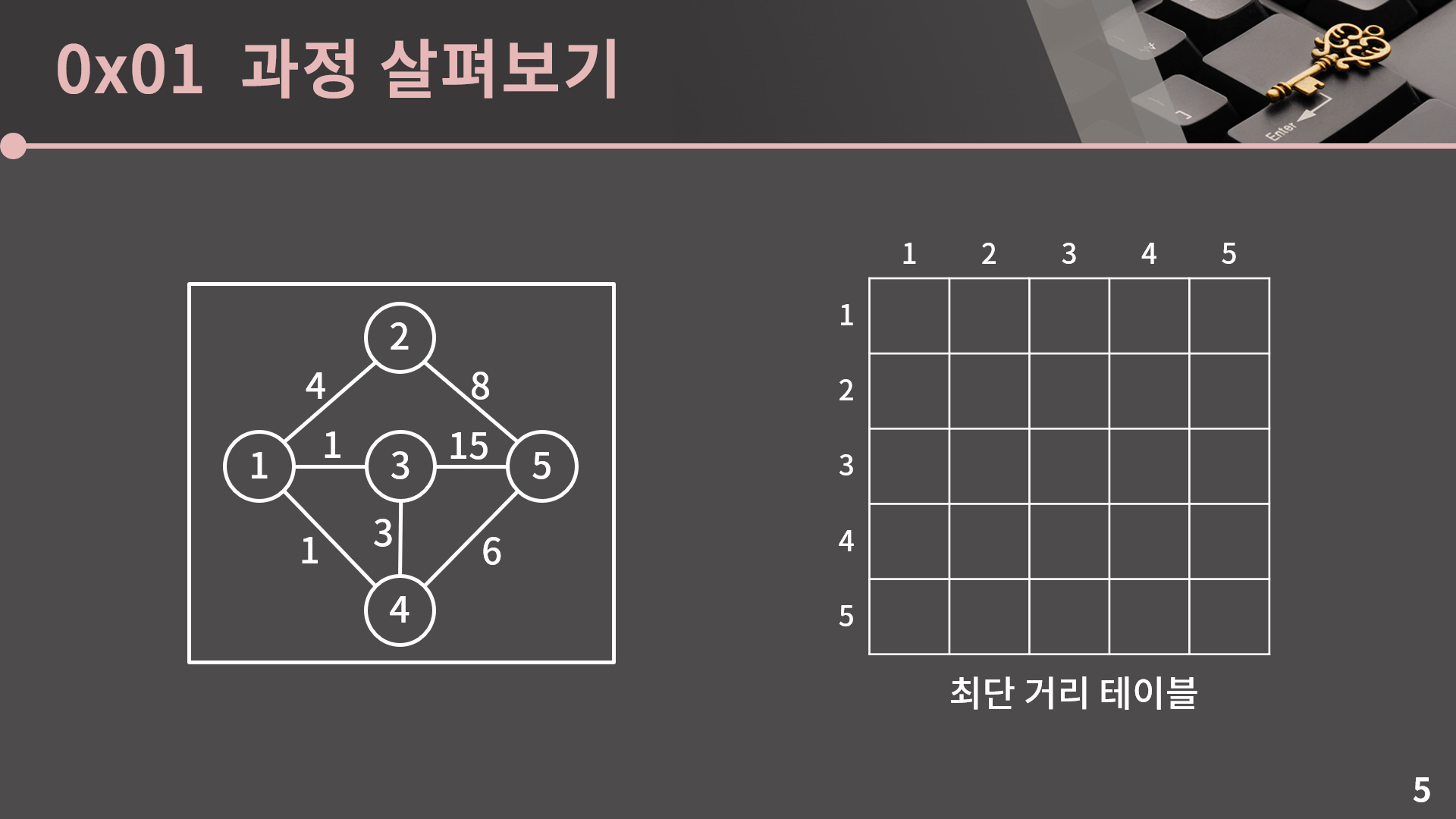
이제 플로이드 알고리즘의 과정을 알아보겠습니다. 설명을 돕기 위해 그래프와 빈 테이블을 모셔왔습니다.

일단 테이블에서 당장 채울 수 있는 것만 채워보겠습니다. 자기 자신으로 가는 거리는 당연히 0이고, 또 간선 1개로 바로 건너갈 수 있는 곳 또한 간선의 값으로 바로 채울 수 있습니다. 예를 들어 1번 정점과 2번 정점 사이에 거리가 4인 간선이 있기 때문에 (1, 2)와 (2, 1)이 모두 4로 채울 수 있습니다. 만약 방향 그래프였다면 하나만 채워졌을 것입니다.
그래프에 간선이 많기 때문에 자명한 것들만 채워도 꽤 많이 채워지긴 했습니다. 하지만 이 값은 여러 문제가 있습니다. 예를 들어 3에서 5로 가는 최단 거리가 8인데 지금은 간선 1개 짜리만 보니 15로 채워지게 됩니다. 그리고 1에서 5로 가는 최단 거리는 아예 알아내지도 못해서 ∞이 들어있습니다. 아직 테이블은 고쳐야할게 많습니다.
이러한 상황에서 이 플로이드 알고리즘은 아주 기발한 접근법을 제시합니다. 그 접근법이란 바로 현재 테이블에서 일단 1번을 거쳐가는 최단 거리만을 먼저 갱신하는 방법입니다.
현재 테이블에 적힌 값을 불완전한 최단 거리로 생각하지 말고, 중간에 다른 정점을 거치지 않았을 때의 최단 거리라고 생각하면 조금 더 이해에 도움이 될 것 같습니다.
이제 중간에 다른 정점을 거치지 않았을 때의 최단 거리가 저장되어있던 테이블을 중간에 다른 정점을 거치지 않았거나 1번 정점을 거쳐서 갈 때의 최단 거리가 저장되도록 수정해봅시다. 2에서 4로 가는 거리를 예로 들어보면 현재는 2에서 4로 가는 거리가 ∞인데 1을 거쳐서 가면 2에서 1로 가는 간선, 1에서 4로 가는 간선을 이용해 거리 5로 갈 수가 있기 때문에 해당 칸의 값을 5로 갱신하고 싶습니다.

해당 테이블을 D라고 합시다. s에서 t로 갈 때 1번 정점을 거쳐가는 최단 거리는 D[s][1] + D[1][t]입니다. D[s][1] + D[1][t]가 의미하는 바는 s에서 1까지 최단 경로로 가고, 그 후 1부터 t까지 다시 최단 경로로 갔을 때의 값이기 때문입니다. 그렇기 때문에 각 s, t에 대해 만약 D[s][t]보다 D[s][1] + D[1][t]가 작을 경우, 즉 1번 정점을 거쳐가는 것이 효율적일 때에만 D[s][t]를 D[s][1] + D[1][t]로 갱신해주면 됩니다. 결과적으로 주어진 테이블에서는 D[2][3], D[2][4], D[3][2], D[3][4], D[4][2], D[4][3]이 갱신됩니다.
이렇게 현재 테이블에 적힌 값을 중간에 다른 정점을 거치지 않았거나 1번 정점을 거쳐서 갈 때의 최단 거리로 만들었습니다. 이것을 중간에 다른 정점을 거치지 않았거나 1, 2번 정점을 거쳐서 갈 때의 최단 거리로 수정할 것입니다.
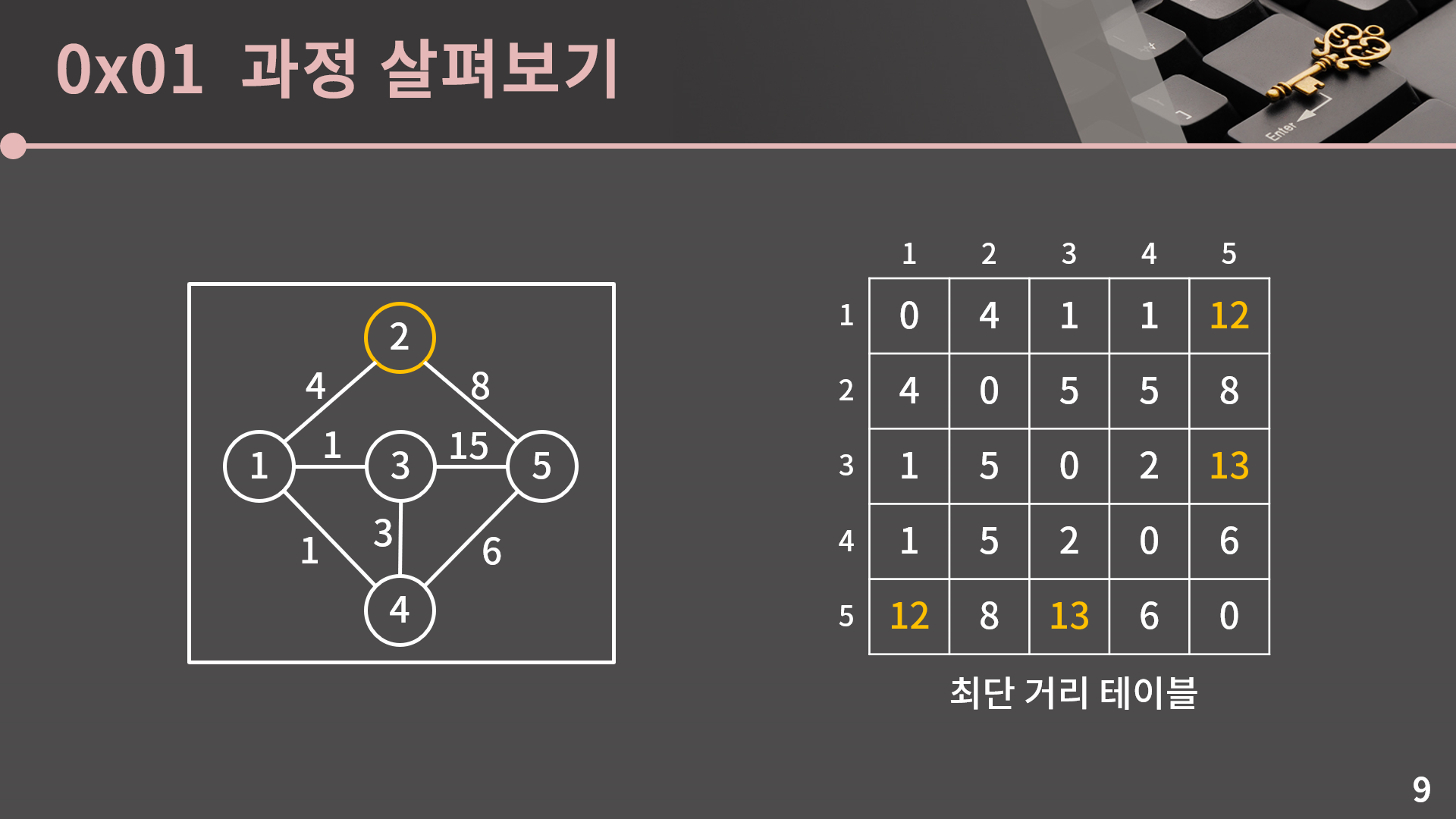
방법은 이전과 마찬가지입니다. 비슷한 논리로 생각했을 때 s에서 t로 갈 때 2번 정점을 거쳐가는 최단 거리는 D[s][2] + D[2][t]입니다. 만약 D[s][t]보다 D[s][2] + D[2][t]가 작을 경우 D[s][t]를 D[s][2] + D[2][t]로 갱신해주면 됩니다.
주어진 테이블에서는 D[1][5], D[3][5], D[5][1], D[5][3]이 갱신됩니다.
이제 대충 느낌이 오시나요? 현재 테이블에 적힌 값은 중간에 다른 정점을 거치지 않았거나 1, 2번 정점을 거쳐서 갈 때의 최단 거리입니다. 이것을 중간에 다른 정점을 거치지 않았거나 1, 2, 3번 정점을 거쳐서 갈 때의 최단 거리, 중간에 다른 정점을 거치지 않았거나 1, 2, 3, 4번 정점을 거쳐서 갈 때의 최단 거리, 마지막으로 중간에 다른 정점을 거치지 않았거나 1, 2, 3, 4, 5번 정점을 거쳐서 갈 때의 최단 거리 = 최종적인 최단 거리까지 쭉쭉 나아가면 됩니다.

테이블에 3번을 거쳐가는 최단 거리를 반영합시다. D[s][t]보다 D[s][3] + D[3][t]가 작을 경우 D[s][t]를 D[s][3] + D[3][t]로 갱신해주면 됩니다.
D[s][t]보다 D[s][3] + D[3][t]가 작은 경우가 없어 주어진 테이블에서는 아무 값도 변경되지 않습니다.

테이블에 4번을 거쳐가는 최단 거리를 반영합시다. D[s][t]보다 D[s][4] + D[4][t]가 작을 경우 D[s][t]를 D[s][4] + D[4][t]로 갱신해주면 됩니다.
주어진 테이블에서는 D[1][5], D[3][5], D[5][1], D[5][3]이 갱신됩니다.
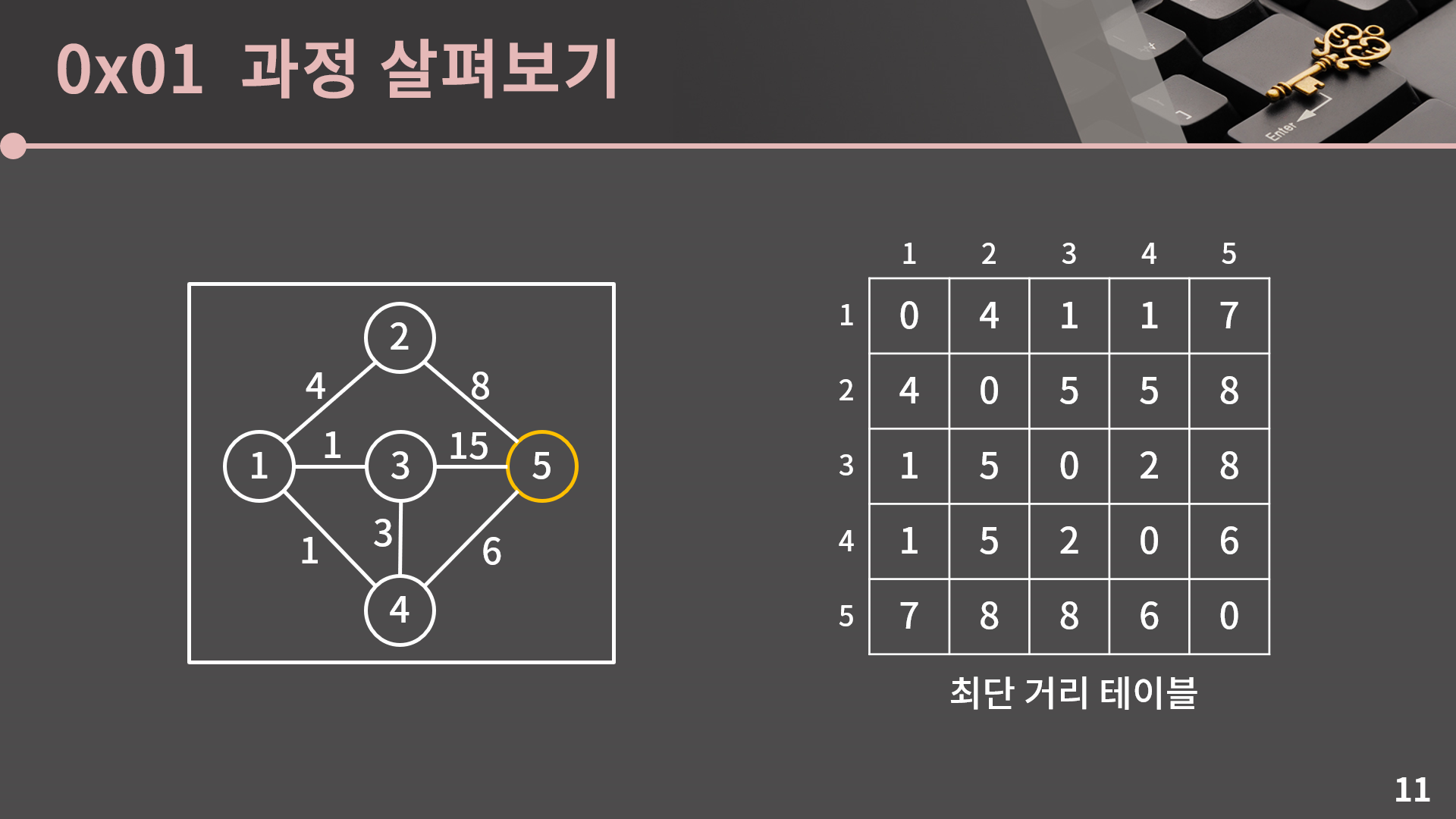
마지막으로 테이블에 5번을 거쳐가는 최단 거리를 반영합시다. D[s][t]보다 D[s][5] + D[5][t]가 작을 경우 D[s][t]를 D[s][5] + D[5][t]로 갱신해주면 됩니다.
D[s][t]보다 D[s][5] + D[5][t]가 작은 경우가 없어 주어진 테이블에서는 아무 값도 변경되지 않습니다. 이렇게 플로이드 알고리즘이 종료되었습니다. 정점이 V개라고 할 때 총 V단계에 걸쳐 갱신이 이루어지고 각 k=1,2,3,…,V번째 단계마다 총 V2개의 모든 D[s][t]값을 D[s][k]+D[k][t]값과 비교하므로 플로이드 알고리즘의 시간복잡도는 O(V3)입니다. 이 알고리즘의 정당성은 간단하게 언급한 것과 같이 1단계를 거치고 나면 중간에 다른 정점을 거치지 않았거나 1번 정점을 거쳐서 갈 때의 최단 거리를 알 수 있고, 그 다음으로 중간에 다른 정점을 거치지 않았거나 1, 2번 정점을 거쳐서 갈 때의 최단 거리를 알 수 있다는 식의 귀납적인 논법을 이용해 수학적으로 엄밀하게 증명할 수 있지만 생략하도록 하겠습니다.

무방향 그래프에서 최단 거리들을 구하는 BOJ 11404번: 플로이드 문제를 확인해보고 구현을 해봅시다. 플로이드 알고리즘은 구현이 정말정말정말정말정말 쉽기 때문에 직접 한 번 짜보도록 합시다. 참고로 3중 for문을 쓰면 끝입니다.
가능하면 직접 한 번 풀어보시면 좋겠고, 다음 슬라이드부터는 정답 코드를 놓고 분석할 예정이라 충분히 혼자 시도해본 후에 넘어와주세요.

일단 거리가 무한인 것을 나타내기 위한 INF 값은 0x3f3f3f3f으로 잡았습니다. 어느 두 도시의 최단 거리가 아무리 커봤자 99 × 100,000 이기에 이 값보다 큰 값을 INF로 삼으면 됩니다. 그런데 왜 이전에 많이 쓰던 0x7f7f7f7f 대신 0x3f3f3f3f를 쓴걸까요? 그건 플로이드 알고리즘의 계산 과정에서 INF값 2개를 더하는 일이 생길 수 있는데 그 때 int overflow가 나지 않게 하기 위해서입니다.
15번 줄부터 19번 줄까지는 각 간선을 받고 d 테이블을 채우는 루틴입니다. 위상 정렬이나 bfs/dfs 등에서는 각 정점에 대해 그 정점과 연결된 다른 정점의 목록을 보는 일이 많아서 그래프를 인접 리스트 방식으로 나타내는 것이 유리했는데 플로이드 알고리즘에서는 그냥 테이블의 형태 자체가 인접 행렬 형식이라 그래프를 인접 행렬 형식으로 나타낸다고 생각하면 됩니다. 일단 모든 행렬값을 INF로 둔 후, a, b, c가 주어지면 d[a][b]를 갱신합니다. 그런데 문제에서 시작 도시와 도착 도시를 연결하는 노선은 하나가 아닐 수 있다는 단서를 주었기 때문에 단순히 d[a][b] = c로 두면 안되고 18번째 줄과 같이 min을 통해 갱신을 해서 노선이 여러 개일 경우 가장 작은 노선의 거리가 저장되게끔 해야 합니다. 그 다음으로
20번째 줄 처럼 자기 자신으로 가는 비용은 0으로 다 만들어놓고 본격적으로 플로이드 알고리즘을 시작합니다.
3중 for문이 돌아가는 형태는 21-24번째 줄과 같습니다. 저는 플로이드 알고리즘을 구현할 때 3중 for문의 값을 k, i, j로 두고 i를 시작점, j를 끝점으로 생각하는 것을 선호합니다. 변수의 이름을 꼭 저와 같이 붙일 필요는 없지만 테이블을 갱신할 때 중간에 거쳐가게끔 할 원소를 3중 for문의 제일 바깥에 두어야한다는건 꼭 기억하셔야 합니다. 저기서 i, j, k의 순서가 바뀌었다고 할 때 작은 예제에서는 답이 맞는데 제출하면 틀리는 일이 아주 잘 발생해서 틀린 원인을 찾을 때 애를 먹는 경우가 종종 있습니다. (코드)
0x01강 - 기초 코드 작성 요령 I 단원에서 시간복잡도 얘기를 할 때 컴퓨터는 1초에 3-5억 번의 연산을 할 수 있다는 얘기를 했었습니다. 그 기준에 맞춰서 생각을 해보면 정점이 1000개일 때 플로이드 알고리즘은 O(n3)으로 계산할 때 10억이라 플로이드 알고리즘을 쓸 수 없겠다 싶지만 코드에서 볼 수 있듯 플로이드 알고리즘은 단순 사칙연산이 주를 이루기 때문에 정점 1000개 정도까지는 플로이드 알고리즘으로 풀어볼만 합니다.
또 만약 지금 제 코드처럼 플로이드 알고리즘을 구현했을 때 시간이 간당간당할 경우 시간을 좀 더 아낄 수 있는 팁을 하나 드리겠습니다. 24번째 줄을 보시면 저는 d[i][j]보다 d[i][k] + d[k][j]가 작을 경우 d[i][j]를 갱신하는 로직에서 그냥 min 함수를 이용해 코드를 짰습니다. 이전의 다른 예시 코드들에서도 최솟값이나 최댓값 갱신이 필요할 때 저런 식으로 작성을 한 경우를 많이 보셨을 것 같습니다. 그런데 보통 저희가 쓰는 환경에서는 연산보다 대입이 느립니다. 그렇기 때문에 저렇게 작성을 해서 매번 대입이 일어나게 하는 것 보다 if(d[i][k] + d[k][j] < d[i][j]) d[i][j] = d[i][k] + d[k][j]로 작성해 갱신이 꼭 필요할 때에만 대입이 일어나도록 하는게 시간상 유리합니다. 다른 문제들처럼 끽해야 대입을 10만번, 100만번 하는 수준에서는 차이가 미미하지만 특히 플로이드 알고리즘처럼 대입을 10억번씩 하는 경우에는 저 차이가 눈에 띄게 커지고, 이 문제에서는 정점이 최대 100개로 작아 별로 티가 나지 않지만 정점이 1,000개인 그래프에서는 이 개선을 통해 시간을 950ms에서 대략 700ms 정도로 떨굴 수 있습니다.
비단 플로이드 알고리즘뿐만 아니라 대표적으로 다이나믹 프로그래밍 문제와 같이 대입이 빈번하게 발생하는 다른 상황에서도 비슷한 방법으로 시간을 줄일 수 있습니다. 보통 이런걸 상수 시간 최적화라고 하는데, 사실 대부분의 경우 정해로 잘 접근했는데도 불구하고 상수 시간의 차이로 문제를 틀리는 경우가 안생기게 시간 제한을 적당히 넉넉하게 줍니다. 또 그런 관점에서 플로이드 알고리즘이 정해인데 정점을 최대 1,000개 주는건 썩 바람직한 상황은 아닙니다. 원래는 다른 알고리즘이 정해인데 플로이드 알고리즘으로도 해결을 할 수는 있는 상황은 있을 수 있지만요. 그렇기에 비록 min을 써서 불필요한 대입을 발생하게 하는게 좋다고는 할 수 없지만 정해를 제대로 잡았다면 이런 문제로 인해 맞아야 하는 코드가 틀리는 일은 잘 발생하지 않습니다. 당장 저도 코드를 좀 더 짤막하게 쓸 수 있는 점이 마음에 들어서 불필요한 대입이 생긴다는걸 알면서도 min 혹은 max를 이용한 갱신을 즐겨 씁니다. 하지만 꼭 알고리즘용 코딩이 아니더라도 이런 자잘한 최적화가 모여서 전반적인 성능 개선에 도움이 될 수 있고 또 속된 말로 문제를 비빌 때, 뭔가 시간복잡도를 계산했을 때 시간 초과와 통과의 경계에 있는 것 같아서 어떻게든 코드를 최적화시켜야 할 때 고려해볼 수 있는 요소라고 생각할 수 있겠습니다.
얘기가 길어졌는데, 요약하면 저는 코드를 짤막하게 쓰는걸 좋아해서 갱신을 24번째 줄과 같이 처리했지만 저런 코드의 형태는 불필요한 대입을 발생시키니 시간 제한이 애매하다거나 기타 이유로 성능을 올리고 싶을 땐 비교를 거친 후 갱신이 꼭 필요할 때에만 대입을 하도록 짜면 됩니다.
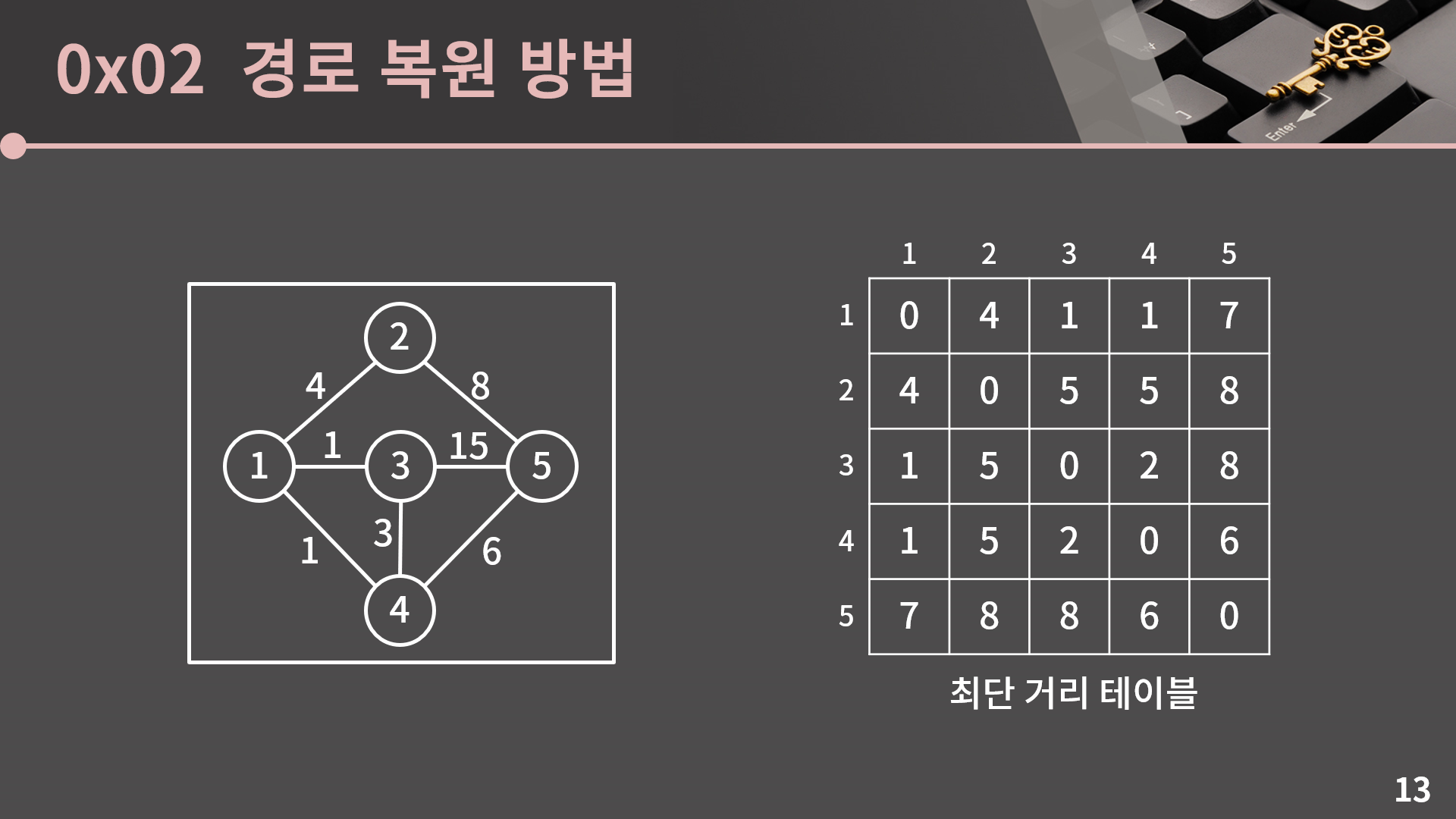
플로이드 알고리즘을 통해 우리는 주어진 그래프에서 임의의 시작점으로부터 임의의 도착점까지의 최단 거리를 알 수 있습니다. 그런데 지금은 거리만 알고 있을 뿐 최단 거리로 가기 위해서 실제 어떤 경로로 가야하는지는 전혀 알지 못합니다.
예를 들어 3에서 5로 가는 최단 거리가 8인건 알겠는데, 3, 1, 4, 5 순으로 가야한다는 사실을 알 수는 없습니다.
그래서 이번 챕터에서는 플로이드 알고리즘에서 어떻게 경로 복원을 할 수 있는지 다뤄보도록 하겠습니다.

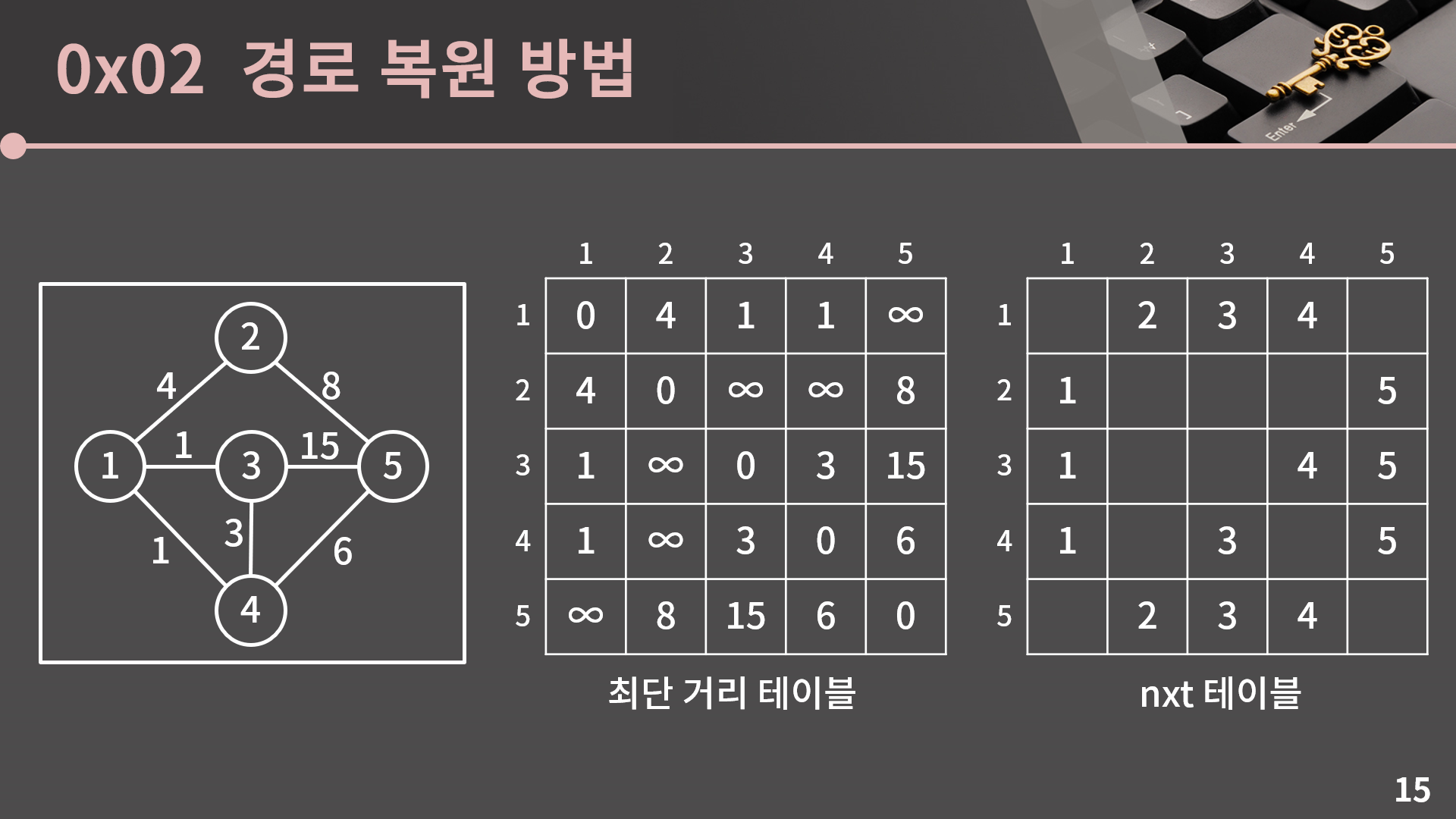
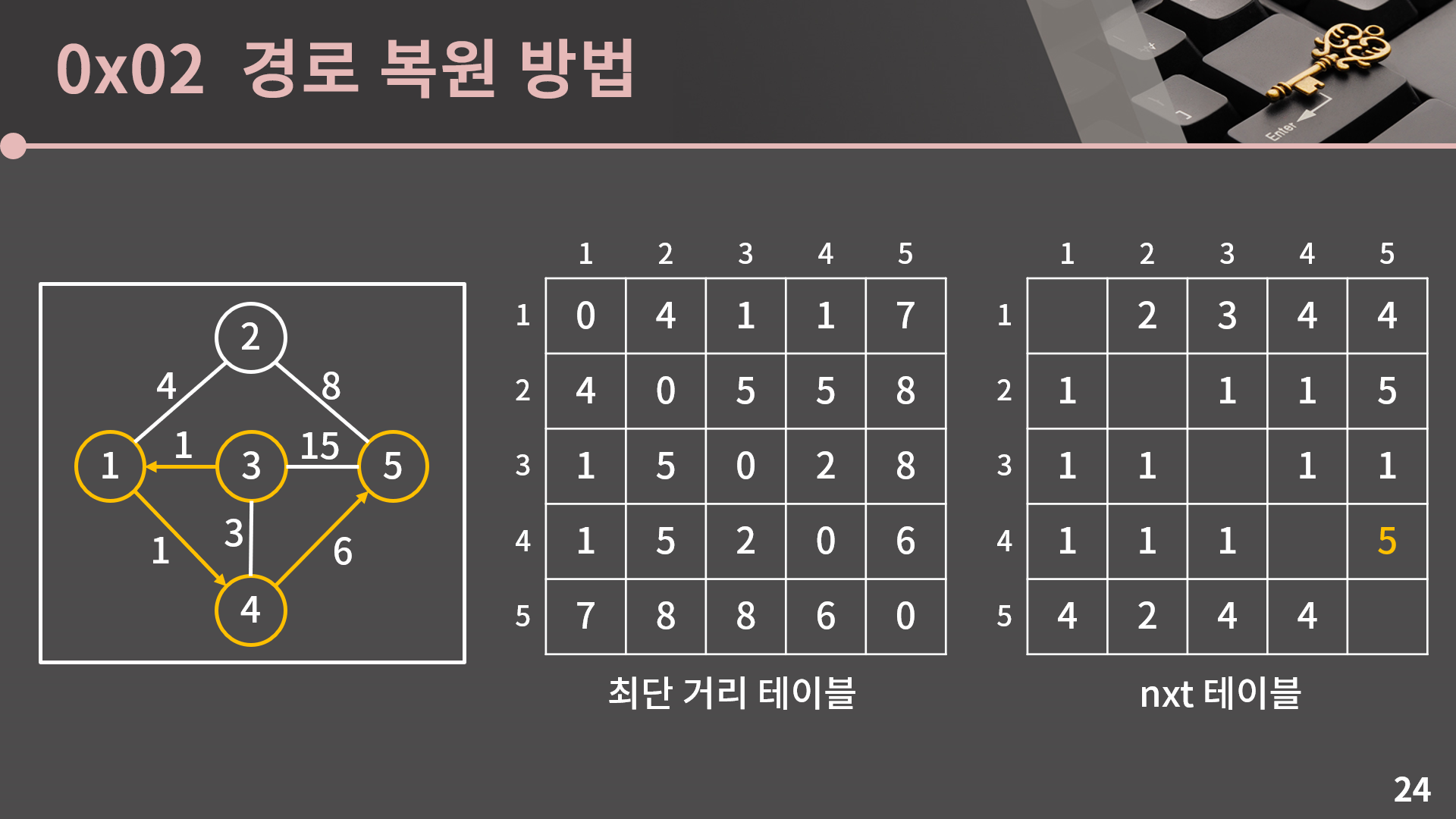
a에서 b까지 최단 거리로 가는 전체 경로를 다 복원하려고 들지 말고 딱 한 단계만 해봅시다. a에서 b까지 최단 거리로 가려면 a에서 어느 정점으로 가야 하는지만 생각해봅시다. 이를 nxt 테이블이라고 부르겠습니다.
이 nxt 테이블은 최단 거리 테이블을 채우는 과정 속에서 같이 채워지게 됩니다. 채워나가는 과정을 같이 살펴보기 위해 일단 최단 거리 테이블과 nxt 테이블을 모두 비워뒀습니다.
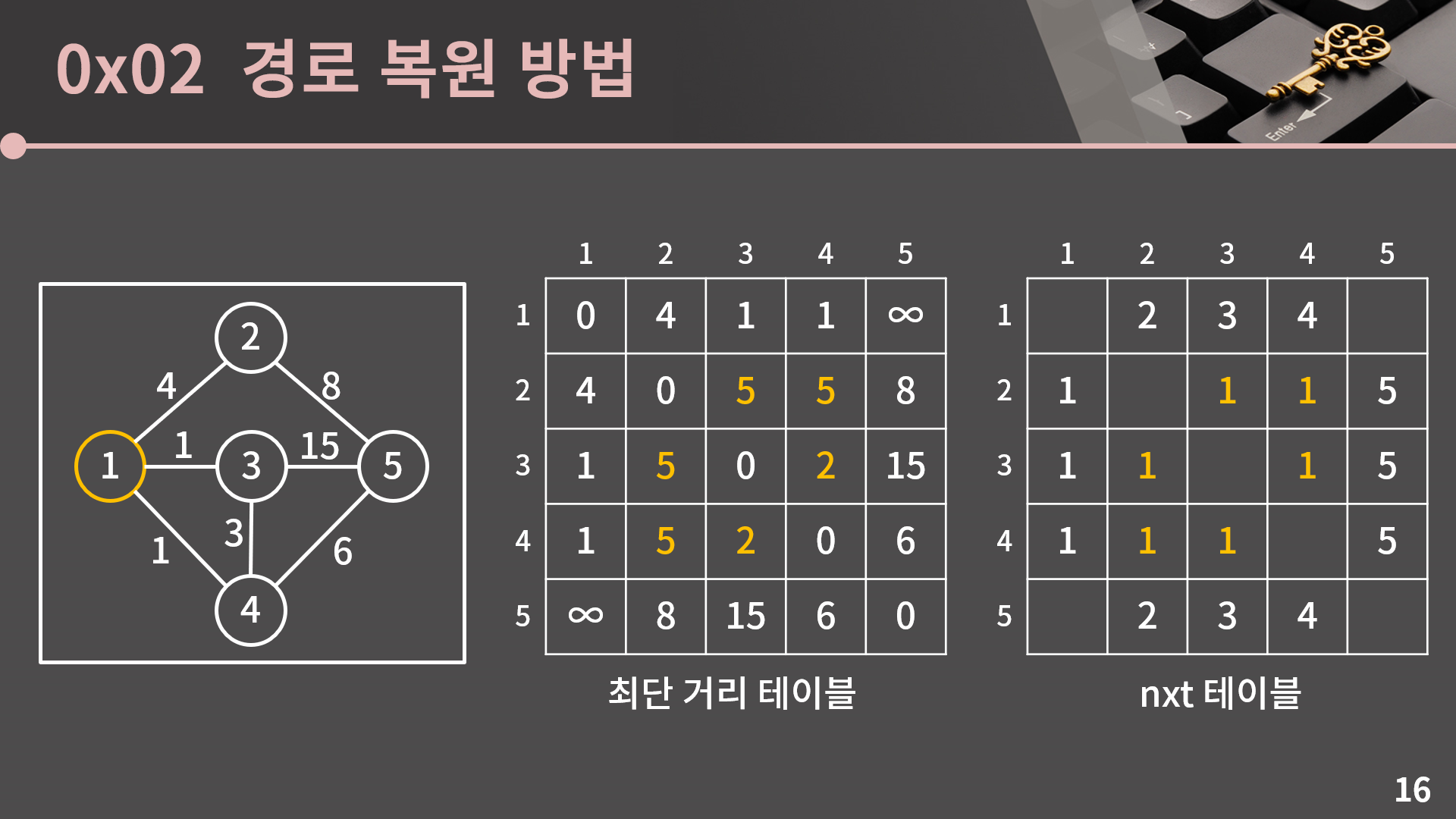
중간에 다른 정점을 거치지 않았을 때의 최단 거리를 먼저 채워보겠습니다. nxt 테이블도 지금까지는 큰 어려움 없이 채울 수 있는데, 예를 들어 1에서 2로 가는 간선이 있으므로 nxt[1][2]는 2가 됩니다.
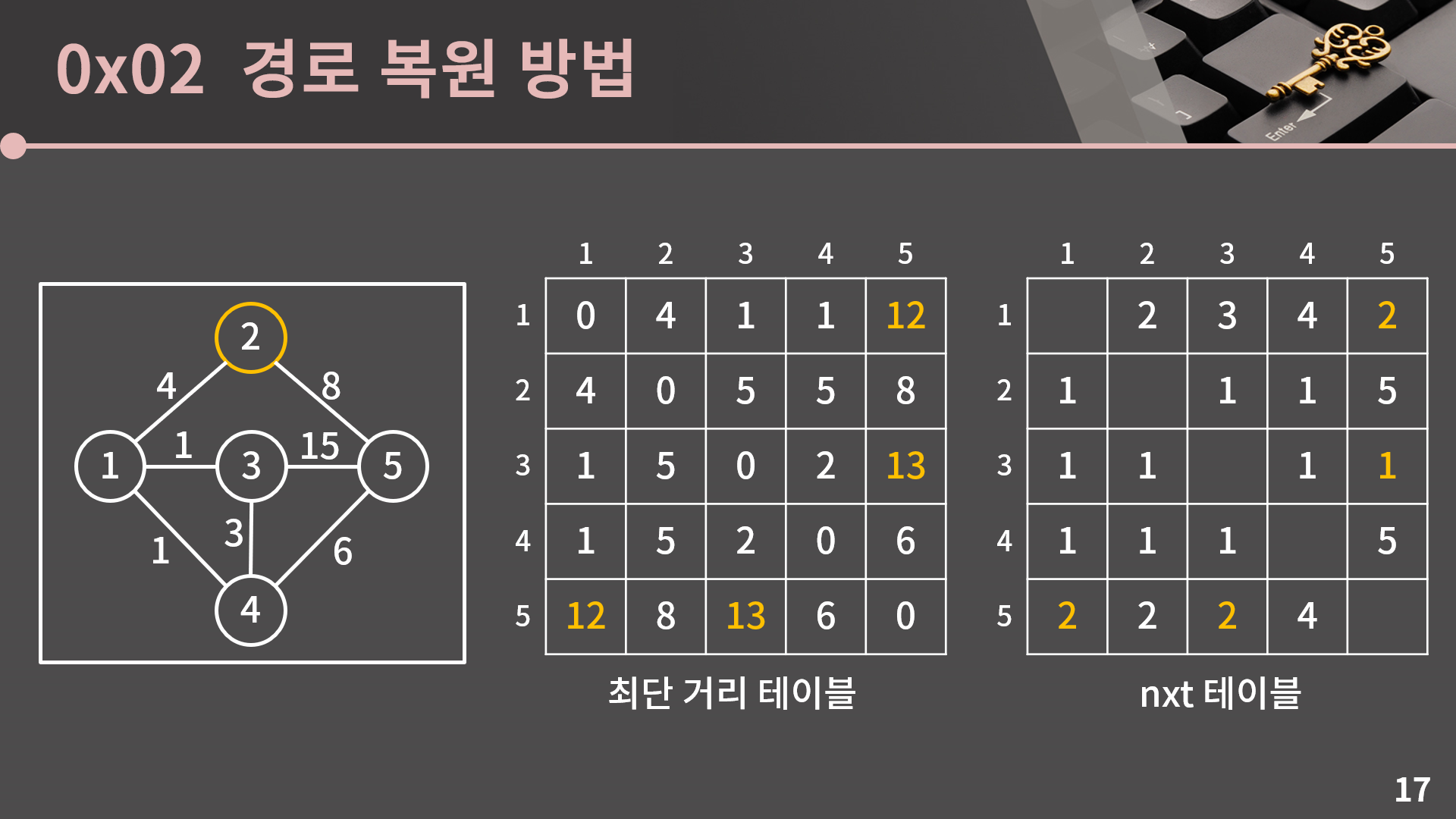
그리고 이 다음 단계가 핵심입니다. 맨 처음 최단 거리 테이블은 중간에 다른 정점을 거치지 않았을 때의 최단 거리였습니다. 이걸 중간에 다른 정점을 거치지 않았거나 1번 정점을 거쳐서 갈 때의 최단 거리가 저장되도록 수정하기 위해 D[s][t]보다 D[s][1] + D[1][t]가 작을 경우, 즉 1번 정점을 거쳐가는 것이 효율적일 때에만 D[s][t]를 D[s][1] + D[1][t]로 갱신했습니다.
만약 갱신이 일어났다면 nxt[s][t] 또한 변경이 필요한데, 기존의 s에서 t까지 가는 경로보다 s에서 1을 먼저 갔다가 1에서 t로 가는 경로가 더 효율적인 상황이므로 nxt[s][t]를 nxt[s][1] 값으로 대체하면 됩니다. s에서 1을 먼저 갔다가 1에서 t로 가는 경로가 전체적으로 어떻게 생겼는지는 모르겠지만 일단 s에서 1로 가야하는건 자명하므로 s에서 t까지 최단 경로로 가기 위해서는 s에서 출발해 제일 먼저 nxt[s][1]을 가야합니다.
최단 거리 테이블에서 D[2][3], D[2][4], D[3][2], D[3][4], D[4][2], D[4][3]이 갱신되었으므로 nxt[2][3], nxt[2][4], nxt[3][2], nxt[3][4], nxt[4][2], nxt[4][3] 각각은 nxt[2][1], nxt[2][1], nxt[3][1], nxt[3][1], nxt[4][1], nxt[4][1]로 변경됩니다.
그 다음으로 2번 정점을 거쳐가는 최단 거리를 고려합니다. 만약 D[s][t]보다 D[s][2] + D[2][t]가 작을 경우 D[s][t]를 D[s][2] + D[2][t]로 갱신합니다.
앞에서 한 것과 마찬가지 논리로 기존의 s에서 t까지 가는 경로보다 s에서 2를 먼저 갔다가 2에서 t로 가는 경로가 더 효율적인 상황일 경우 nxt[s][t]를 nxt[s][2] 값으로 대체하면 됩니다.
최단 거리 테이블에서 D[1][5], D[3][5], D[5][1], D[5][3]이 갱신되었으므로 nxt[1][5], nxt[3][5], nxt[5][1], nxt[5][3] 각각은 nxt[1][2], nxt[3][2], nxt[5][2], nxt[5][2]로 변경됩니다.
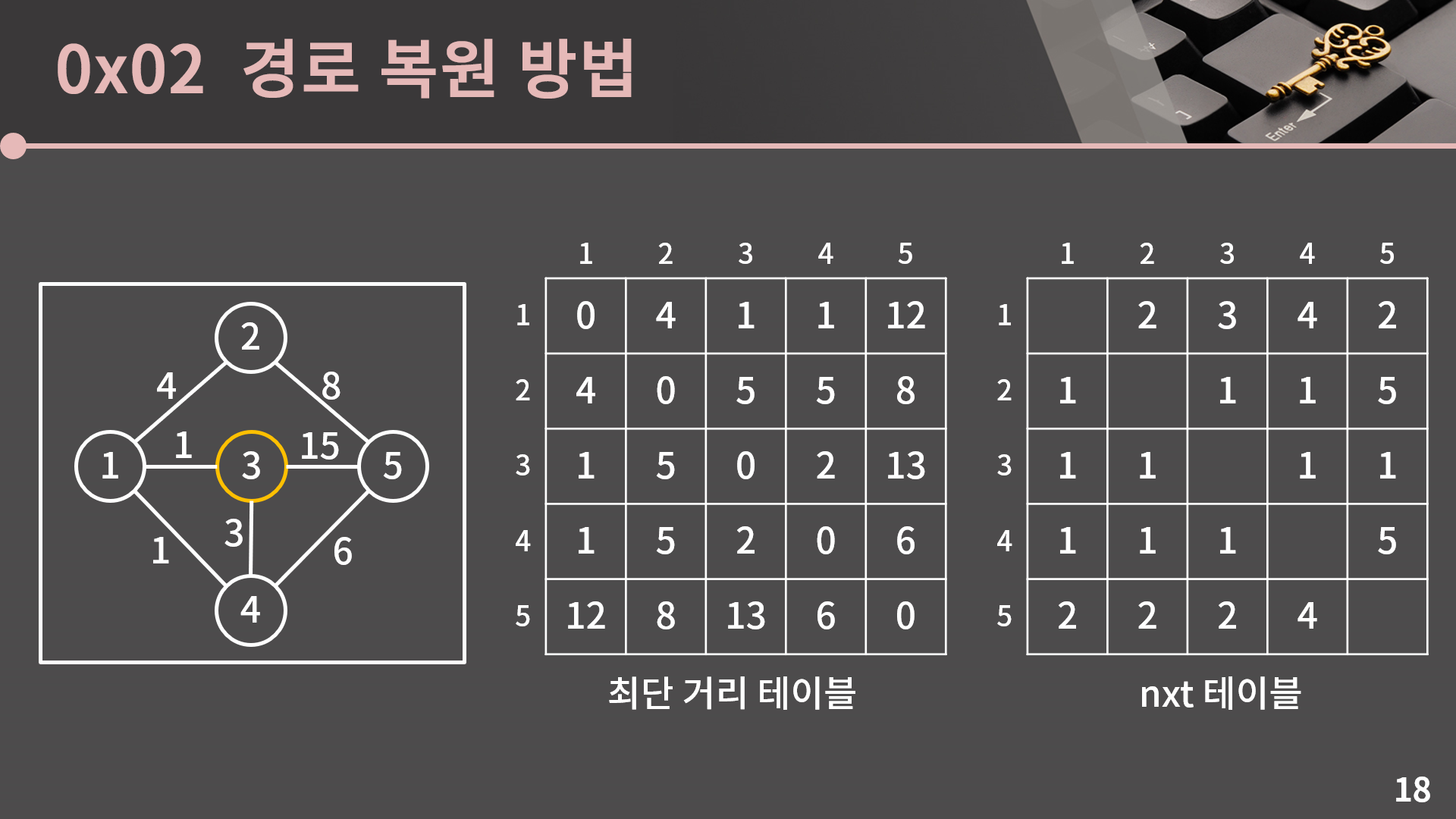
그 다음으로 테이블에 3번을 거쳐가는 최단 거리를 반영하려고 했는데 D[s][t]보다 D[s][3] + D[3][t]가 작은 경우가 존재하지 않아 아무 일도 일어나지 않습니다.
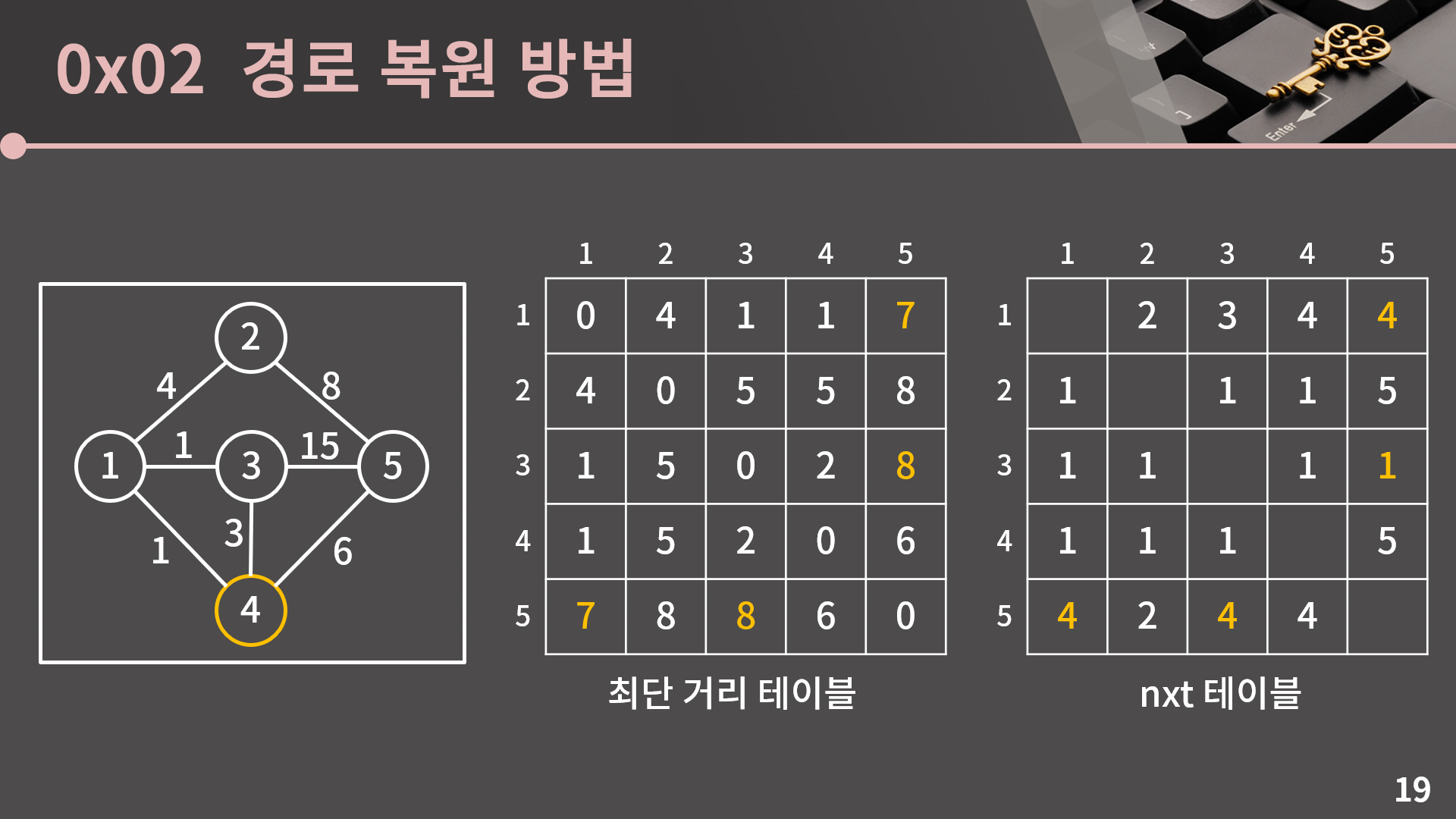
그 다음으로는 4번 정점을 거쳐가는 최단 거리를 고려합니다. 만약 D[s][t]보다 D[s][4] + D[4][t]가 작을 경우 D[s][t]를 D[s][4] + D[4][t]로 갱신합니다.
앞에서 한 것과 마찬가지 논리로 기존의 s에서 t까지 가는 경로보다 s에서 4를 먼저 갔다가 4에서 t로 가는 경로가 더 효율적인 상황일 경우 nxt[s][t]를 nxt[s][4] 값으로 대체하면 됩니다.
최단 거리 테이블에서 D[1][5], D[3][5], D[5][1], D[5][3]이 갱신되었으므로 nxt[1][5], nxt[3][5], nxt[5][1], nxt[5][3] 각각은 nxt[1][4], nxt[3][4], nxt[5][4], nxt[5][4]로 변경됩니다. 다만 공교롭게도 nxt[3][5]의 경우 기존의 값이 1이었는데 nxt[3][4]도 1이기 때문에 값이 달라지지 않습니다.
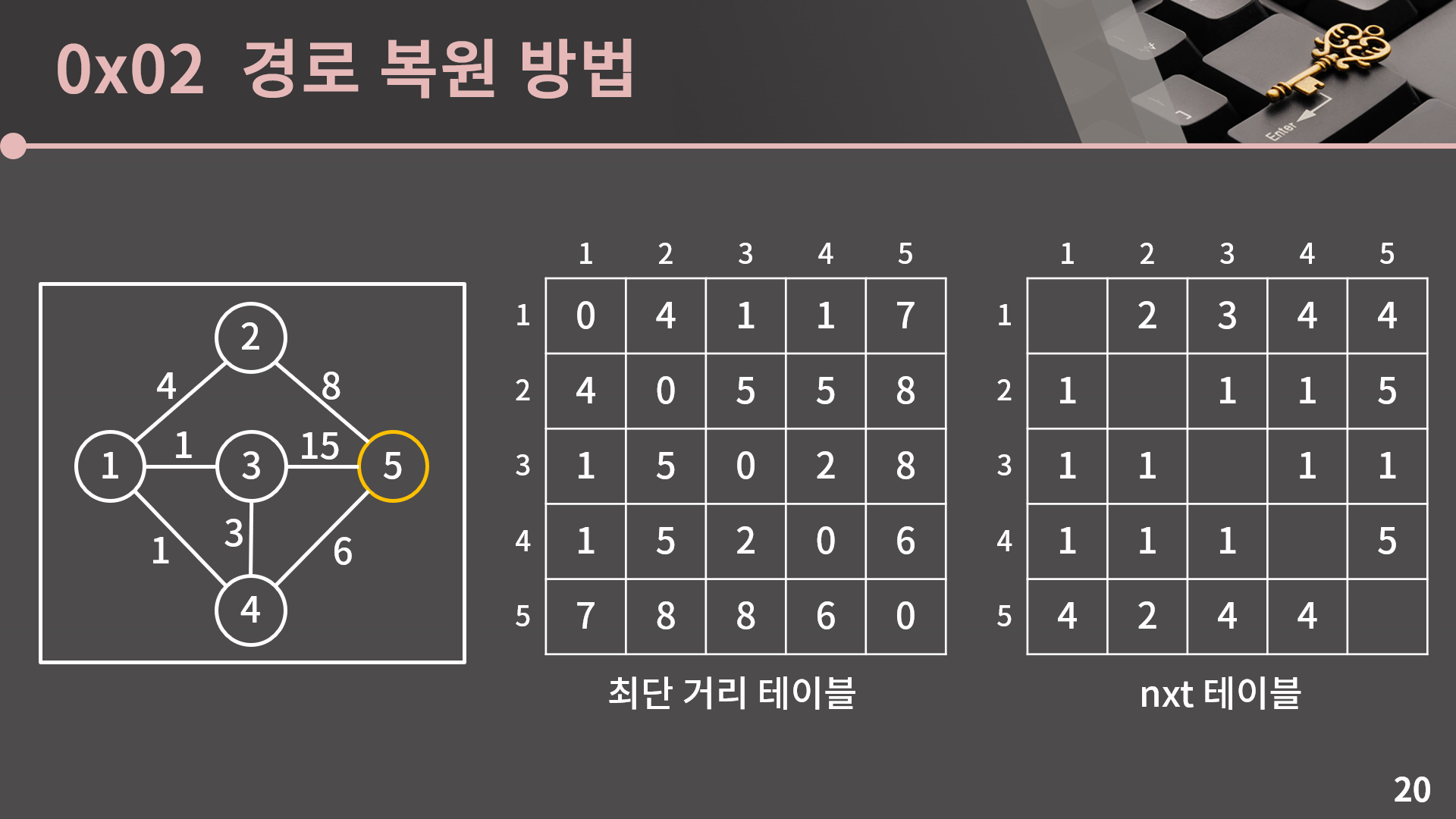
마지막으로 테이블에 5번을 거쳐가는 최단 거리를 반영하려고 했는데 D[s][t]보다 D[s][5] + D[5][t]가 작은 경우가 존재하지 않아 아무 일도 일어나지 않습니다.

플로이드 알고리즘이 종료되었고 이번에는 최단 거리 테이블뿐만 아니라 nxt 테이블까지 얻었습니다. 이 nxt 테이블을 통해 어떻게 경로 복원을 할 수 있을까요?
다이나믹 프로그래밍 단원에서 1로 만들기 2 문제의 풀이를 기억하고 있다면 아마 여기까지만 보고 바로 경로 복원을 해낼 수 있을 것 같습니다. 바로 도전해보실 분은 그렇게 하시고, 3에서 5까지 가는 경로를 복원하는걸 한 번 보여드리겠습니다. 설령 감이 잘 안오더라도 이 예제만 보고나면 바로 이해가 갈 것입니다.
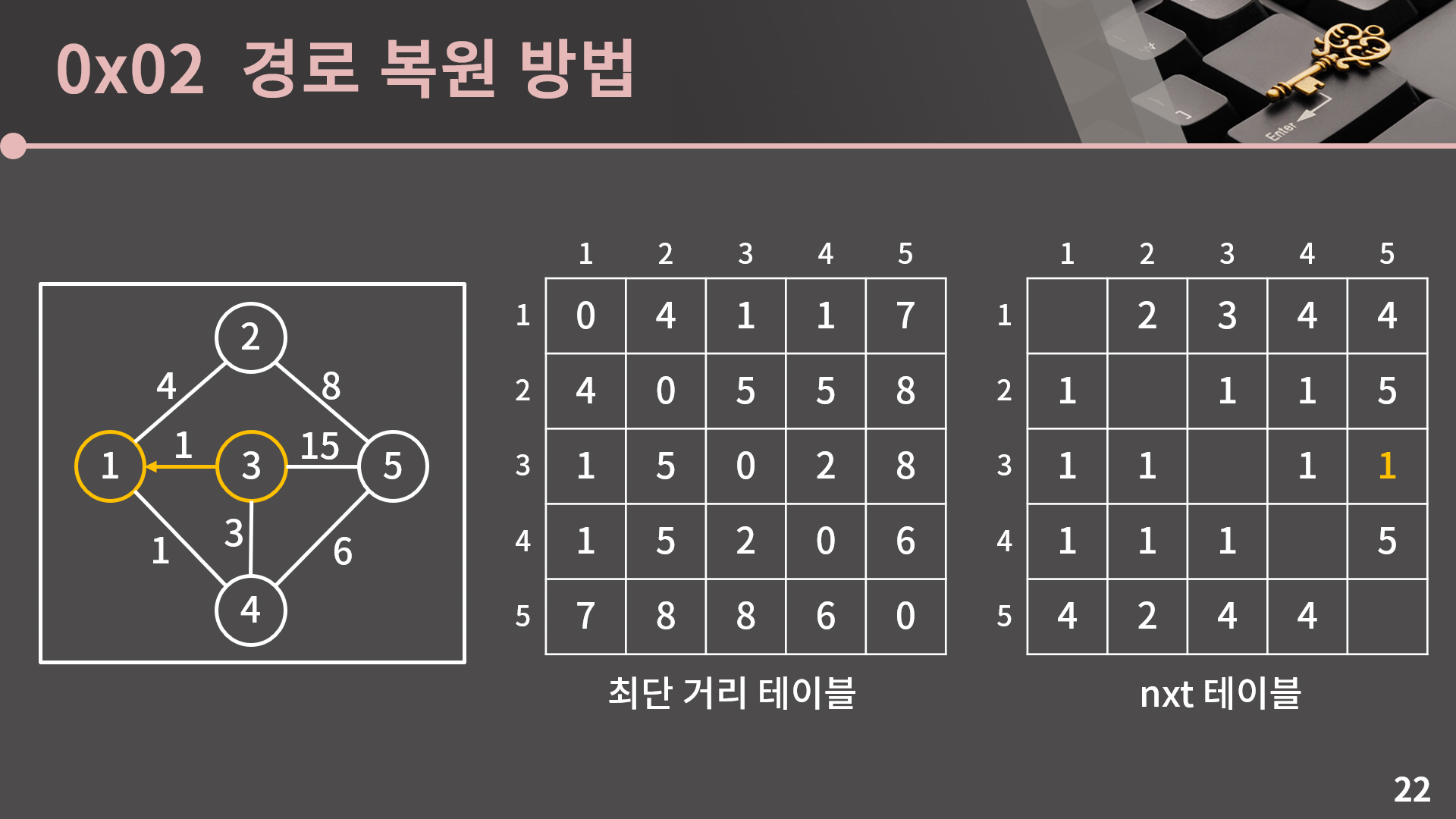
딴건 모르겠고 nxt[3][5]가 1이므로 일단 3에서 1로 갑니다. 그 다음은 어디로 가야할까요?

현재 1에 와있으니 1에서 5까지 최단 거리로 가면 됩니다. nxt[1][5]가 4이므로 1에서 4로 갑니다. 그 다음은 어디로 가야할까요?
현재 4에 와있으니 4에서 5까지 최단 거리로 가면 됩니다. nxt[4][5]가 5이므로 4에서 5로 갑니다.
축하합니다. 목적지에 도착했습니다. 이와 같이 nxt 테이블을 이용해 한 단계씩 앞으로 전진하면 경로를 복원해낼 수 있습니다. 구현은 다음 슬라이드에서 BOJ 11780번: 플로이드 2 문제의 코드를 보면서 같이 살펴보겠습니다.

코드가 길어서 뒷부분이 잘렸는데 일단 여기까지만 한번 보겠습니다. 이전의 코드와 대부분이 동일하기 때문에 nxt 배열과 관련된 부분만 짚고 넘어가겠습니다. 16-21번째 줄에서 입력을 처리할 때 20번째 줄과 같이 nxt 배열의 값 또한 변경합니다. 그리고 24-30번째 줄과 같이 3중 for문을 돌 때 29번째 줄과 같이 nxt 배열을 갱신해줍니다.

다음으로 경로를 복원하는 부분인데, 47-50번째 줄의 로직이 핵심입니다. 앞에서 언급한 다이나믹 프로그래밍 단원에서의 1로 만들기 2 문제에서도 동일한 로직이 등장했고 조금 가물가물할 수 있겠지만 야매 연결 리스트에서 traverse 함수도 마찬가지였으니 이해에 크게 어려움은 없을 것으로 보입니다. (코드)

이번 강의를 통해 플로이드 알고리즘을 익혔습니다. 플로이드 알고리즘은 무방향 혹은 방향 그래프에서 모든 정점 쌍 사이의 최단 거리와 그 경로를 O(V3)에 알아낼 수 있는 알고리즘입니다.
문제집의 연습 문제들을 풀다보면 느낄 수 있겠지만 주어진 그래프 문제에서 정점의 수가 1000개 이하로 작다면 일단 플로이드 알고리즘을 돌릴 수 있음을 인지하고, 모든 정점 쌍 사이의 최단 경로를 구할 경우 문제에서 요구하는 바를 계산해낼 수 있는지를 고민하는 식으로 접근할 수 있습니다. 또 응용 문제에는 플로이드 알고리즘의 원리 자체를 제대로 이해하고 있어야 해결할 수 있는 문제를 몇 개 두었으니 지적 유희가 필요하거나 이번 기회에 플로이드 알고리즘을 정복하겠다 하는 큰 야망이 있으시다면 응용 문제까지 꼼꼼하게 풀어보도록 합시다.
'강좌 > 실전 알고리즘' 카테고리의 다른 글
| [실전 알고리즘] 0x1F강 - 트라이 (40) | 2022.09.06 |
|---|---|
| [실전 알고리즘] 0x1E강 - KMP (21) | 2022.08.02 |
| [실전 알고리즘] 0x1D강 - 다익스트라 알고리즘 (49) | 2022.02.19 |
| [실전 알고리즘] 0x1B강 - 최소 신장 트리 (32) | 2022.01.08 |
| [실전 알고리즘] 0x1A강 - 위상 정렬 (10) | 2021.12.27 |
| [실전 알고리즘] 0x19강 - 트리 (22) | 2021.12.14 |