
안녕하세요, 드디어 마지막 강이라니 가슴이 웅장해집니다. 마지막인만큼 난이도도 끝판왕일 수 있지만 개인적으로는 꽤 좋아하는 알고리즘 중 하나여서 같이 즐거운 마음으로 배워봅시다.

아쉽게도 트라이는 STL로 날먹을 할 수가 없습니다. 트라이로 풀어야 하는 문제가 나오면 직접 정직하게 짜셔야 합니다.
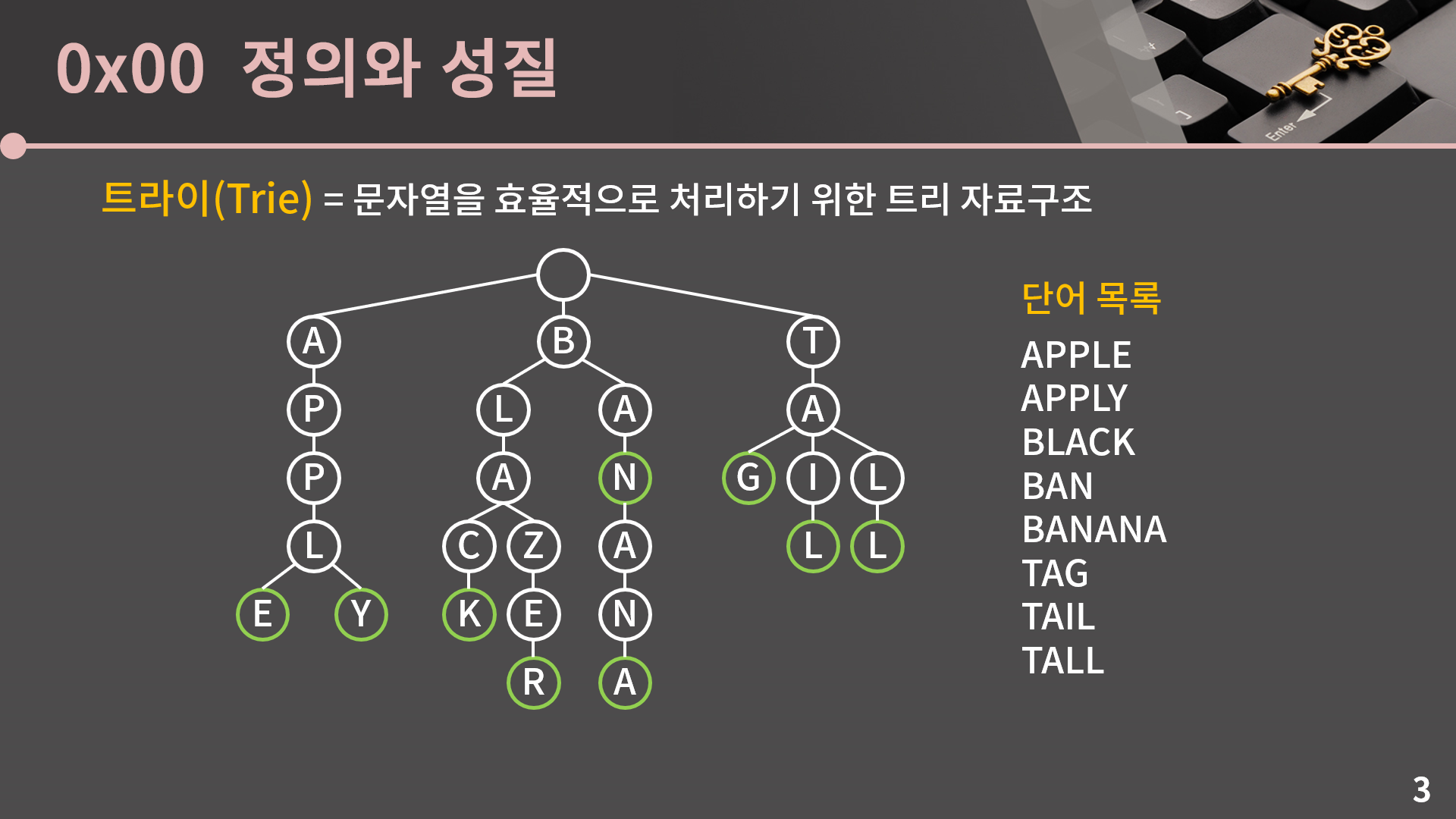
트라이는 문자열을 효율적으로 처리하기 위한 트리 자료구조입니다. 트라이 자료구조에서 단어들을 저장한 예시가 저기 그림에 있는데 아마 벌써부터 뭔가 심상치않고 구현이 상당히 어려울 것 같은 느낌이 듭니다. 그런데 사실 대충 느낌적으로 자료구조의 동작 원리를 이해할 수는 있을 것 같습니다. 트리의 루트에서 시작해서 초록색 원이 있는 곳까지 읽어나가면 각 단어에 대응이 됩니다. 예를 들어 가장 왼쪽의 E를 보면, 루트에서 E에 도달할 때 까지 A, P, P, L, E 순으로 방문을 하기 때문에 단어 APPLE에 대응이 됩니다. 일단 이 정도로만 느낌을 잡고 넘어갑시다.

트라이의 성질에 대해 살펴보면 트라이는 이론적인 시간복잡도가 좋습니다. 저기 적힌 |S|는 이전 KMP 단원에서 나왔었지만 S의 길이를 의미합니다. 즉 기존에 단어가 얼마나 많이 저장되어 있는지 여부와 무관하게 무조건 삽입, 탐색, 삭제를 모조리 O(|S|)에 처리할 수 있습니다. 이게 얼마나 좋은건지를 설명하기 위해 삽입, 탐색, 삭제가 효율적이라고 알고있는 다른 자료구조들로 단어들을 처리하는 상황을 생각해보겠습니다.
만약 단어들을 이진 검색 트리로 처리한다고 하면, 즉 각 단어를 이진 검색 트리의 정점으로 둔다고 하면 단어가 N개 있다고 할 때 이진 검색 트리 단원에서 배웠듯 삽입, 탐색, 삭제 모두 O(lg N)번의 비교가 발생하기 때문에 최악의 경우 O(|S| × lg N)이 필요하게 됩니다. 만약 해시로 관리를 한다면 삽입, 탐색, 삭제가 모두 O(1)인 것 같지만 사실은 해시 값을 계산할 때 O(|S|)이 필요하기도 하고 또 문자열 간의 비교도 발생하기 때문에 삽입, 탐색, 삭제가 O(|S|)입니다. 단, 해시는 이론적으로 O(|S|)지만 실제로는 충돌에 따라 성능이 저하될 수 있는 반면 트라이는 삽입, 탐색, 삭제가 전부 정직하게 O(|S|)에 동작합니다.
이렇게 이론적으로 생각할 때 트라이는 좋은 시간복잡도를 가지고 있지만 한편으로 트라이는 메모리를 아주 많이 차지한다는 단점이 있습니다. 단어들을 그냥 평범하게 배열에 저장하는 것과 비교했을 때 메모리를 무려 '4 × 글자의 종류'배 만큼 더 사용하게 됩니다. 예를 들어 각 단어가 알파벳 대문자로만 구성이 되어있다면 글자의 종류가 26개이기 때문에 메모리를 104배나 더 사용합니다. 그래서 지금까지 다룬 자료구조 중에서 최초로 메모리 사용량이 병목이 될 수 있는 자료구조입니다. 그 이유에 대해서는 실제 구현을 다룰 때 설명을 드리도록 하겠습니다. 또 트라이에서 메모리 사용량을 줄일 수 있는 소소한 방법들이 있습니다. 하지만 이 방법을 적용하면 반대로 연산의 속도가 느려지게 됩니다. 일종의 트레이드오프이죠. 이 테크닉이 무엇인지도 구현을 다룰 때 간단하게 짚어드리도록 하겠습니다.
한편 꼭 알고계셔야 하는 점이 있는데, 이론적으로는 트라이의 시간복잡도가 해시나 이진 검색 트리에 비해 좋은 것과 반대로 구현을 해보면 실제로는 트라이가 훨씬 느리게 동작합니다. 뒤에서 예시로 소개할 문제에서 길이가 최대 500인 10000개의 문자열을 삽입하고 검색하는데 이진 검색 트리와 해시는 각각 76ms, 92ms가 걸린 반면 트라이에서는 무려 472ms가 걸리는 것을 확인할 수 있습니다. 여기에는 다양한 원인이 있는데 그건 트라이를 공부한 후 알아보기로 하고, 기억하고 가시면 좋을건 그냥 일반적인 문자열의 삽입/삭제/검색을 수행해야 하는 상황에서는 트라이보다 해시 혹은 이진 검색 트리를 쓰는 것이 메모리와 시간 측면 모두에서 효율적이고 구현 난이도도 STL을 그대로 가져올 수 있기 때문에 훨씬 낮습니다. 하지만 단순히 문자열의 삽입/삭제/검색만을 수행하는게 아니라 트라이의 성질을 이용해야만 해결이 가능한 문제가 여럿 있기 때문에 트라이를 익혀둘 필요가 있습니다.

이제 트라이에서 각 연산들을 수행해보도록 하겠습니다. 바로 삽입부터 확인해봅시다. 우선 처음에는 루트만 있는 트리에서 시작합니다. 여기서 APPLE을 삽입하고 싶습니다. 참고로 트라이에서는 삽입, 탐색, 삭제 이 모든 연산을 할 때 정점을 옮겨다니게 됩니다. 이 때 현재 보고 있는 정점을 주황색 테두리로 표시해두었습니다.

삽입을 할 때에는 A, P, P, L, E 순으로 탐색을 합니다. 이건 검색, 삭제에서도 마찬가지입니다. 현재 보고 있는 정점인 루트에는 값이 A인 자식이 없습니다. 그렇기 때문에 A를 현재 보고 있는 정점의 자식에 추가하고 현재 보고 있는 정점을 루트에서 새로 추가한 A로 옮깁니다.

A 다음으로 P를 볼 차례입니다. 현재 보고 있는 정점에는 P라는 자식이 없기 때문에 P를 현재 보고 있는 정점의 자식에 추가하고 현재 보고 있는 정점을 P로 옮깁니다. 뒤의 P, L, E에 대해서도 상황이 동일하기 때문에 P, L, E는 한번에 보여드리도록 하겠습니다.

이렇게 E까지 왔습니다. 삽입이 끝난 후에는 마지막 글자에 별도의 표시를 해줍니다. 이 별도의 표시는 초록색 테두리로 나타내겠습니다.

다음으로는 APPLY를 삽입해보겠습니다. 다시 루트에서부터 출발합니다.

현재 보고 있는 정점의 자식 중에 A가 있기 때문에 새 정점을 추가할 필요가 없고 A로 이동하면 됩니다.

그 뒤의 P, P, L에 대해서도 동일한 상황이기 때문에 L까지는 한번에 이동했습니다. 이전에 다 만들어져있어서 새로운 노드를 만들 필요 없이 L까지 도달할 수 있었습니다.

하지만 현재 보고 있는 정점의 자식 중에 Y는 없기 때문에 Y의 경우 새로운 정점을 만들어줘야 합니다. 또 문자열의 끝에 도달했기 때문에 별도의 표시를 남깁니다. 이렇게 APPLY의 삽입도 끝났습니다. 나중에 코드로 짜는게 좀 복잡해서 문제인거지 트리를 잘 이해하고 있다면 일단 지금 그림으로 동작 원리를 이해하는데에는 크게 어려움이 없을 것 같습니다. 다음으로는 BANANA를 삽입하겠습니다. 이제부터는 글자를 한 개씩 이동하는 대신에 한번에 바로 보여드리겠습니다. 예상한 결과와 일치하는지 확인해보세요.

BANANA를 삽입하고나면 이렇게 됩니다. 다음으로는 BLACK을 삽입해봅시다.
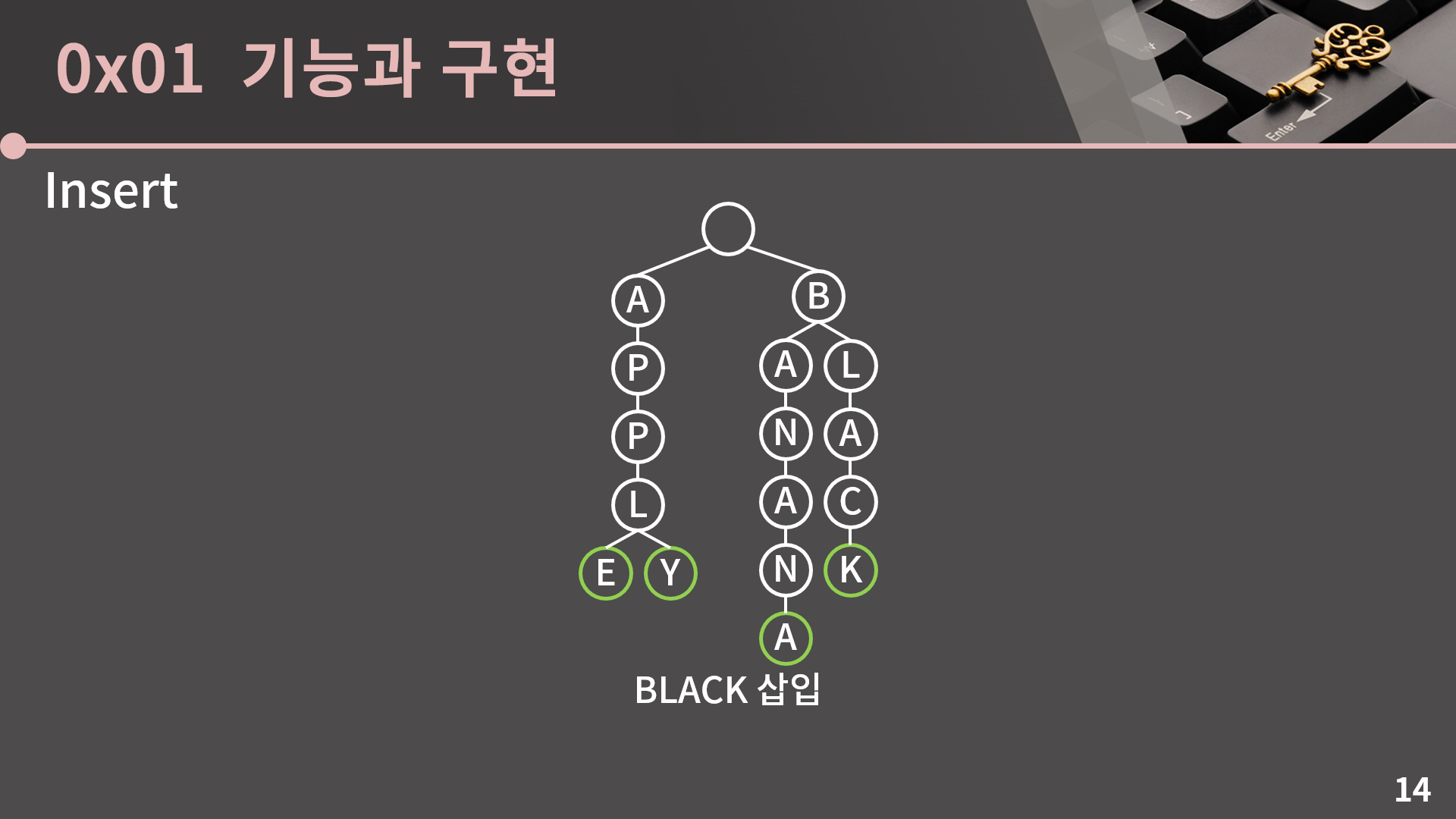
아마 예상하는 모양 그대로일 것 같습니다. 마지막으로 BAN을 삽입해보는 상황만 확인해보고 Fetch로 넘어가겠습니다.
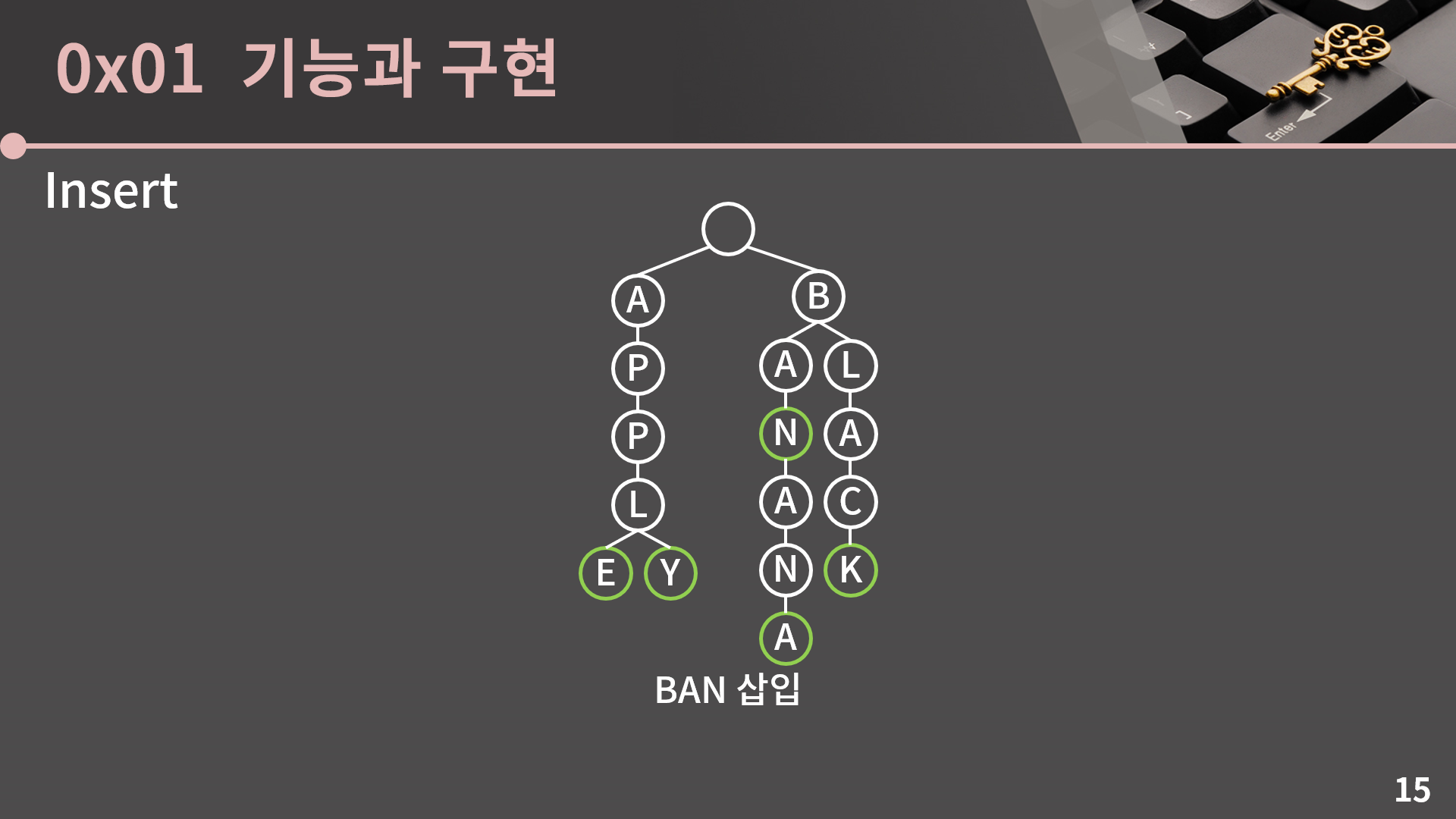
BAN을 삽입하면 새로 추가되는 정점이 없고 기존에 있던 정점만을 그대로 타고 가게 됩니다. 트라이에서 단어를 삽입한 후에 초록색으로 나타낸 별도의 표시를 해주는 이유를 여기서 알 수가 있는데, 만약 별도의 표시가 없다면 단어 BAN과 BANANA가 모두 삽입된 상태와 BANANA만 삽입된 상태를 구분할 수가 없습니다. 삽입은 여기까지만 살펴보겠습니다.
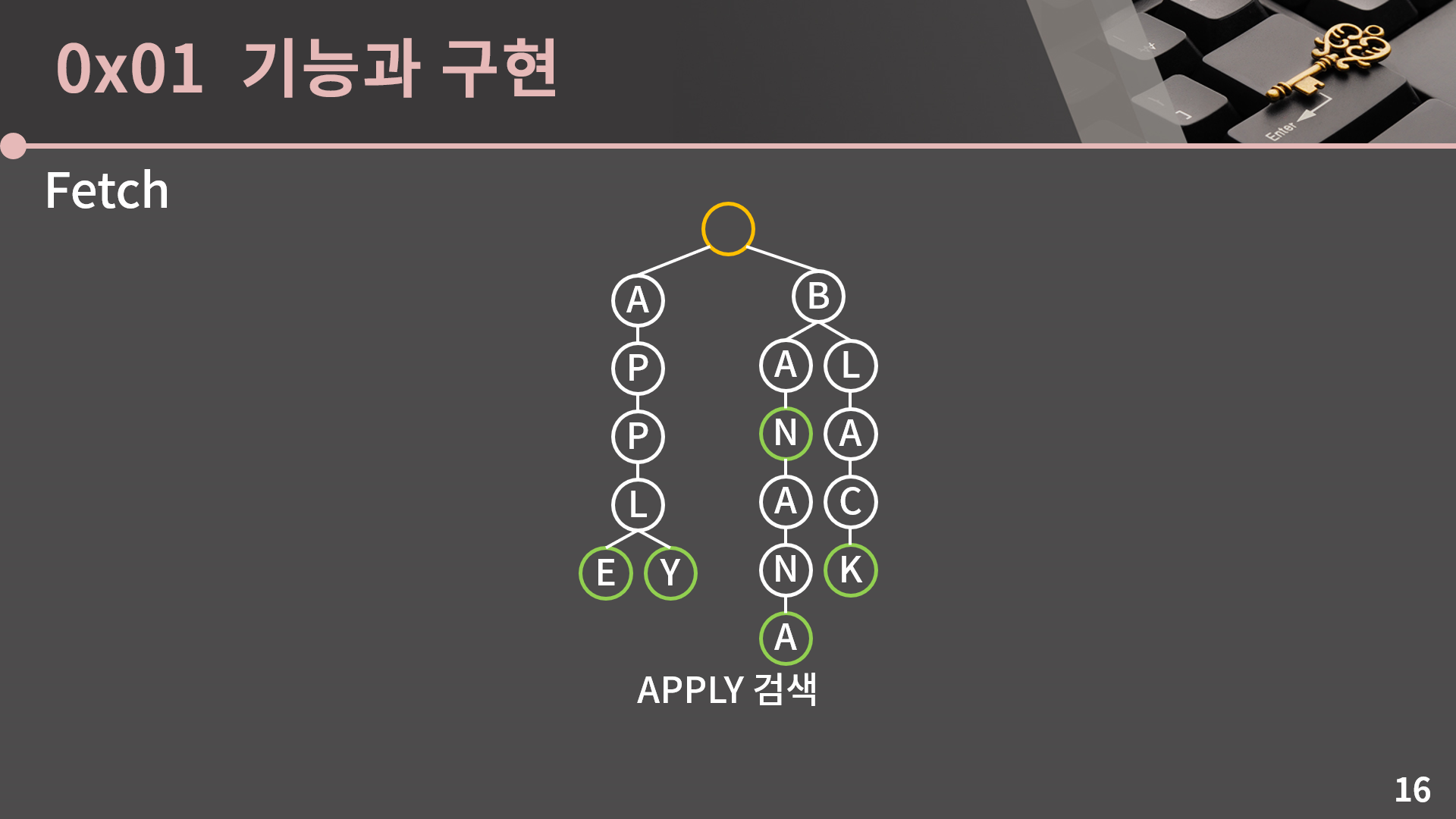
다음으로 특정 문자열이 있는지 검색을 해봅시다. 검색도 삽입과 크게 다를게 없습니다. APPLY를 검색해봅시다. 일단 루트에서 출발합니다.
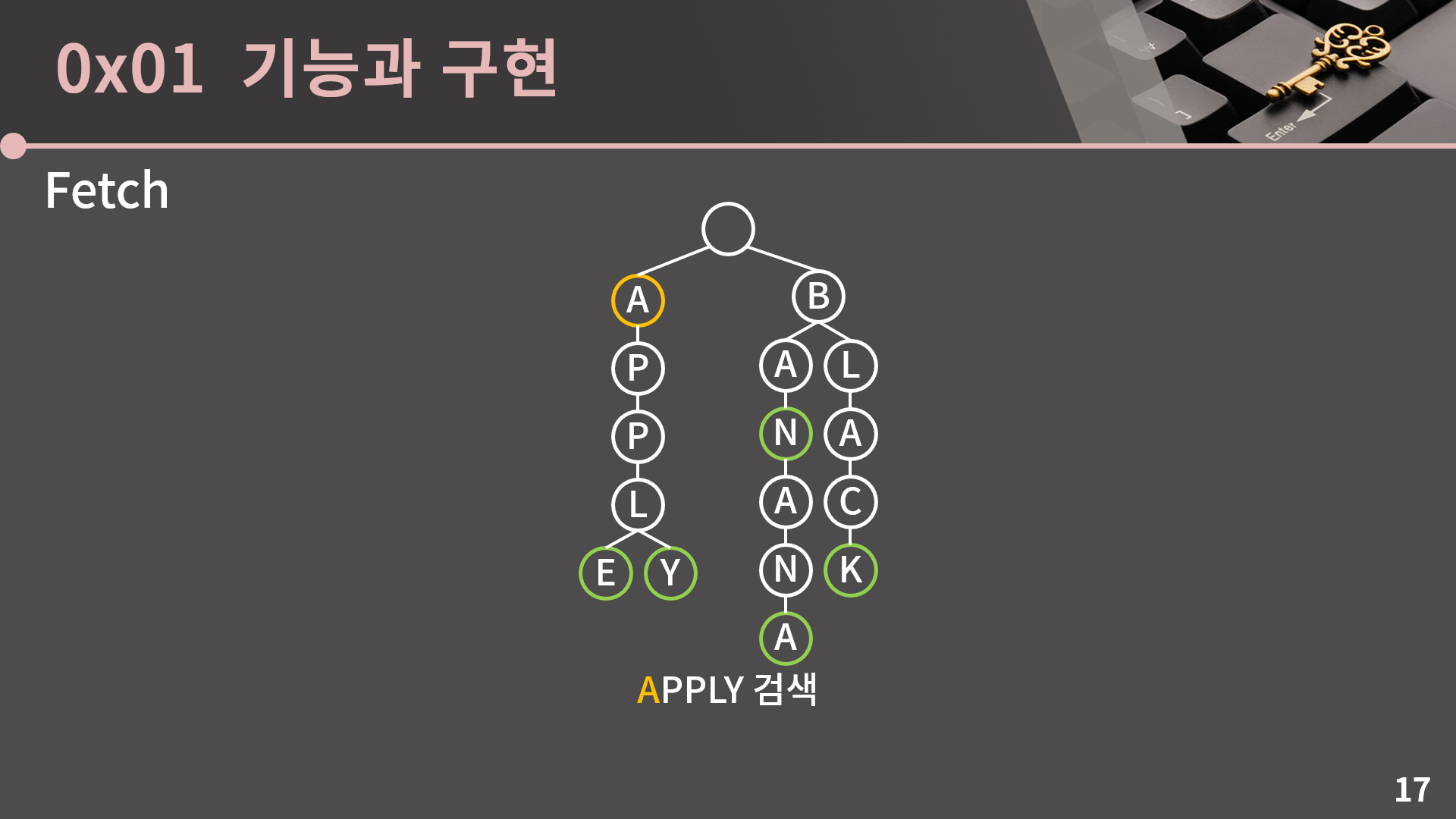
먼저 A로 가고

P로 가고
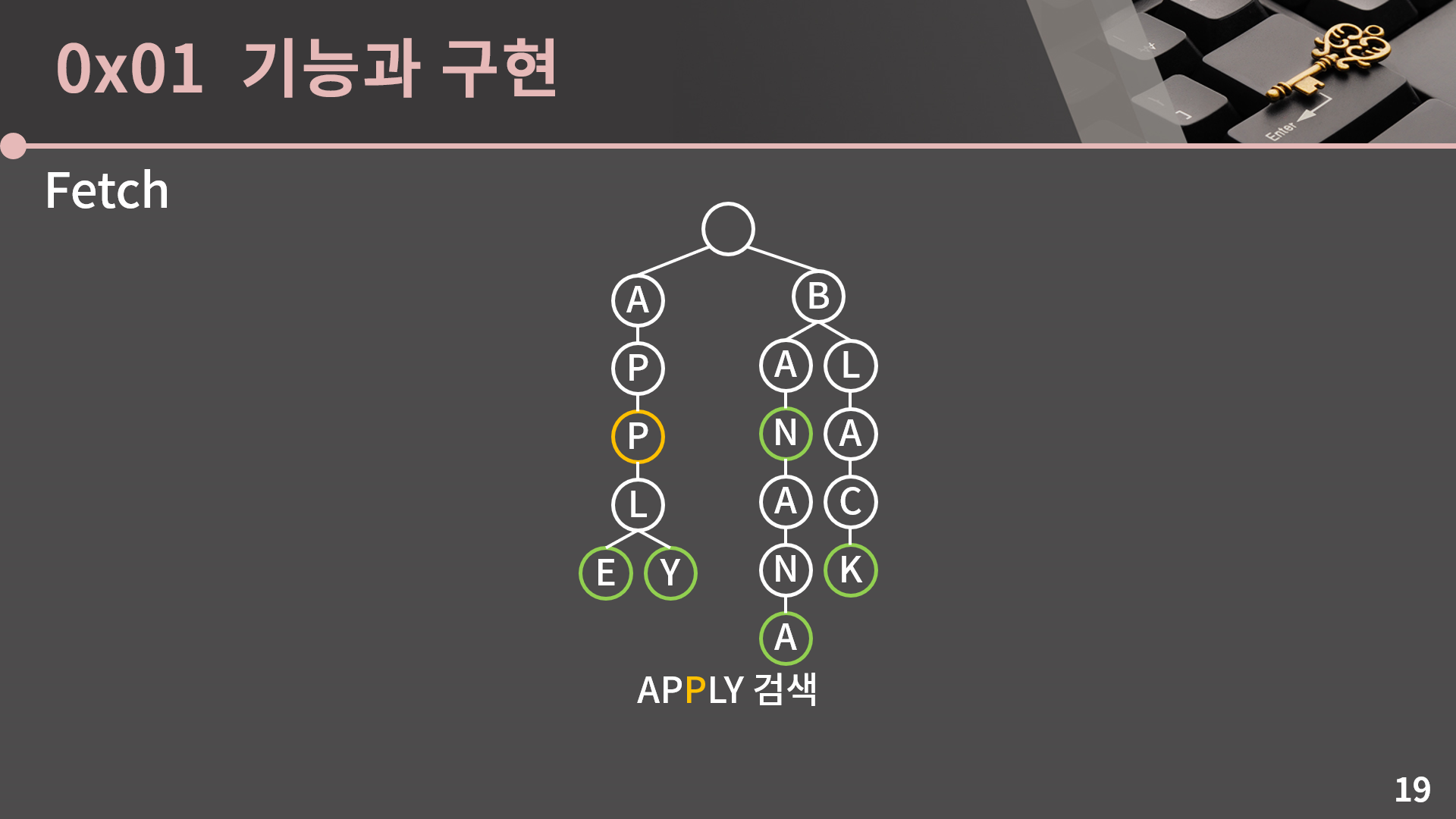
다시 P로 가고
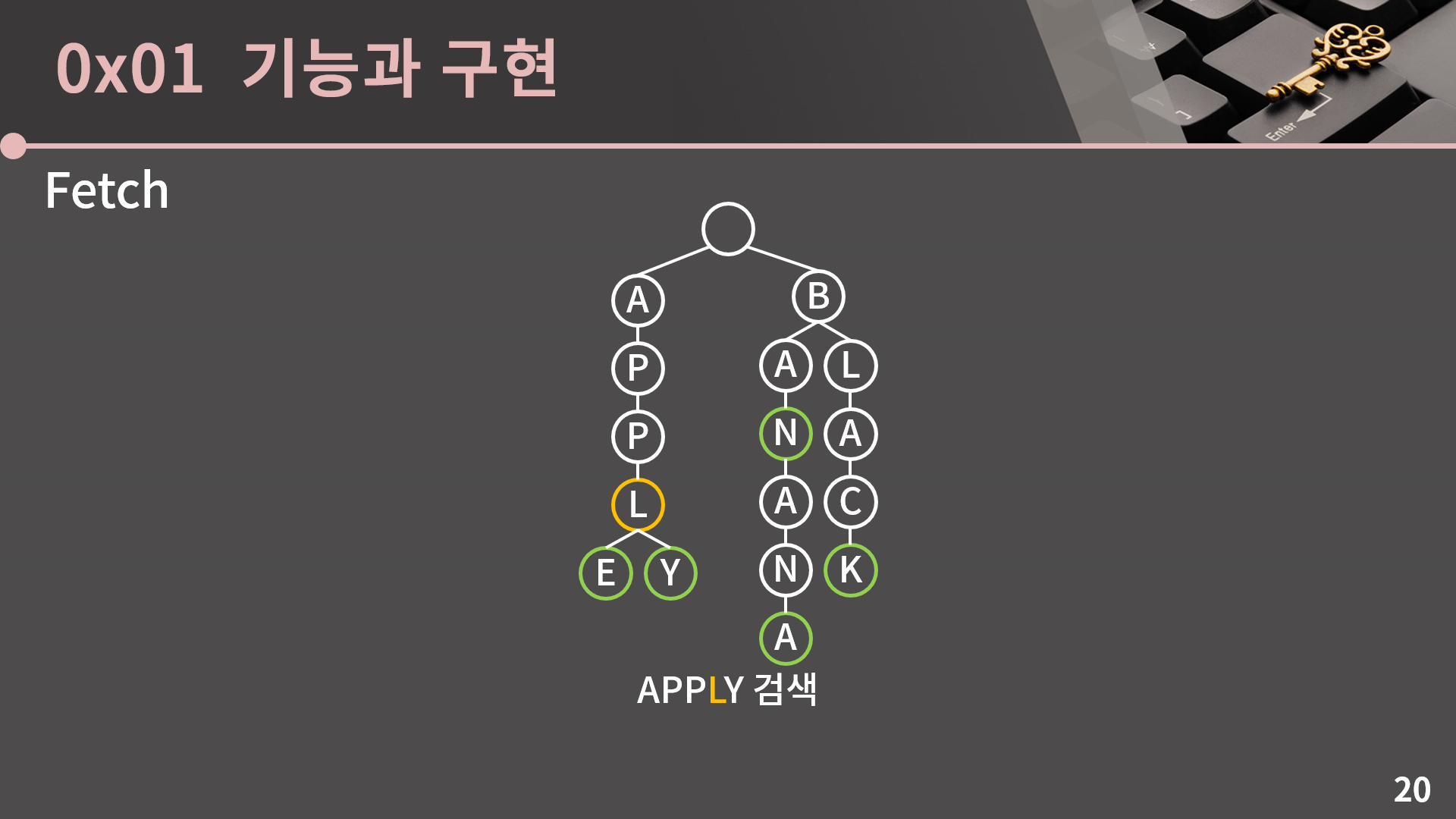
L로 가고
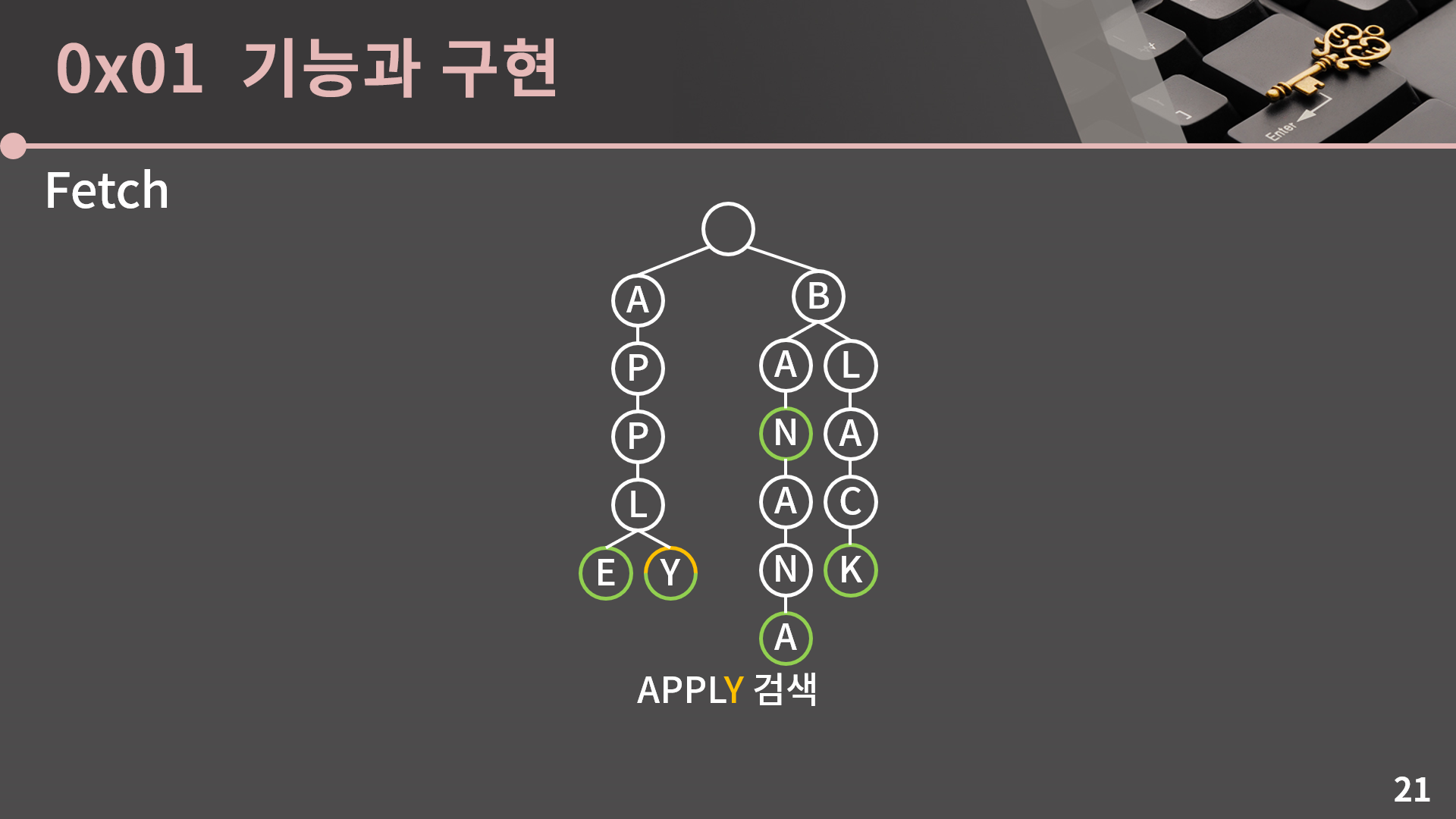
마지막으로 Y로 가면 여기에 단어가 있다는 표시가 있기 때문에 트라이 안에 APPLY가 있음을 알 수 있습니다.

이번에는 트라이에 없는 단어를 찾으려고 해봅시다. BASE를 찾으려고 합니다. 그러면 먼저 루트에서 출발합니다.
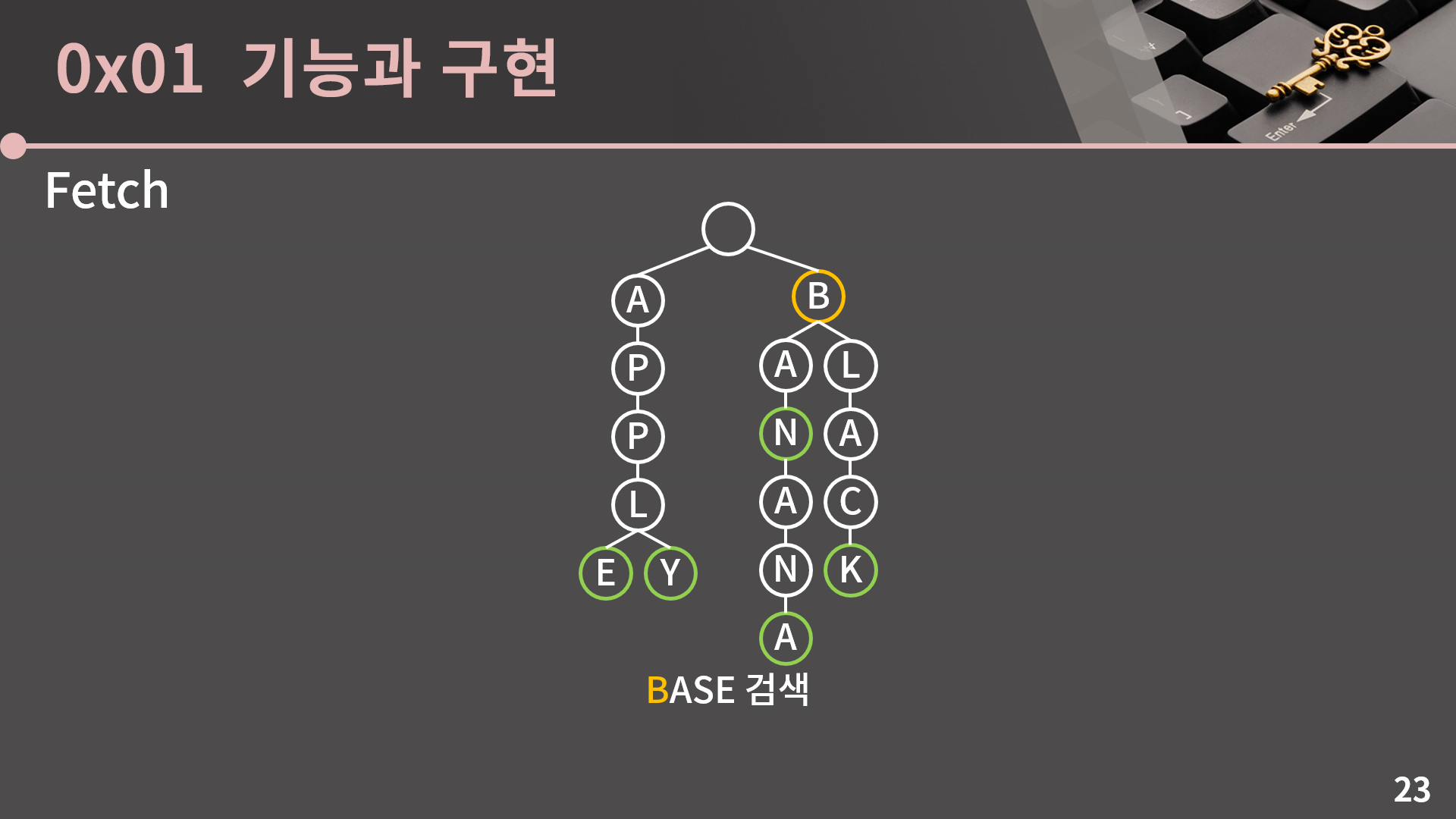
B로 가고

그 다음 A로 간 것 까지는 좋은데
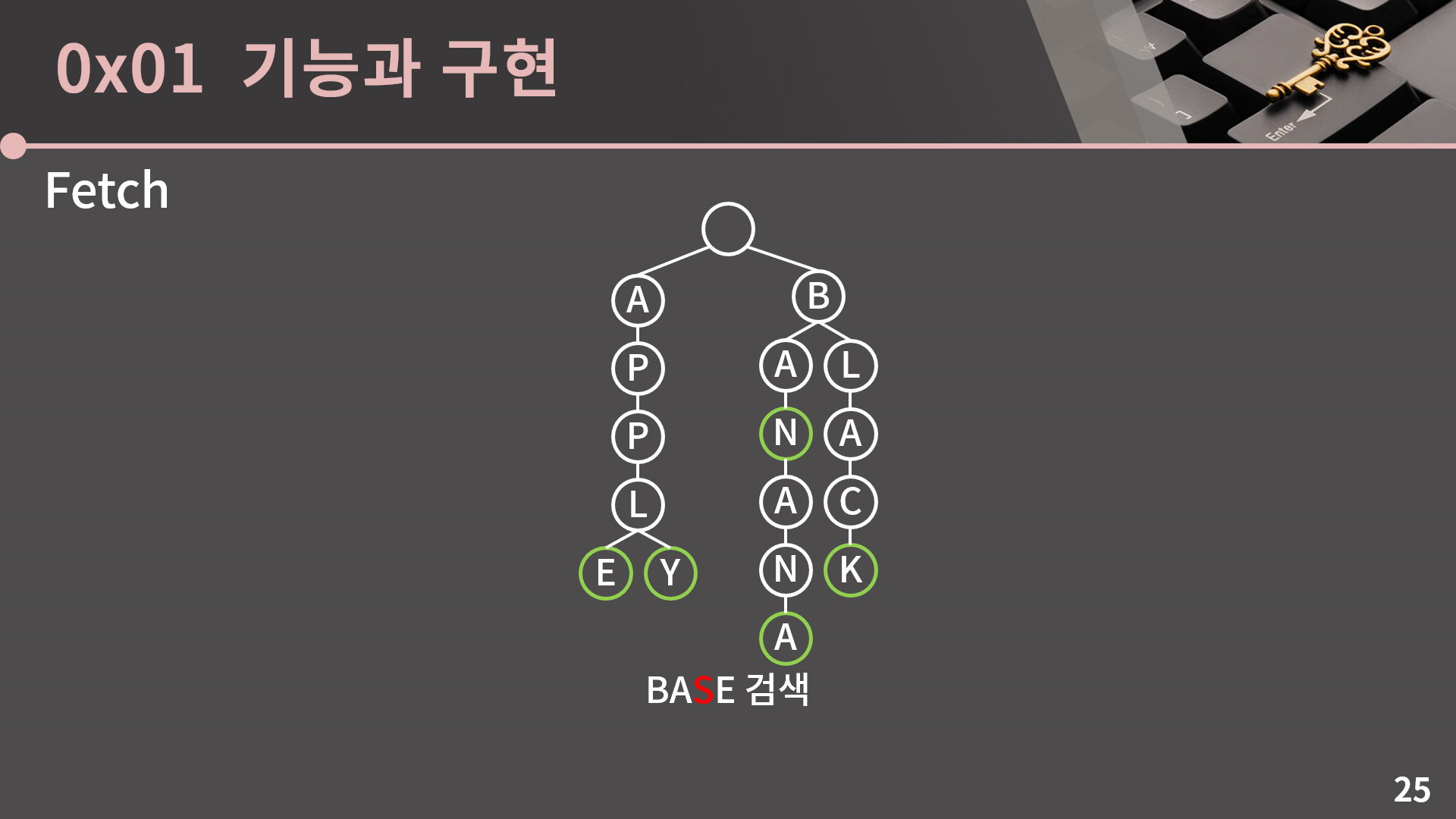
아쉽게도 A 밑에 S는 없습니다. 그래서 트라이 안에 BASE는 없다는걸 알 수 있습니다.
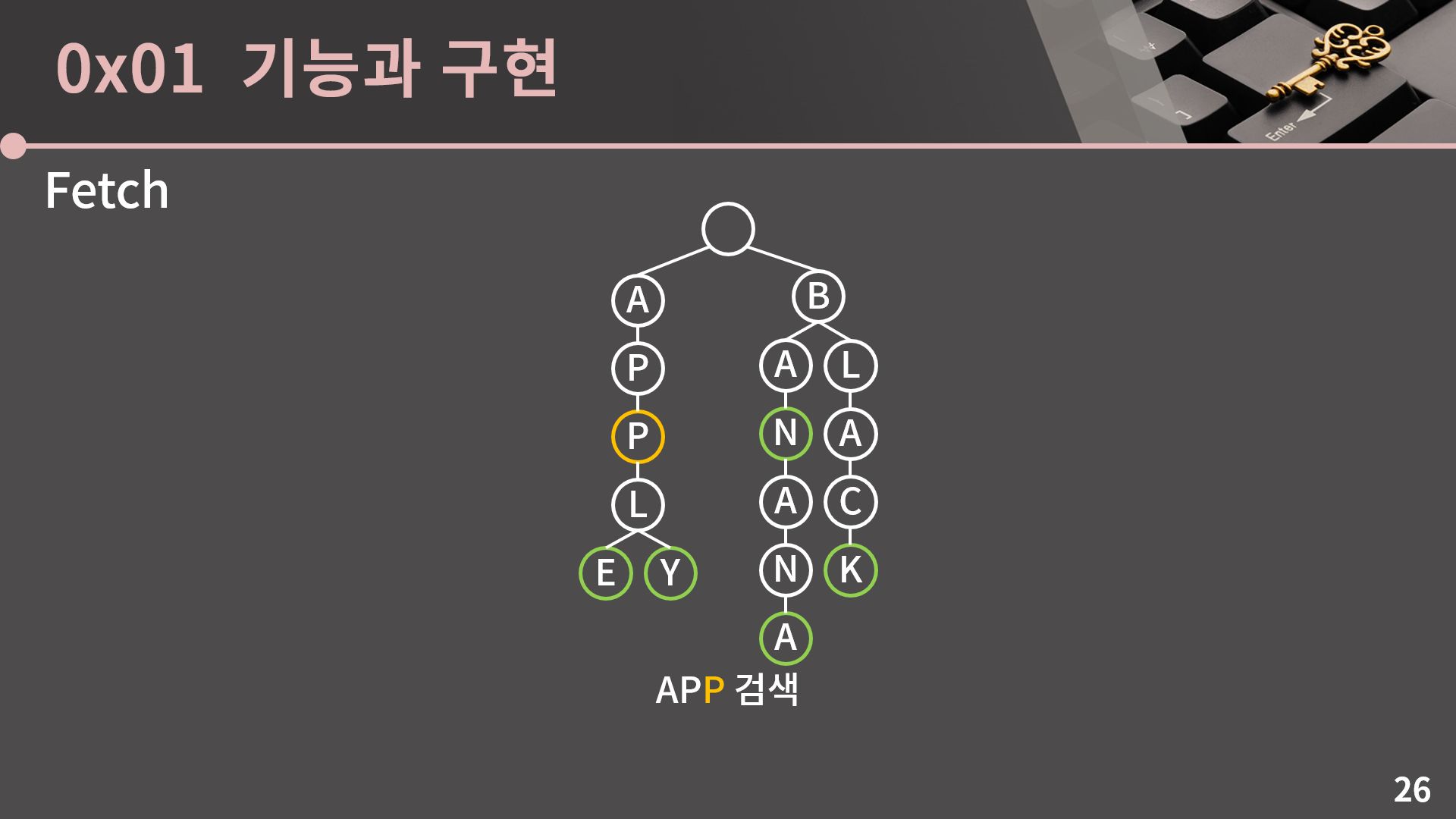
트라이에 없는 단어를 찾는 또 다른 예시를 살펴보겠습니다. 이번에는 APP을 검색해보겠습니다. 따라가는 과정은 생략을 하겠습니다. 마지막 글자인 P까지 잘 도착했지만 이 정점은 단어의 끝이라는 초록색 표시가 된 정점이 아니기 때문에 트라이 안에 APP은 없습니다. 처음에 트라이가 익숙하지 않을 때 지금과 같은 케이스를 실수로 놓치는 경우가 종종 있어서 검색을 할 때 단어의 끝에 도달했는지를 확인해야한다는걸 주의해주세요.
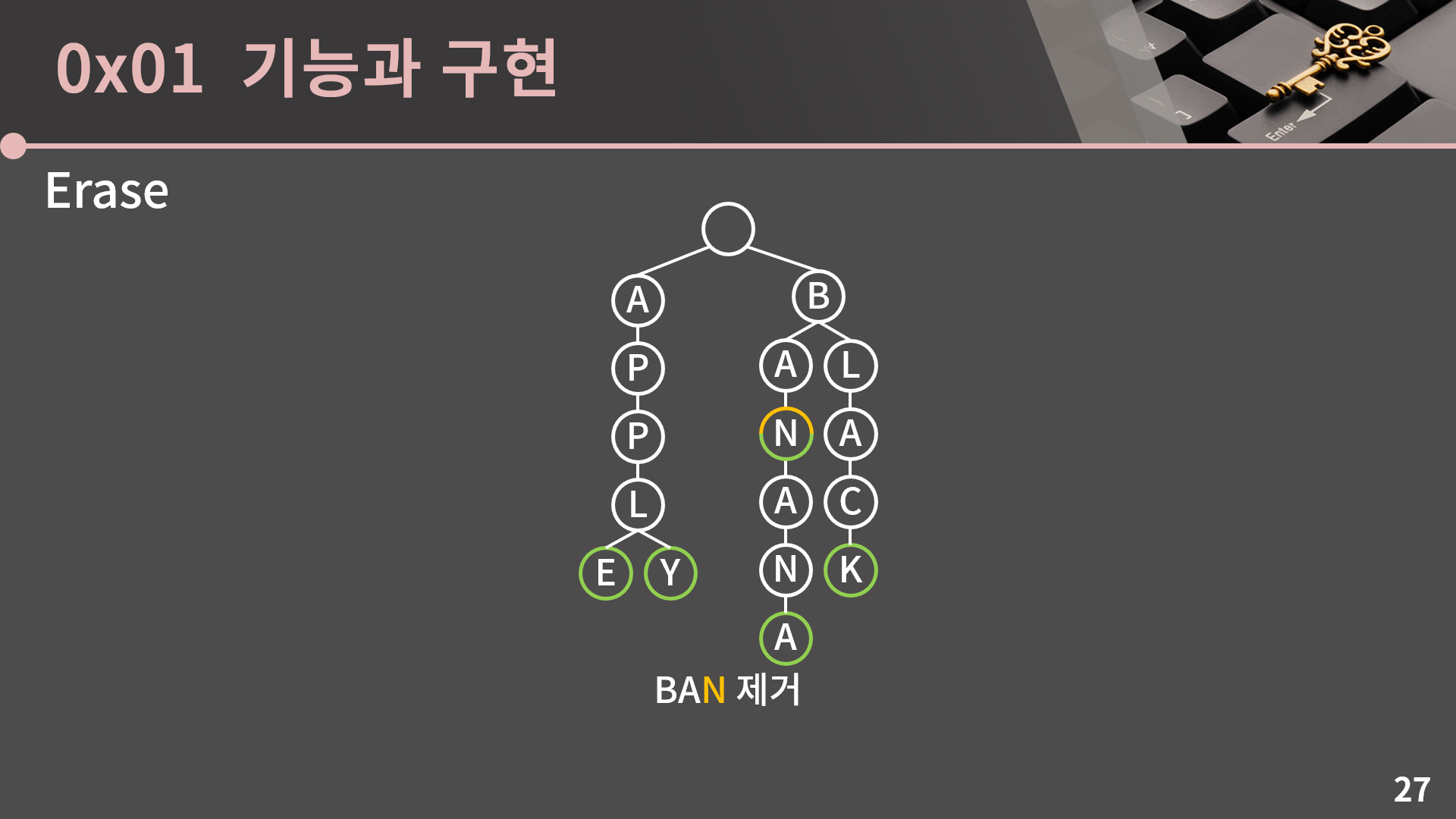
제거도 별다를게 없습니다. 예를 들어 BAN을 제거한다치면 앞에서 하던대로 해당 위치까지 일단 찾아갑니다.
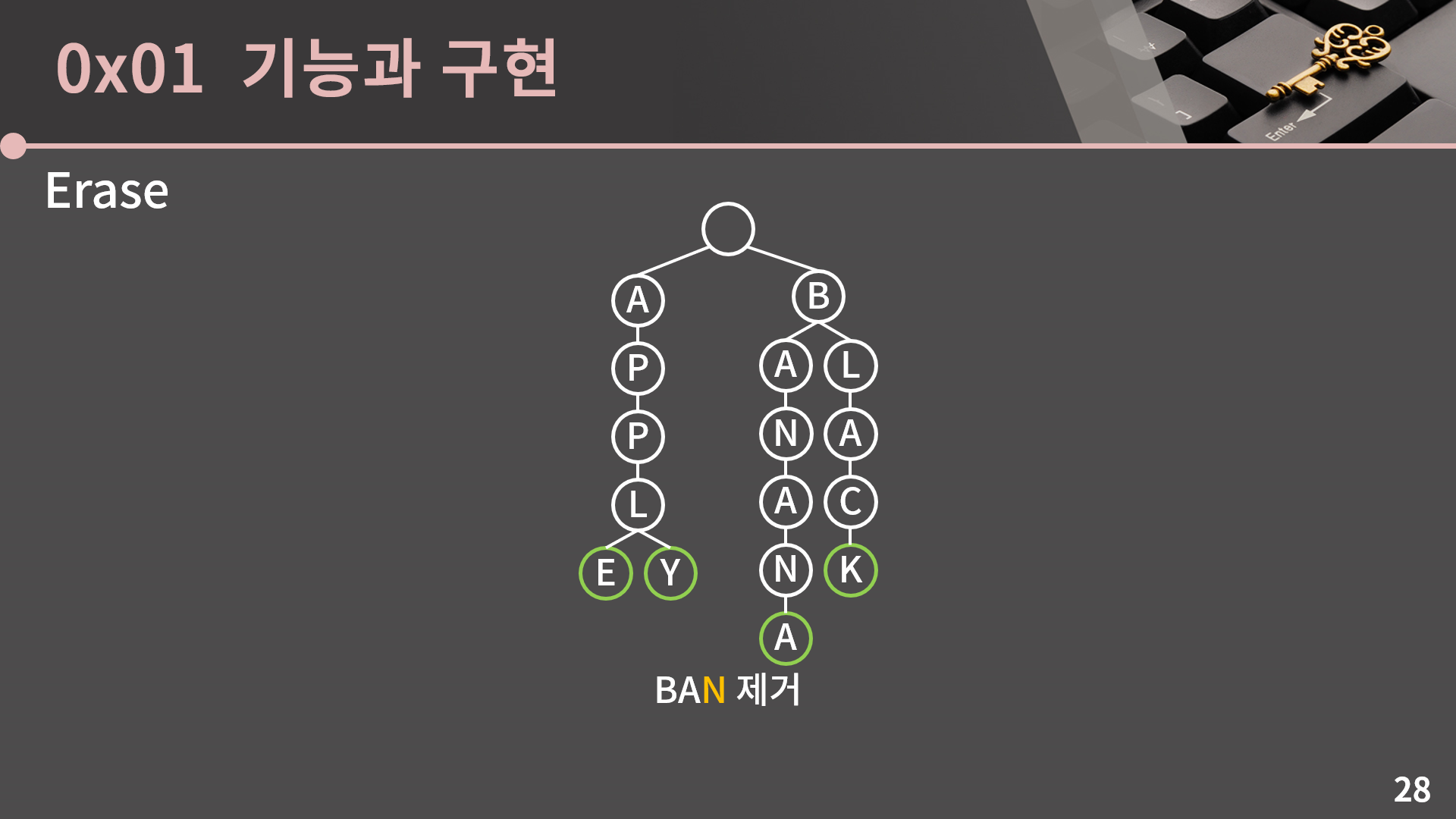
그런 다음 그냥 초록색 표시를 없애면 BAN이 제거됩니다. 단 트라이 구조를 망칠 수는 없기 때문에 정점 자체를 제거하면 안됩니다. 그렇기 때문에 트라이는 삭제를 하더라도 이전에 삽입한 정점들은 계속 메모리에 남아있게 되어 일종의 메모리 측면에서 비효율적이고 삭제가 계속 발생하는 환경에서는 트라이가 적합하지 않습니다.
이제 트라이가 무엇인지, 그리고 각 연산이 어떤 식으로 동작하는지는 이해를 다 하셨다고 생각합니다. 그런데 트라이는 구현이 조금 까다롭습니다. 노베이스인 상황에서 밑바닥에서부터 구현을 하기는 좀 많이 힘들다고 생각해서 일단은 저의 구현 코드 설명을 보면서 이해해보고, 나중에 제 코드 참고 없이 insert, find, erase 함수를 직접 짜보는 방식으로 공부를 하는걸 추천드립니다.

가장 먼저 쓰이는 변수들을 살펴보겠습니다. 저희는 각 정점에 번호를 부여할 예정입니다. 일단 루트의 번호는 1로 고정이고 새로 정점이 추가될 때 마다 2, 3, 4, ... 순으로 번호를 부여합니다. 이렇게 번호를 부여할 때 unused가 쓰이게 됩니다. 0x04강 - 연결 리스트에서 야매 연결 리스트를 구현할 때 unused가 쓰였던 것과 같은 맥락입니다.
MX는 최대 등장 가능한 글자의 수입니다. 이 값은 문제의 제한 조건으로부터 유추가 가능합니다. 예를 들어 조건 상으로 길이가 최대 500인 문자열이 10000개 들어오는 문제일 경우 10000 * 500으로 둘 수 있고 또 정점의 시작 번호가 0이 아니라 1이기 때문에 대충 +5 정도의 여유를 뒀습니다.
chk는 이전에 초록색 테두리로 보여드렸던, 해당 정점이 문자열의 끝인지 여부를 저장하는 배열입니다. 마지막으로 nxt는 각 정점에서 자식 정점의 번호를 의미합니다. 지금은 가능한 문자의 종류가 알파벳 소문자로 26개여서 nxt 배열을 nxt[MX][26]으로 선언했는데 만약 문자의 종류가 50개라면 nxt[MX][50]으로 선언을 해야 합니다. 자식 정점의 번호를 이렇게 관리하기 때문에 매 순간마다 이동해야 하는 자식 정점의 번호를 O(1)에 알 수 있지만, 단점으로는 각 정점마다 26칸을 할당하고 있어야 하기 때문에 메모리를 상당히 많이 사용합니다. 앞에서 트라이의 성질을 설명할 때 메모리를 무려 '4 × 글자의 종류'배 만큼 더 사용한다는게 여기서 나오는건데, 배열에 문자열을 그냥 저장하면 각 글자당 그냥 char 1칸이니 1바이트만 사용하는 반면 지금 이 구조에서는 자식 정점의 번호를 저장하기 위해 각 글자마다 int 26칸이 필요하니 무려 4 × 26바이트를 사용합니다. 일단 이 정도로만 이해하고 설명을 이어나가겠습니다. 07, 08번째 줄과 같이 nxt는 -1로 초기화시켜둡니다. 저희는 정점을 돌아다니다가 -1을 만나면 해당 자식 정점이 없다는 사실을 알 수 있습니다.
10-12번째 줄에 있는 c2i 함수는 글자를 받아 배열의 인덱스로 쓸 수 있게 변환하는 함수입니다. 지금은 대문자만 등장하는 상황을 생각해 'A'는 0, 'B'는 1, ..., 'Z'는 25에 대응시키는 함수인데 만약 대문자도 나오고 소문자도 나온다거나, 대문자와 소문자와 숫자가 모두 나온다거나 하면 이 함수를 상황에 맞게 바꿔 각 문자가 0부터 차례로 대응이 되게끔 해야합니다.
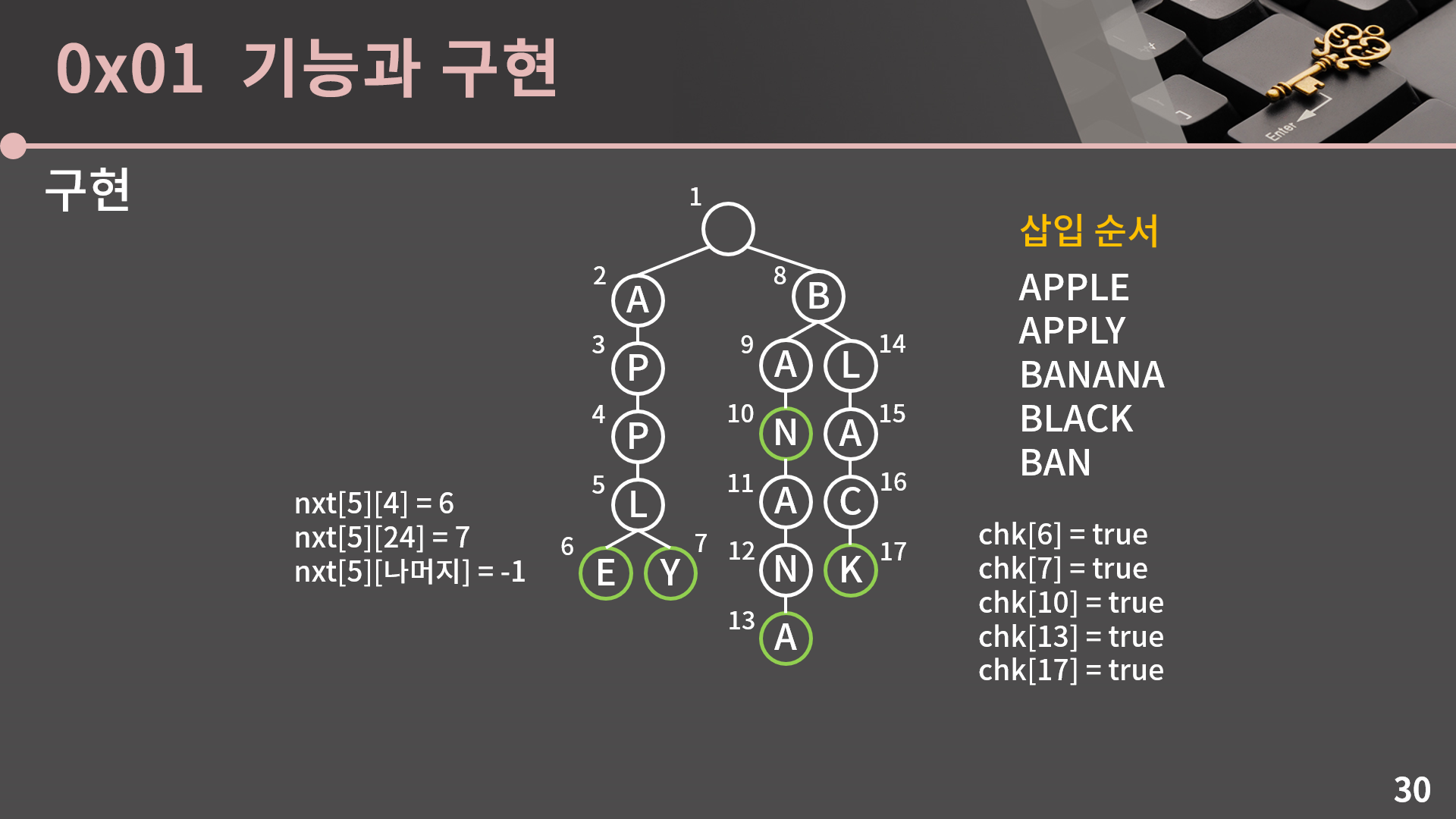
실제 트라이 구조를 놓고 설명을 드려보면 이런 식인데, 삽입을 하면서 정점이 새로 생기는 순으로 번호를 부여받습니다. 5번 정점의 자식에는 6번 E, 7번 Y 정점이 있는데 A = 0, B = 1, .. 이렇게 생각을 하면 E는 4이고 Y는 24이니 nxt[5][4] = 6, nxt[5][24] = 7이고 다른 자식 정점은 없어서 나머지 인덱스에 대해서는 nxt[5][...] = -1입니다. chk 배열은 문자열이 끝인 경우에만 true이니 6, 7, 10, 13, 17에서는 true이고 나머지는 false입니다.

이제 트라이에서 필요한 각 변수가 무엇을 나타내는지는 충분히 이해가 됐다고 봅니다. 바로 insert 함수부터 확인해봅시다. 앞에서 같이 살펴본 삽입의 과정을 떠올리면서 코드를 보면 이해에 도움이 될 수 있는데, 일단 cur가 앞에서 주황색으로 표시했던 현재 보고 있는 정점입니다. 초기값은 02번째 줄과 같이 ROOT입니다. 그 다음으로 for문을 이용해 글자를 하나씩 따라가며 글자에 대응되는 자식 정점으로 이동합니다. 만약 nxt[cur][c2i(c)]가 -1이라면 자식 정점이 없다는 의미이기 때문에 새로운 정점 번호, 즉 unused를 자식 정점에 줍니다. 그리고 unused++이니 unused는 값이 1 증가합니다. 이후 cur를 nxt[cur][c2i(c)]로 이동시키면 됩니다. 이렇게 이동이 끝난 후에는 chk[cur]를 true로 만들면 됩니다.
아마 코드를 보기 전에는 정점을 새로 생성하는걸 어떻게 구현해야할지 감이 잘 안왔을 수 있는데 보시는 것과 같이 그다지 어렵지 않게 처리가 가능합니다.
insert 코드를 잘 이해했으면 find, erase 함수는 insert 함수를 참고해서 구현을 할 수 있을거라고 생각합니다. 시도를 해보셔도 좋고, 아니면 제 코드를 바로 확인하셔도 됩니다.

find 함수에서도 마찬가지로 자식 정점으로 계속 이동합니다. 단, insert와 다르게 존재하지 않는 자식 정점을 만나면 바로 false를 반환합니다. 마지막 글자에 대응되는 정점에 도달한 후에는 바로 chk[cur]를 반환하면 됩니다.

erase 함수 또한 자식 정점으로 계속 이동합니다. 만약 존재하지 않는 자식 정점을 만나면 string s가 트라이에 없다는 의미이니 return을 통해 그대로 함수를 종료하고, 마지막 글자에 대응되는 정점에 도달했다면 chk[cur]를 false로 만듭니다. 만약 반드시 트라이에 존재하는 문자열에 대해서만 erase 함수가 호출된다는 조건이 있을 경우에는 04, 05번째 줄을 생략할 수 있습니다. 코드는 깃헙에 올려두었고 함수 내용을 지운채로 직접 한 번 구현해보는걸 추천드립니다. (코드)
한편 트라이를 이전에 배우셨거나 다른 사람들의 코드를 살펴본 적이 있으시다면 정점을 구조체로 선언하고 자식 정점의 정보를 인덱스로 관리하는 대신 포인터로 관리하는 경우를 흔하게 볼 수 있습니다. 그러면 저는 왜 이런 식으로 구현을 했냐 했을때, 이건 마치 정석적인 연결 리스트 구현 vs 야매 연결 리스트의 관계와 같은 느낌입니다. 여기서 소개드린 제 구현체는 최대 등장 가능한 글자의 수를 미리 계산해 아주 큰 배열을 선언해야 하기 때문에 입력의 범위가 정해진 상황에서만 사용할 수 있는 반면(chk, nxt를 배열 대신 vector와 같은 동적배열로 두면 이 문제를 해결할 수 있지만 관련 설명은 생략하겠습니다) 정점을 동적 할당으로 생성하고 자식 정점을 포인터로 관리하면 더 일반적인 상황에서 적용이 가능합니다. 하지만 알고리즘 문제를 푸는 환경에 한해서는 제 구현체가 더 좋습니다. 64비트 컴퓨터 기준으로 포인터는 8바이트입니다. 그렇기 때문에 자식 정점을 포인터로 관리하면 제 코드와 같이 자식 정점을 int 인덱스로 둘 때에 비해 메모리를 2배 더 사용하게 됩니다. 가뜩이나 트라이가 메모리를 굉장히 많이 사용하는 구조임을 생각해보면 메모리를 2배 더 쓰는건 굉장히 바람직하지 않습니다. 그렇기 때문에 알고리즘 문제를 풀 때 트라이를 쓰는 경우에는 포인터로 자식 정점을 관리하는 대신 제 코드와 같이 큰 배열을 하나 잡고 인덱스로 자식 정점을 관리하는걸 추천드립니다.
한편 트라이에서 메모리를 줄이는 방법에 대해 간략하게 짚고 넘어가겠습니다. 이 내용은 트라이와 STL에 대한 이해가 충분하지 않으면 좀 많이 어렵게 느껴질 수 있어서 자세하게 안들어가고 아주 피상적으로만 다룰거고, 대회를 노리는 사람 기준으로 알아두면 좋은 내용이긴 하지만 만약 설명을 들었을 때 잘 이해가 가지 않는다면 건너뛰었다가 나중에 다시 확인하셔도 상관은 없습니다.
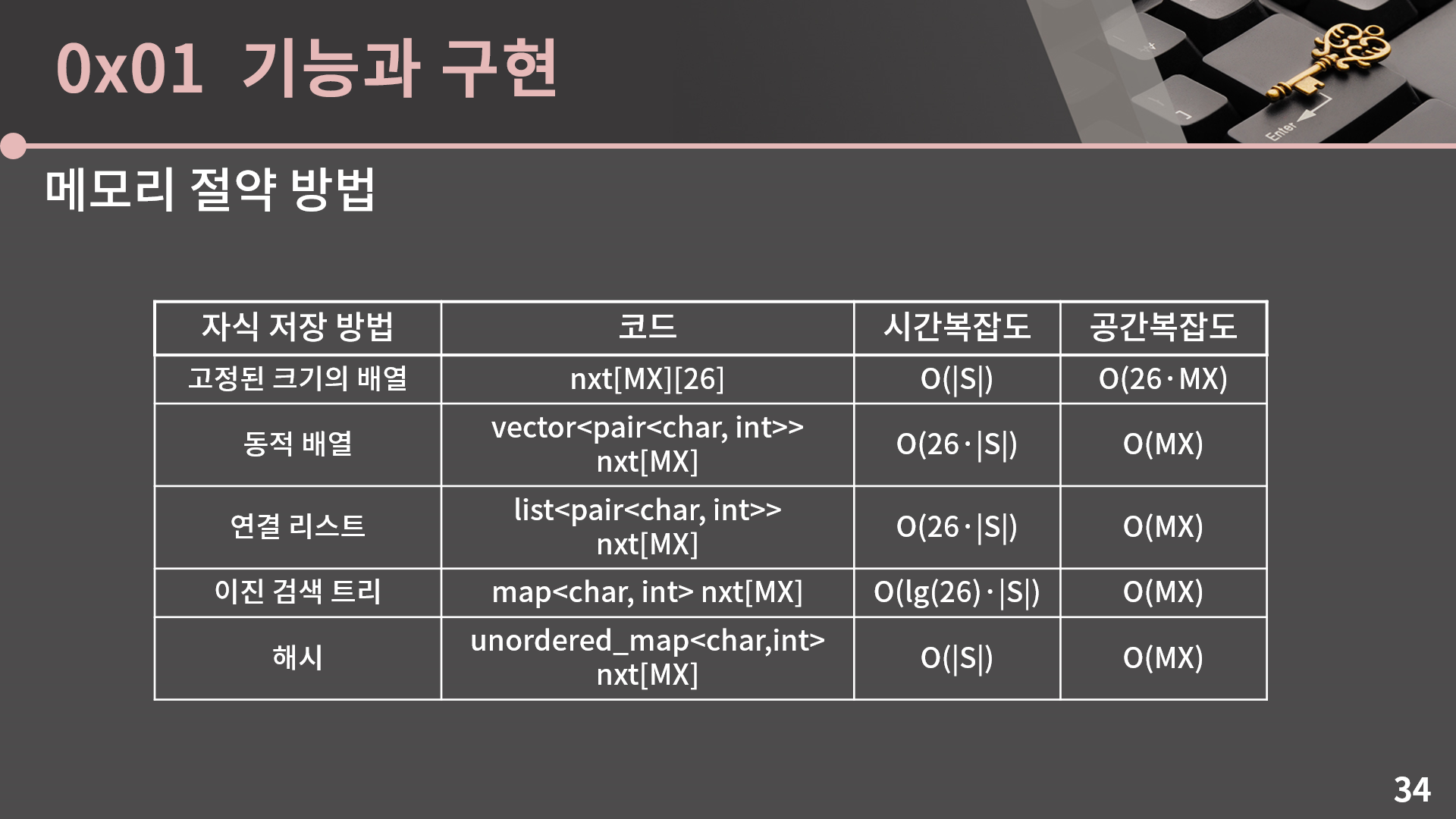
앞에서 보여드린 코드에서는 각 정점에서 특정 문자에 대응되는 자식 정점을 O(1)에 찾을 수 있도록 하기 위해 자식 정점의 인덱스를 nxt[MX][26] 배열에 저장합니다. 여기서 MX는 앞에서 언급했듯 최대 등장 가능한 글자의 수이고 이 문제에서는 N·|S|으로 계산할 수 있습니다. 그런데 이렇게 되면 필요한 메모리의 양이 너무 커지는 문제가 생깁니다. 가능한 문자의 종류가 26개이면 그나마 나은데 한글 혹은 한자와 같이 문자의 종류가 엄청 많을 경우에는 nxt[MX][10000]과 같은 배열을 잡는게 현실적으로 불가능합니다. 이럴 때에는 자식 정점을 O(1)보다 느리게 찾더라도 메모리를 절약하는 방법을 사용할 수 있습니다. 첫 번째 방법은 각 정점당 26칸을 할당하는 대신 vector와 같은 동적 배열을 사용하는 방법입니다. 예를 들어 자식 정점이 E, Y 2개가 있고 각각 6번과 7번이라면 동적 배열에 ('E', 6), ('Y', 7)을 담는 방법입니다. 이렇게 하면 자식 정점을 찾기 위해 최악의 경우 매 순간마다 26번의 탐색을 해야하기 때문에 시간복잡도는 O(26·|S|)로 늘어나지만 공간복잡도는 O(MX)로 줄어듭니다. 동적 배열 대신 연결 리스트를 사용해도 동일한 상황입니다.
동적 배열 혹은 연결 리스트 대신 이진 검색 트리나 해시를 사용하는 방법도 있습니다. 자식 정점을 이진 검색 트리나 해시로 관리하면 시간복잡도는 각각 O(lg(26)·|S|) 혹은 O(|S|)가 되고 공간복잡도는 그대로 O(MX)이지만 이진 검색 트리나 해시 자료 구조의 오버헤드가 더 크기 때문에 실제로 사용하는 메모리는 동적 배열이나 연결 리스트에 비해 더 클 것으로 예상할 수 있어요.
보통 트라이로 푸는 것을 의도하고 낸 문제에서는 고정된 크기의 배열로 잡아도 메모리 초과가 발생하지 않도록 제한을 두는 일이 대부분이긴 하지만 아주 간혹 문자의 종류가 너무 많다던가 하는 이유로 메모리를 계산했을 때 메모리 초과가 발생할 것 같은 상황에서는 여기 나와있는 것과 같이 자식 정점들을 다른 방법으로 저장하는 것을 고려해볼 수 있습니다.
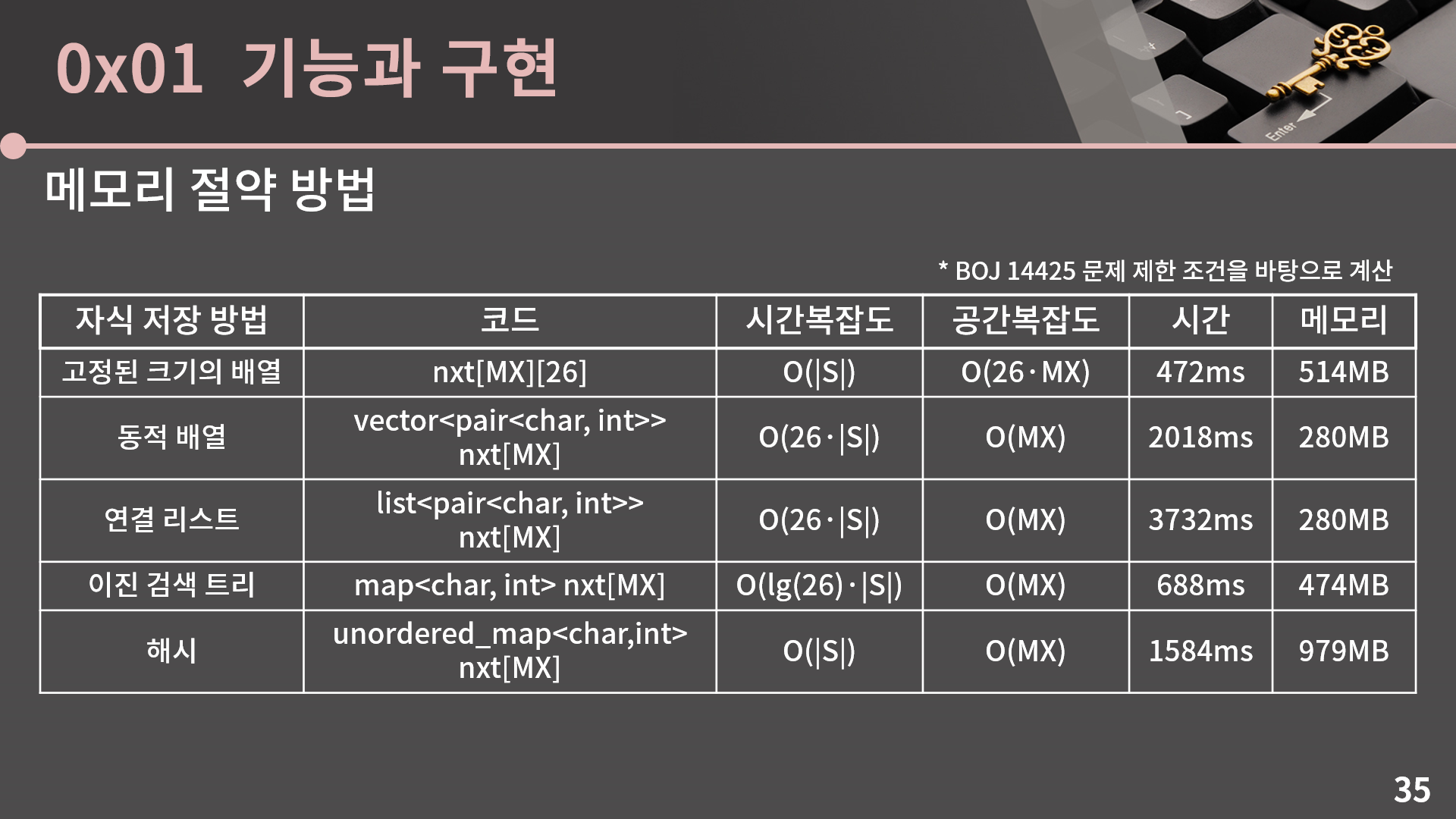
자 그런데 저희는 결국 실전적으로 문제를 풀 때 상황이 어떻게 되는지가 궁금합니다. 이론적으로만 보면 자식을 해시로 저장하는게 제일 좋습니다. 시간복잡도와 공간복잡도가 다 최소이기 때문입니다. 그런데 실제로 짜서 돌려보면 그렇지가 않습니다. 제가 실험을 진행한 BOJ 14425 문제는 바로 뒤에서 같이 풀어볼 예정이라 지금 굳이 보고 올 필요는 없습니다. 문제의 상황을 간단하게 설명을 드리면 길이가 500인 단어를 최대 10000번 삽입하고 또 10000번 검색합니다. 이 때 단어는 영어 소문자로만 이루어져 있습니다. 그리고 트라이를 저 5개 각각으로 짜서 돌려보면 시간과 메모리가 저렇게 됩니다.
일단 메모리부터 확인해보면 이론적으로는 고정된 크기의 배열 말고 나머지 4개를 쓰면 공간복잡도에 글자의 종류와 관련된 값이 빠져서 엄청 줄어들어야할 것 같은데 실제로는 그렇지가 않습니다. 강의에서 STL vector나 list 등의 내부 구조까지 다루지는 않았지만 중요한건 오버헤드가 꽤 크다는 사실입니다. 예를 들어 설명을 하면 vector에서는 실제 데이터가 들어가는 곳의 시작과 끝 주소도 저장하고 있다던가, list에서는 각 원소가 이전과 다음 원소의 주소를 들고 있는 등의 이유로 그냥 고정된 크기의 배열에서는 자식 하나당 정직하게 int 1개인 4바이트씩 차지하는 것과 다르게 STL 구조의 특성상 소모되는 별도의 메모리가 있습니다. set와 unordered_set은 구조가 더 복잡하니 말할 필요도 없이 vector, list보다도 훨씬 오버헤드가 큽니다. 그렇기 때문에 동적 배열과 연결 리스트 방식에서는 메모리가 줄긴 하지만 이론적인 수치처럼 26배씩 감소하는건 아니고 한 2배 정도만 감소합니다. 또 이진 검색 트리는 그냥 고정된 배열을 쓰는 것과 거의 비슷한 메모리 사용량을 보여주고 해시는 오히려 메모리 사용량이 훨씬 더 큽니다. 물론 문자의 종류가 26개가 아니라 60개 이런식으로 더 많았다면 감소되는 정도가 더 컸을 수 있지만 아무튼 생각만큼 메모리의 감소가 많이 일어나지는 않는다는 점을 확인 가능합니다.
다음으로 시간을 살펴보면 고정된 크기의 배열을 이용하는게 제일 빠르고 동적 배열과 연결 리스트로 냈을 땐 더 느립니다. 동적 배열과 연결 리스트에서 시간이 더 오래 걸리는 이유는 자식을 O(1)에 찾는게 아닌 O(26)에 찾기 때문인데, 사실 최악의 경우에 26번 탐색을 해야하는건 맞지만 그렇다고 정말 매번 26번 탐색을 하는건 아닐테니 26배까지는 아니고 4-8배 정도 느린 것을 확인 가능합니다. 참고로 맨 처음 강의 자료를 만들면서 동적 배열과 연결 리스트 각각으로 구현을 해서 내봤더니 실행 시간이 별 차이가 없길래 직접 자식을 탐색하는데 오래 걸릴 데이터를 만들어서 추가했습니다. 문제의 요청 게시판을 보시면 제가 데이터 추가 요청을 했던걸 확인할 수 있습니다. 다음으로 이진 검색 트리는 어느 정도 빠르긴 하지만 당연히 고정된 크기의 배열을 이용하는 것 보다는 느리고, 해시는 영 못써먹을 물건이 됐습니다.
정리하면 트라이 문제를 만났을 때에는 자식을 그냥 고정된 크기의 배열로 푸는게 제일 낫습니다. 그런데 출제자가 메모리 제한을 너무 낮게 세팅해서 사용되는 메모리의 양을 따져보니 고정된 크기의 배열을 이용할 경우 무조건 메모리 초과가 발생한다면 정말 어쩔 수 없이 자식을 동적 배열, 즉 vector를 써서 관리하는 방식으로 선회를 할 수 있습니다. 그 외에 연결 리스트/이진 검색 트리/해시를 쓰는 방법은 딱히 실전에서 활용 가치가 없습니다. 당장 저도 트라이가 정해인 문제를 만나면 여기 써놓은 것과 같이 일단은 고정된 크기의 배열로 풀었을 때의 메모리 사용량을 가늠해보고 메모리 제한 안에 들어오면 고정된 크기의 배열을 쓰고, 제한 안에 들어오지 못하면 vector를 써서 풉니다. 사실 정해가 트라이인 문제라면 메모리 제한을 넉넉하게 두는게 맞지만, 출제자가 악랄하거나 혹은 의도한 풀이는 다른 알고리즘이고 트라이 풀이를 인지하지 못했다면 가끔 메모리에서 문제가 생기는 일이 발생할 수 있어서 동적 배열을 쓰는 방식 정도는 익혀두면 절체절명의 순간에서 큰 도움이 될 수 있습니다.
실전에서 쓸 일이 없는 것과는 별개로 자식을 동적 배열, 연결 리스트, 이진 검색 트리, 해시로 관리하는 코드를 작성해보는건 좋은 연습이 될 것 같아서 한 번 직접 짜보시는걸 추천드립니다. 제 코드를 굳이 소개할 생각은 없지만 제가 어떻게 짰는지 궁금하시면 BOJ 14425번 문제에 제가 제출한 코드들을 열어보세요.

어쩌다보니 연습 문제 챕터가 나오기 전에 먼저 문제를 소개했는데 아무튼 BOJ 14425번: 문자열 집합 문제를 트라이로 풀어봅시다. 물론 앞에서 본 코드를 그대로 가져오면 되긴 하지만 직접 풀어보는걸 추천드립니다.

저는 당연히 제 코드를 그대로 가져왔습니다. 앞쪽은 다 똑같습니다. 제거 연산은 등장하지 않기 때문에 코드 길이도 줄일겸 뺐습니다.

그리고 main에서는 그냥 n번에 걸쳐 insert하고, 또 m번에 걸쳐 find를 하면 끝입니다. 정말 트라이의 기초적인 예제같은 문제라 코드에서 설명할게 많지는 않습니다. (코드)
단 한 가지 생각해보면 좋을 점이 있는데, 지금은 삽입되는 문자열에 중복이 없다는 단서가 있습니다. 그런데 삽입되는 문자열에 중복이 있을 수 있다면 어떻게 될까요? 예를 들어 같은 문자열을 여러 번 삽입할 수 있고 find에서는 문자열 s가 들어있는 개수를 반환해야 하는 등 중복을 관리해줘야 하는 상황이 있을 수 있습니다. 이건 chk 배열을 약간만 잘 바꾸면 해결을 할 수 있고, 제가 답을 드리는 대신 여러분에게 생각해볼 거리로 남겨두겠습니다.
그런데 이 문제가 트라이 단원에 있으니 트라이로 해결을 했지, 만약 해시나 이진 검색 트리 단원에 이 문제를 뒀다면 굉장히 자연스럽게 이 둘을 이용해서 문제를 풀어냈을 것입니다. 그냥 해시 혹은 이진 검색 트리에 문자열을 다 넣어두고 검색을 하면 됩니다. 이 문제를 트라이, 해시, 이진 검색 트리 각각으로 풀었을 때 시간과 메모리를 확인해봅시다.
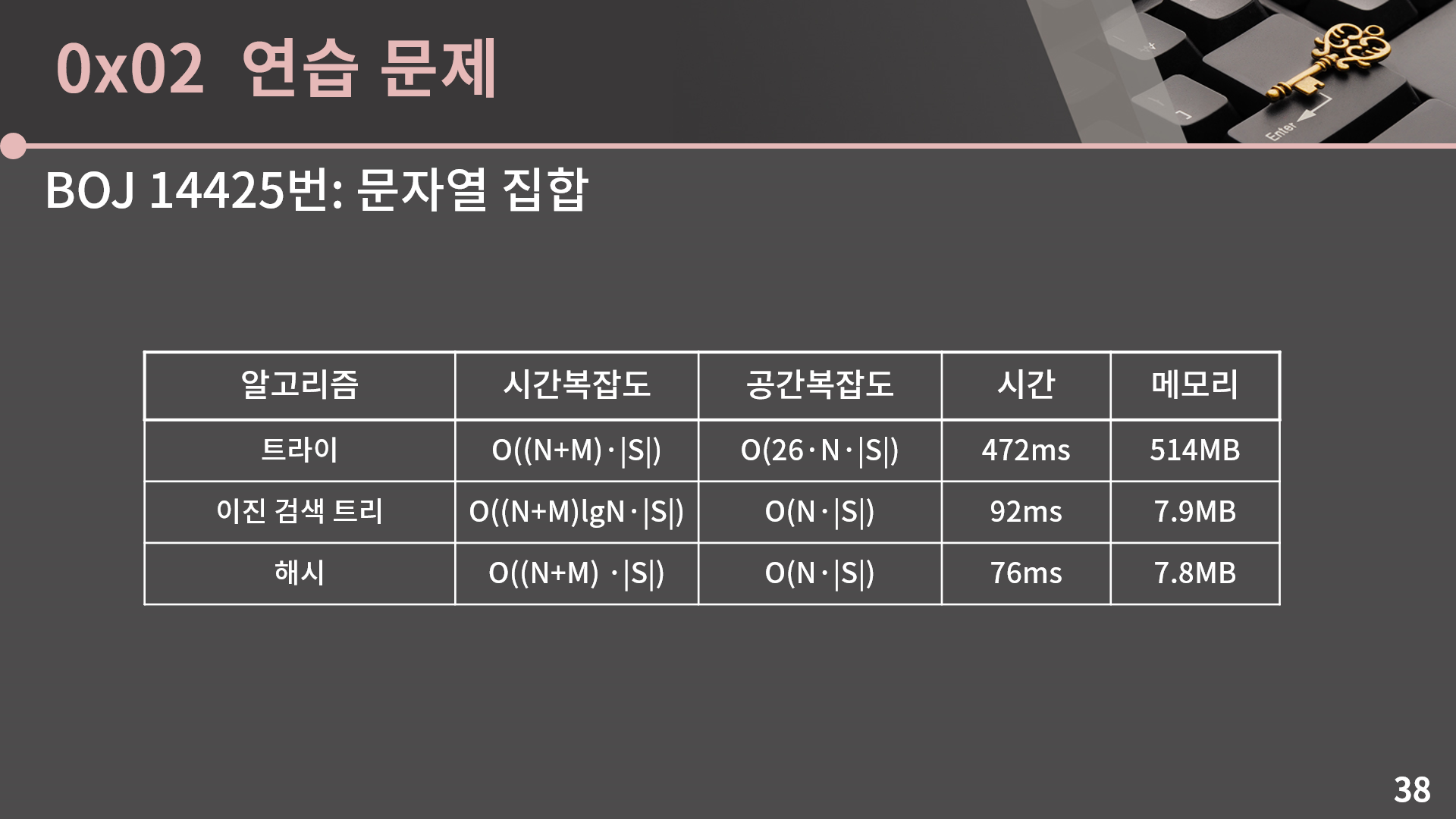
일단 이론적인 시간복잡도와 공간복잡도는 한 번 잘 이해해보시길 바라고, 실제 시간과 메모리를 보면 차이가 정말 어마어마합니다. 일단 시간도 트라이가 5-6배 가까이 느리고, 메모리는 무려 65배 가까이 더 많이사용합니다. 이진 검색 트리와 해시에서 메모리 사용량이 78MB, 79MB가 아니라 7.8MB, 7.9MB입니다.
먼저 시간이 왜 이렇게 차이나는지를 보면 기본적으로 메모리의 접근은 단순 연산보다 속도가 느립니다. 그런데 트라이에서는 정점을 정직하게 |S|칸 이동하고 심지어 이게 굉장히 큰 배열에서 이루어져서 cache hit rate가 굉장히 나쁩니다. 반면 이진 검색 트리나 해시에서는 트라이와 달리 정점의 이동이 그렇게 많지 않고, 두 문자열간의 비교를 이진 검색 트리 기준 O(lgN)번, 해시 기준 O(1)번 하긴 하지만 사실 문자열의 특성상 비교를 하다가 불일치가 발생하면 바로 비교를 종료하기 때문에 이론적으로 각 삽입/탐색 당 O(lgN·|S|) 혹은 O(|S|)인 것과 별개로 실제로는 더 빠르게 동작합니다. 그렇기 때문에 빅오표기법으로 나타내는 시간복잡도와 달리 실제로는 트라이보다 이진 검색 트리나 해시가 더 시간이 적게 걸립니다.
다음으로 메모리를 보면, 트라이가 메모리를 많이 쓰는거야 계속 언급했던거지만 이진 검색 트리나 해시에서는 각 글자가 1바이트 char인 반면 트라이에서는 자식 정보를 저장할 때 4바이트 int를 사용하기 때문에 이 문제처럼 글자의 종류가 26개일 때 무려 4 × 26 = 104배의 메모리를 더 씁니다. 다만 실제로는 65배 정도 차이가 났고 이 정도의 차이는 이진 검색 트리나 해시에 약간의 오버헤드가 있음을 감안해서 이해할 수 있습니다.
지금 이렇게 트라이에서 시간과 메모리가 느린 이유에 대해 설명한 부분이 잘 이해가 안가면 이유는 생각하지 말고 결론만 이해하셔도 됩니다. 트라이가 문자열의 삽입/탐색/삭제 등을 처리할 수 있는건 맞지만 정말 정직하게 문자열의 삽입/탐색/삭제만 있는 상황에서는 트라이 대신 이진 검색 트리나 해시를 쓰는게 낫습니다. 트라이는 구조의 특성상 메모리를 많이 차지하고 또 속도도 이론적인 시간복잡도와 별개로 좋지 않은 편입니다.
그런데 그렇다면 이렇게 속도도 구리고 메모리도 구린 트라이는 어떨 때 활용이 될 수 있는걸까요? 대표적인 활용 사례 중 하나가 자동 완성 기능입니다. 우리가 검색 엔진에서 키워드를 일부만 입력해도 그 값을 접두사로 가지는 여러 키워드의 목록을 실시간으로 확인할 수 있습니다. 가장 쉽게 떠올릴 수 있는 방법은 그냥 매번 사용자가 현재까지 입력한 키워드를 가지고 서버가 가지고 있는 키워드의 목록과 비교하는 방법이지만 이렇게 되면 속도가 상당히 느립니다. 이 기능을 효율적으로 구현해야 한다고 치면 미리 서버가 가지고 있는 키워드를 가지고 트라이를 만들어두고, 사용자가 무언가를 입력할 때 마다 트라이에서 정점을 타고 들어가면 더 효율적으로 구현할 수 있습니다. 실생활에서의 예시는 이렇고 알고리즘 문제에서의 쓰임새를 생각해보면 문제가 문자열과 관련이 있는데 특히 접두사나 접미사와 관련된 무언가를 요구할 경우 트라이가 쓰이지는 않을까 의심해볼 수 있습니다.

이번 강의에서 다룰 내용은 이게 전부입니다. 단순히 문자열을 삽입하고 찾는 상황에서는 앞에서 설명했듯 트라이가 그다지 유용하지 않기 때문에 오늘 내용이 이해할만했다면 실제로 알고리즘 문제에서 써먹을 수 있게 응용 문제까지 제대로 확인을 해보시는걸 추천드립니다. 만약 내용이 다소 어렵게 느껴졌다면 어차피 트라이 문제를 마주하더라도 풀어내기 힘들테니 그냥 코드는 제껴두고 개념만 이해하고 넘어가셔도 상관은 없습니다.
이렇게 바킹독의 실전 알고리즘 강의가 끝이 났습니다. 대학교 3학년 시절 처음 블로그에 강의를 올리며 혼자 뚝딱뚝딱 만들던걸 블로그 기준으로는 3년 8개월, 유튜브 기준으로는 2년 6개월이나 걸려서 마무리지을 수 있었네요. 그 사이 저는 대학도 졸업하고 석사도 졸업해서 척척석사가 되었습니다. 20대의 대충 1/3을 갈아넣은 결과물이라고 생각하니 참 말도 안되게 오래걸렸다 싶긴 하지만 제 본업이 있는 와중에도 틈틈히 열심히 만들었다는걸 이해해주시면 감사하겠습니다.
강의를 아껴주시고 또 만드는 동안 응원해주신 분들께 감사드립니다. 만약 이게 오프라인 강의였다면 쫑파티하면서 다같이 피자도 조지고 맥주도 조지고 했을텐데 온라인이라 아쉽네요. 아쉬운대로 제 메일로 피자 기프티콘 쏴주시면 맛있게 잘 먹겠습니다😊
마지막으로 이 강의를 완강한 이후로 어떤걸 하면 좋을지 방향성을 얘기해보겠습니다. 일단 코딩테스트를 기준으로 하면 이 강의 내용을 잘 따라왔을 때 떨어질래야 떨어질 수가 없습니다. 물론 제가 강의를 잘 만든 것도 있지만 응용 문제는 빼고 연습 문제와 체크된 기본 문제만 따져도 여러분이 푼 문제가 200문제가 넘습니다. 문제들을 제대로 안 풀고 그냥 진도 빼기에만 급급했거나 전부 다 풀이를 보고 대충 넘어간게 아니라면 강의를 듣기 전과 비교할 때 스스로 굉장히 실력이 많이 늘어있다는걸 느낄 수 있을 것 같습니다. 그렇긴한데 괜히 좀 찝찝해서 공부를 더 하고싶다면 문제집에 쌓여있는 수많은 문제들을 하나씩 풀기 전에 먼처 추천드릴게 있습니다. 문제집에 있는 문제를 풀 때에는 사실 굉장히 유리한 환경에서 생각을 해나갈 수 있었는데, 문제가 어떤 알고리즘을 요구하는지 알고 또 티어 표시를 켜두었다면 문제의 대략적인 난이도도 안 상태로 풀이를 고민할 수 있었습니다. 하지만 실전에서는 문제가 어떤 알고리즘을 필요로 하는지도, 대략적인 난이도도 알 수 없습니다. 그렇기 때문에 알고리즘 분류와 티어를 모른 채로 문제를 푸는 연습을 꼭 해보셔야 합니다. 제가 추천드리는건 우선 BOJ 설정에서 solved.ac 티어와 알고리즘 분류를 보이지 않게 설정한 후 대략 실버3에서 골드3 정도의 범위를 잡고 해당 범위의 문제 중에서 내가 아직 풀지 않은 문제를 맞힌 사람이 많은 순으로 하나씩 풀어보는겁니다. 이 때 실버3에서 골드3이라는 범위는 각자 상황에 맞게 더 낮추거나 높혀도 됩니다. 이런걸 랜덤 디펜스라고 부르기도 하는데, 이렇게 하나씩 해치우고 잘 떠오르지 않으면 풀이를 참고해보기도 하면서 풀어나가다보면 내가 약한 알고리즘이 무엇인지 감이 옵니다. 그 때 관련 단원의 내용을 복습하면서 해당 단원 문제집의 문제를 더 풀어보고 다시 랜덤 디펜스를 이어나가면 됩니다.
만약 코딩테스트를 넘어 대회를 노리시는 분이라면 랜덤 디펜스와 함께 문제집에 있는 응용 문제들을 많이 풀어보면서 사고의 폭을 넓혀보시고 동시에 세그먼트 트리, 기하, 라빈 카프 알고리즘, 유량 문제, SCC, BCC, 게임 이론 등 다양한 알고리즘을 하나씩 익혀나가면 됩니다. 이 알고리즘들은 그냥 방금 제가 생각나는대로 막 적은거라 이 순서대로 공부를 하라는 뜻은 아닙니다. 저는 공부를 할 때 따로 책을 본 적은 없고 검색을 하면서 블로그를 통해 지식을 습득했는데, 이건 순전히 제가 그랬다는 것 뿐이니 각자 책을 보거나 강의를 보거나 하는 식으로 자신에게 맞는 방법을 찾으시면 됩니다. 그리고 코드포스나 앳코더도 꼭 활발히 참여해보시는걸 추천드립니다.
사실 만들면서 제 알고리즘 강의를 뉴비 시절 저에게 전해줄 수 있었다면 참 좋았을텐데 하는 생각을 많이 합니다. 지금은 이렇게 남한테 알고리즘을 가르친다고 강의도 찍어올리곤 하지만 한때는 저도 sync_with_stdio랑 cin.tie 안써서 시간 초과 받고, multiset에서 erase 썼더니 원소가 다 지워져서 당황하고 뭐 그런 시절이 있었죠. 그렇게 빙글빙글 헤매던 경험을 잘 갈무리해서 제 강의로 배우실 분들은 스트레이트로 쭉 달릴 수 있게 강의를 열심히 만들었습니다. 코딩테스트 합격도 합격이지만 제 강의를 통해 ps 세계에 입문해서 대회에 수상하는 분이 나오면 정말 기쁠 것 같습니다. 그러면 긴 시간 고생 많으셨습니다. 다음에 또 인연이 닿는다면 다시 만납시다!
'강좌 > 실전 알고리즘' 카테고리의 다른 글
| [실전 알고리즘] 부록 B - 동적 배열 (13) | 2024.01.27 |
|---|---|
| [실전 알고리즘] 부록 A - 문자열 기초 (18) | 2023.05.03 |
| 향후 계획 (29) | 2022.09.11 |
| [실전 알고리즘] 0x1E강 - KMP (18) | 2022.08.02 |
| [실전 알고리즘] 0x1D강 - 다익스트라 알고리즘 (49) | 2022.02.19 |
| [실전 알고리즘] 0x1C강 - 플로이드 알고리즘 (13) | 2022.02.09 |